Easy Scalable Text Rendering on the GPU(medium.com) |
Easy Scalable Text Rendering on the GPU(medium.com) |
I think that this was partially motivated by limitations in WebGL. More modern graphics APIs would allow better control over the render target (no need to hassle with RGBA8 using arithmetic tricks, just use integers if you need) and multisampling (gl_SampleMask for MSAA'd "discard" of fragments).
I was familiar with the Loop-Blinn stencil-then-cover trick (and I've worked with GPU path rendering before) but there were some interesting tidbits in this article regardless.
GPUs and all drivers do not support independent stencil buffer. If you need a stencil buffer, then you need to make a Depth=24, Stencil=8 buffer, also called D24S8.
If you have floating-point 32 bit depth format, sorry, no stencil buffers. If you don’t have depth at all, stencil buffer would take 4 times more VRAM: for color buffer, having just single component is fine, e.g. GL_R8UI or DXGI_FORMAT_R8_UINT.
Maybe there is a software patent he tries to avoid?
This is pretty similar to the point-in-poly raycasting (this is especially clear if you use the stencil buffer, but for some reason the author actively avoids that). You might also see some similarities with stencil shadow volumes (as seen in Doom 3).
There's two tricks used here: stencil-then-cover for the "bulk" of the shape and the Loop-Blinn method for doing quadratic Bezier curves in a triangle. You can find plenty of resources on both.
"The code is open source on GitHub in case it’s useful as a reference"
Thank you!
"it’s written in the Skew programming language"
:-(
Thankfully the shader code is in GLSL as you would expect/hope.
I would think that, compared to the LUT texture approach, this technique is lighter in FS load but more expensive in terms of fill rate/ROP.
[1]: http://wdobbie.com/post/gpu-text-rendering-with-vector-textu...
The approach you linked too is very well thought out but each font still does pixel processing for a bezier curve, which is many orders more expensive than a clip(). Never mind the addition of a dependent read via the LUT and the tracing step.
That's not necessarily what I'd expect, given that it's from Microsoft Research. I know they're a pretty independent bunch, but still, kudos.
[1] https://cdn-images-1.medium.com/max/1400/1*Uqt60m0luG2S8lm3h...
[2] https://cdn-images-1.medium.com/max/1400/1*VoJ6TfORiCHAHy3SN...
http://fsrv.dyndns.org/mirrors/dmedia-tutorials-textrenderin...
Make sure the image isn't scaled to see the text as sharp but with color fringe (on the left side of the image).
The image is from this other great article about sub-pixel font rendering: http://fsrv.dyndns.org/mirrors/dmedia-tutorials-textrenderin...
Note that this is a kludge [1].
[1] A Pixel Is Not A Little Square: http://alvyray.com/Memos/CG/Microsoft/6_pixel.pdf
1. Construct the underlying continuous field. This is just a function f(x,y) that returns one if the point is within the text and 0 otherwise.
2. Convolve f with an anti-aliasing filter. The filter could be tall and skinny to account for the fact that the horizontal resolution is 3x the vertical resolution.
3. Sample the resulting image at sub-pixel positions to produce the red, green, and blue values.
In the special case where the anti-aliasing filter is a box filter, this is exactly the same as computing the average for each subpixel. For the technique proposed in the article, the filter kernel would be the sum of six shifted impulses (Dirac deltas).
Anyways, I liked the article and wasn't trying to be critical of it. The convolution approach described above is of theoretical interest, but implementing it with any non-trivial kernel in real-time is almost certainly intractable. What I meant was that every implementation of anti-aliased vector graphics is a kludge, and it's pretty easy to coerce aliasing artifacts out of all of them using zone plates as inputs.
Edit: your article -> the article
If you want to get really fancy, you could base all your calculations on the precise region (with a kinda fuzzy boundary) where light is collected by a sensor pixel or emitted by a display pixel, but the advantage over pretending the pixel is a jinc function or whatever [cf. https://en.wikipedia.org/wiki/Sombrero_function] is going to be marginal.
WebGL is still based on GLES 2.0 and if you go by the book, you probably need to account for a 16 bit D16 depth buffer without a stencil present. That's probably not a very common case in practice (except old mobiles), though....
One other downside is this technique requires two drawcalls which can be pretty painful on some platforms.
Unless you really need large ranges of scale a glyph atlas based solution will probably be the fastest on a wide range of hardware.
I looked for the original Warnock paper online, but it is behind the ACM paywall. That would at least tell me if they knew of that in the mid 80's.
I will check out the Doom 3 stuff. I had that on my reading list from a while back.
Thanks for your answer.
The Doom 3 shadow volume algorithm is just the same, extended into 3d and using a little bit of depth buffer and front/back face culling to make some edge cases work (self-shadowing, shadow volume caps).
If you want to go read the original paper (please share a link!), you can circumvent the paywall with sci-hub.io if you don't mind a little piracy.
(And I'm not the author of the article.)
For example, look at the images in [1] (also a rather old paper). The box filter results (i.e. where the pixel value is set to the average of covered area) are less than ideal.
[1] Quadrature Prefiltering for High Quality Antialiasing: http://www.cs.northwestern.edu/~jet/Publications/quadfilt95....
Interestingly, both papers feature an aliased zone plate. :-)
They're pretty damn close, modulo the Bayer pattern for most sensors and RGB stripe arrangement for most displays. Calling an LCD's subpixels rectangles is certainly an approximation that's valid on the scale of the distance from one pixel to the next.
> [...] and treating them as such (whether for font rendering, photo capture, rendering line drawings, or any other purpose) is pretty much always worse than treating pixels as a discrete approximation of a continuous image.
Whether treating those pixels as rectangles or points is worse depends as much on the software/analytic approach you're using as on the physical reality of their rectangular geometry.
> Unfortunately 2D approximation is inherently more complex than 1D approximation, so you inevitably get some artifacts even when you do fancy computationally expensive math, and the choice is about which type of artifacts to privilege.
True, if you're unjustifiably constraining yourself to treating computer graphics only with the methods of a generic signal processing problem. Bresenham's algorithm is radically simpler than anything involving Bessel functions and also happens to work very well in the real world both in terms of speed and visual quality. Adding antialiasing to it leaves you with something that's still extremely simple and is easy to explain in terms of pixels. An exhortation to never treat pixels as little squares is just plain wrong.
[Unfortunately, even in the best case antialiased slightly diagonal straight lines look pretty shitty on a pixel display, regardless of what technique you use, up until you get to a pretty high resolution. Just an inherent issue with pixel grids.]
This paper is the overall most promising one I’ve seen in the field: http://w3.impa.br/~diego/projects/GanEtAl14/
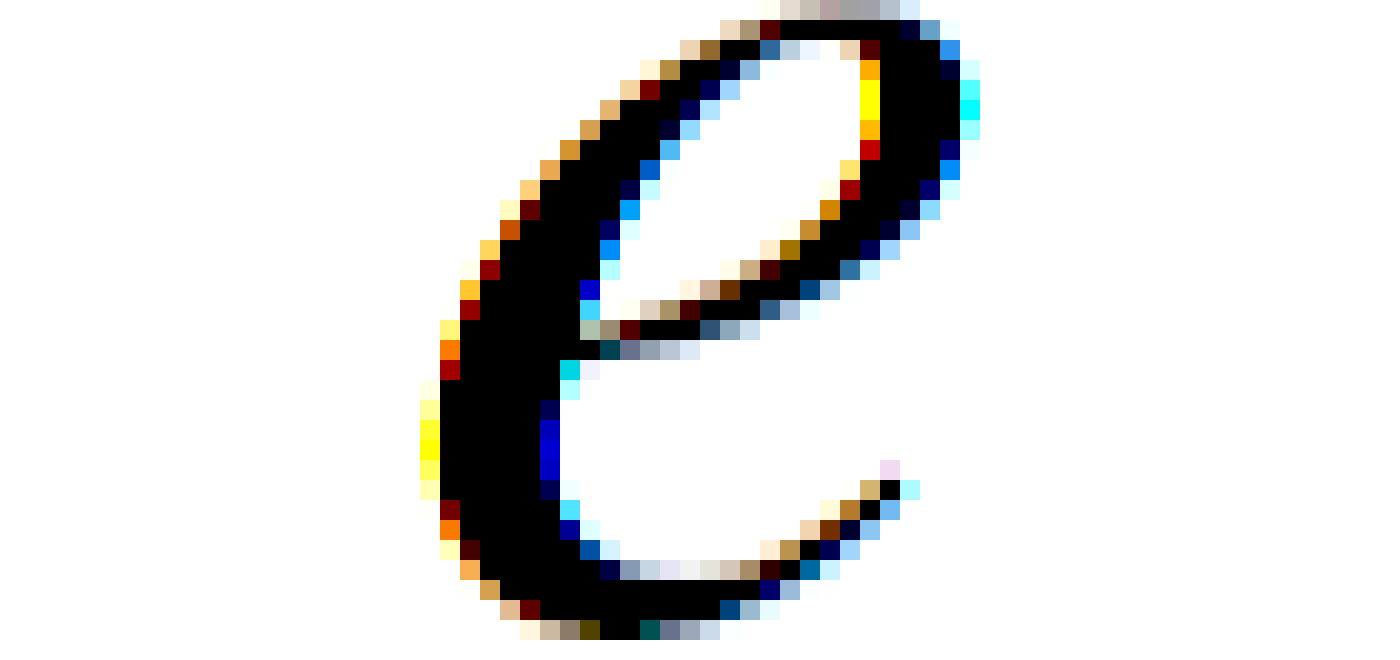{kind=link}
{kind=link}
{kind=link}