At the other end, even a single GTX 960 would make it onto the list, placing in the 200s.
Sure, you can say that deep learning doesn't need FP64, but it is REALLY unfair to compare this to anything on the TOP500 list, especially when you consider the fact that this is not balanced in terms of memory size or bandwidth (in relation to the number of FLOPs) when you compare it to any real supercomputer class system.
*http://www.anandtech.com/show/10222/nvidia-announces-tesla-p...
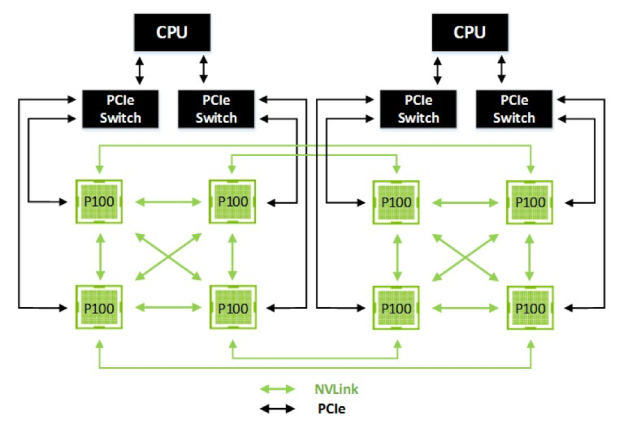
though I'm most curious about what motherboard is in there to support NVLink and NVHS.
Good overview of Pascal here: https://devblogs.nvidia.com/parallelforall/inside-pascal/
1 question: will we see NVLink become an open standard for use in/with other coprocessors?
1 gripe: they give relative performance data as compared to a CPU -- of course its faster than a CPU
3.2 KILOwatts sounded insane to me, but I suppose you'll have your own server rack to put it in if you can afford to buy one of these.
3.2KW is less than a dishwasher.
I'd love to show it to my father.
Couple that with the fact that they want you to use their compilers (extremely expensive), on a specialized system that can support the card, and you get a platform that nobody other than supercomputer companies can reasonably use. Meanwhile any developer who want to try something with cuda can drop $200 dollars on a GPU and go, then scale accordingly. I think intel somewhat acknowledged this by having a firesale on phi cards and dev licenses last year but it was only for a passively cooled model (really only works well in servers, not workstations).
Intel do this:
- Offer a $200-400 XEON PHI CARD
- Include whatever compiler needed to use it with the card
- Make this easily buyable
- Contribute ports of Cuda-based frameworks over to Xeon Phi
If you're AMD, do the same thing but replace the phrase Xeon Phi with Radeon/Firepro
The GP100/P100 with the 16nm process probably gives a considerable performance/power advantage over the Tesla... but this gives me the feeling that we may not see consumer or workstation-level Pascal boards for a while.
[1] https://aws.amazon.com/machine-learning/ [2] https://azure.microsoft.com/en-us/services/machine-learning/
Time to use better models like kernel ensembles, maybe they are not that accurate, but they are easier to train on a single CPU.
-unreformed box builder
(Of course, a better metric is that it's getting ~56x the performance at probably ~10x the TDP, but that's not surprising for a GPU with the current state of deep learning code.)
To their credit, the thermal and power engineering needed to get that dense a compute deployment is challenging. (bt, dt, have the corpses of power supplies to show for it.) But the price means that it's going to be limited to hyper-dense HPC deployments by companies that don't have the resources to engineer their own for substantially less money, such as Facebook's Big Sur design: https://code.facebook.com/posts/1687861518126048/facebook-to... . And, of course, the academics and hobbyists will continue to use consumer GPUs , which give much better performance/$ but aren't nearly as HPC-friendly.
What I was getting more at was: I want to know the relative performance compared to another 8 Tesla box. I know comparing apples isn't good marketing, but c'mon.
How much do you think it would really cost to develop an OpenCL equivalent of CuDNN (even a stripped down version, just fast)? I know AMD are struggling but we are talking about allocating a handful of talented engineers
Having C only wasn't a good idea. NVidia was quite clever in giving first class treatment to C++, Fortran and any compiler vendor that wished to target PTX.
Also the visual debugging tools are quite good.
Khronos apparently needed to be hit hard to realise that not everyone wants to be stuck with C for HPC in the 21st century.
Also although Apple is the creator of OpenCL, they don't seem to give much love to it.
Then you have Google caring about it's Renderscript dialect, which doesn't help to the overall uptake in OpenCL.
There isn't a monopoly, rather vendors that lacked the perception to appeal to the developers wanted to have as tooling and performance.
Anyone is free to go use OpenCL, use C or a language with a compiler with a C target, do printf debugging and feel free.
Are any vendors already doing SPIR support?
There's also Intel's MIC to consider now to, although that has a vastly different architecture to GPU. Again performance was similar between MIC and GPU in 2013[3], each performing better where their architecture was more suited, GPUs were capable of providing double the bandwidth for random access data.
In terms of AMD vs NVIDIA, I've not looked into it, I doubt AMD has anything to really compete with NVIDIAs current GPU accelerated compute lines. However again there was always that distinction (re bitcoin?) that AMD cards have better integer arithmetic and NVIDIA better float arithmetic.
Disclaimer: I use CUDA in my research, never tried OpenCL.
[1] http://arxiv.org/abs/1005.2581
[2] http://ieeexplore.ieee.org/xpl/login.jsp?tp=&arnumber=604719...
CUDA had Fortran and C++ since day one and thanks to PTX was quite easy to add support for other languages.
Whereas OpenCL was stuck on "C only" model from Khronos, which forced everyone to use C or generate C code and be constrained to the device drivers.
This has been seen as such a big issue that SPIR and C++ SPIR got introduced with OpenCL 2.0.
Another very important one is debugging support. Last time I checked no one had visual tooling at the same level as NVidia's one.
When I talk about balanced (which is a huge influence in my architectural and system level designs), I want to ideally be able to hit theoretical throughput. If we look at FP64 as an example, if I want to have sustained throughput of fused multiply adds (which is how NVIDIA always advertises their theoretical FLOP numbers as), I would be needing to move 196 data bits (three 64 bit floating point operands) in to each of my FPUs every cycle, and 64 bits out. 256 bits per cycle in a fully pipelined situation to be able to do 2 FLOPs/cycle. So if our ideal bandwidth is 16 Bytes for every 1 FLOP, if you have almost 10x more floating point capability than memory bandwidth, you are going to have a bad time (and GPUs very well reflect this on memory intensive workloads... take a look at GPUs on HPCG, they only get ~1-3% of their theoretical peak).
I'm working on my own HPC targeted chip, so obviously have some bias there, but 720GB/s memory bandwidth for a chip that is that large and using that much power isn't that impressive to me. Obviously I should wait to boast until I have my silicon in hand, but getting more than 3/4ths of that bandwidth in less than 1/10th of the power. Add in some fancy tricks and our goal is having our advertised theoretical numbers be pretty damn close to real application performance for memory intensive workloads.
It's a wast to put Xeon's on this things if they use the PCIe, you end up in a loot of cases only using them to drive the GPU's.
>When I talk about balanced (which is a huge influence in my architectural and system level designs)...
The DP performance on Tesla's is ridiculous, think it is a marketing ploy. People talk of buying gaming cards.., as you are almost always memory bound..
>I'm working on my own HPC targeted chip..
Looks nice, you are throwing out all HW bloat and doing everything in software? Are you planing to have some form of OS running on this chips?
Also, much of the speed gains for ML on NVidia hardware come from CuDNN - there is no equivalent for OpenCL or AMD hardware
AMD's Boltzmann initiative won't solve the lack of libraries.
https://www.daftlogic.com/information-appliance-power-consum...
You can cook in them as well: http://www.thekitchn.com/can-you-really-cook-salmon-in-a-dis...
It's like saying MATLAB has a monopoly in academic research because so much of the code is written in it. That is slowly changing and moving over to Python now, which is great. Maybe OpenCL will get there someday, but I don't see it happening any time soon.
I would love it if AMD would care more about GPGPU, but they don't, and NVIDIA has little incentive to make their OpenCl drivers equal to their CUDA ones.
Sounds like this is a significant cost savings if it fits your use case.
OK, so there's twice the power to pay for but it seems like at $129k acquisition cost per 3.2KW consumption you could run for tens of years before break-even.
{kind=link}
{kind=link}
{kind=link}
{kind=link}