How the Windows Subsystem for Linux Redirects Syscalls(blogs.msdn.microsoft.com) |
How the Windows Subsystem for Linux Redirects Syscalls(blogs.msdn.microsoft.com) |
Curiosity got the best of me here: I had to look this up in the docs to see how a linux syscall that takes 3 parameters could possibly take 11 parameters. Spoiler alert: they are used for async callbacks, filtering by name, allowing only partial results, and the ability to progressively scan with repeated calls.
Side-by-side, comparing VMS to UNIX, and VMS's approach to a few key areas like I/O, ASTs and tiered interrupt levels are simply just more sophisticated. NT inherited all of that. It was fundamentally superior, as a kernel, to UNIX, from day 1.
I haven't met a single person that has understood NT and Linux/UNIX, and still thinks UNIX is superior as far as the kernels go. I have definitely alienated myself the more I've discovered that though, as it's such a wildly unpopular sentiment in open source land.
Cutler got a call from Gates in 89, and from 89-93, NT was built. He was 47 at the time, and was one of the lead developers of VMS, which was a rock-solid operating system.
In 93, Linus was 22, and starting "implementing enough syscalls until bash ran" as a fun project to work on.
Cutler despised the UNIX I/O model. "Getta byte getta byte getta byte byte byte." The I/O request packet approach to I/O (and tiered interrupts) is one of the key reasons behind NT's superiority. And once you've grok'd things like APCs and structured exception handling, signals just seem absolutely ghastly in comparison.
That does not follow from the example. All it shows is that Microsoft prefers to put a lot of functionality in one interface, while Linux probably prefers low-level functions to be as small as possible, and probably offers things like filtering on a higher level (in glibc, for example).
Neither explanation has anything to do with sophistication. I personally believe that small interfaces are a better design.
I'd also object NT kernel being more "powerful". Sure unixy kernels and NT has their differences but I don't think either one is superior.
Also, Windows development is infinitely more painful than Unix/Linux.
Are you implying that an increase in "power" can never be achieved through increasing simplicity?
Source?
It's not sophisticated enough or powerful enough to be the most used kernel on super computers (and in the world). Windows pretty much only dominates the desktop market. Servers, super computers, mainframes, etc, mostly use Linux.
A few years ago there was even a bug in Windows that caused degradation in network performance during multimedia playback that was directly connected with mechanisms employed by the Multimedia Class Scheduler Service (MMCSS), this is used on a lot of audio setups. If they can't even get audio setups right how can people consider anything Windows releases "sophisticated"?
It's made to do anything you throw at it I guess, it's definitely complicated, but powerful and sophisticated aren't words I would use to describe NT.
Is there a list of these syscalls somewhere? It would be cool to check it against the recent Linux API compatibility paper [0, 1].
[0]: http://oscar.cs.stonybrook.edu/api-compat-study/ [1]: http://www.oscar.cs.stonybrook.edu/papers/files/syspop16.pdf
A lot of coverage there, but interesting to see which ones aren't yet implemented, at least in the recent build 14342.
(I used Filippo Valsorda's work from https://filippo.io/linux-syscall-table as the Linux syscall data source.)
Not details on which one are fully or partly supported, though.
If I can't run the entire stack I use for dev under the subsystem then I will go the other route, which is to continue using VMs. I am excited about the initial release, and the prospect of being able to use Windows for all of the regular things I do, but it's clear that this isn't ready for primetime even as a dev tool.
Say what? The NT kernel doesn't restore caller-saved registers at syscall exit? This seems extraordinary, because unless it either restores them or zaps them then it will be in danger of leaking internal kernel values to userspace - and if it zaps them then it might as well save and restore them, so userspace won't need to.
Frame struct ReturnAddress dq ? HomeRcx dq ? HomeRdx dq ? HomeR8 dq ? HomeR9 dq ? Frame ends
NESTED_ENTRY Foo, _TEXT$00
mov Frame.HomeRcx[rsp], rcx
mov Frame.HomeRdx[rsp], rcd
mov Frame.HomeR8[rsp], r8
mov Frame.HomeR9[rsp], r9
alloc_stack 64
END_PROLOG
; *do stuff*
BEGIN_EPILOG
add rsp, 64
NESTED_END Foo, _TEXT$00
What about applications that hook to X Windows or do things like opening the frame buffer device. I've got a messaging application that can be compiled for both Windows and Linux and depending on the OS, I compile a different transport layer. Under Linux heavy use of epoll is used which is very different than how NT handles Async I/O - especially with sockets. So my application's "transport driver" is either compiling an NT code base using WinSock & OVERLAPPED IO or a Linux code base using EPOLL and pthreads.
Over all it seems like a nice to have but I'm struggling to extract any real benefit.
Can anyone offer up some real good use cases I may be overlooking?
[1] http://www.pcworld.com/article/3038652/windows/microsoft-kil... [2] https://developer.microsoft.com/en-us/windows/bridges/ios
Edit: Now I am puzzled as to why this got downvoted?
https://www.kernel.org/doc/Documentation/virtual/kvm/nested-...
https://msdn.microsoft.com/en-us/virtualization/hyperv_on_wi...
[1] https://www.vmware.com/pdf/asplos235_adams.pdf
[2] https://en.wikipedia.org/wiki/Popek_and_Goldberg_virtualizat...
It is quite interesting to see mainstream OSes increasingly get adopting all those features.
Emphasis is mine. I wonder if this is something that cygwin could (ab)use. Also I wonder why they would need this undocumented call.
[1] https://cygwin.com/ml/cygwin-developers/2011-04/msg00036.htm...
To implement the first NT Posix subsystem, which was a FIPS requirement.
You can do it with NtCreateProcess: https://groups.google.com/d/msg/microsoft.public.win32.progr...
(The Win32 userland won't understand what you did, but you can still do it.)
The very precise mechanism, though, is extremely unstable. For example virtually every release of Windows (even sometimes SP) changes the syscall numbers. You have to go through the ntdll, which is kind of a more heavyweight version of the Linux VDSO. (The NTDLL approach was invented way before the VDSO, though)
They should probably just buy Canonical. That would put the shivers into Google, properly.
Microsoft should take the Windows GUI and put it over Linux as a desktop manager. Microsoft could sell the Windows GUI for Linux users that want to run Windows apps.
I wish Windows/MS would abandon NT and just create a Linux distro. I don't know anyone who particularly likes NT and jamming multiple systems together seems like an awful idea.
Windows services and Linux services likely won't play nice together (think long file paths created by Linux services and other incompatibilities), for them to be 100% backward compatible they need to not only make Windows compatible with the things Linux outputs, but Linux compatible with the things windows services output, and to keep the Linux people from figuring out how to use Windows on Linux systems they'd need to make a lot of what they do closed source.
So I don't see a Linux+Windows setup being deployed for production. It's cool for developers, but even then you can't do much real world stuff that utilizes both windows and Linux. If you're only taking advantage of one system then whats the point of having two?
I went ahead and made the switch to Linux since I was trying to make Windows behave just like Linux.
Why run a Linux Application/binary on a windows server OS? When you can just run it on Linux OS and get better performance & stability.
Curious why you claim this? What's outdated about the NT Kernel?
I do. The NT kernel is pretty clean and well architected. (Yes, there are mistakes and cruft in it, but Unix has that in spades.) It's not "jamming multiple systems together"; an explicit design goal of the NT kernel was to support multiple userland APIs in a unified manner. Darwin is a much better example of a messy kernel, with Mach and FreeBSD mashed together in a way that neither was designed for.
It's the Win32 API that is the real mess. Having a better officially supported API to talk to the NT kernel can only be a good thing, from my point of view.
Still considering the whole system, an instable user kernel interface has few advantages and tons of drawbacks. MS is extremely late to the chroot and then container party because of that (and let's remember that the core technology behind WSL emerged because they wanted to solve the chroot aside userspace system on their OS in the first place, NOT because they wanted to run Linux binaries) -- so yet another point why classic NT subsystems are useless.
Back to core kernel stuff, IRQL model is shit. Does not make any sense when you consider what really happens, and you can't really use arbitrary multiple levels. It seems cute and clean and all of that, but Linux approach of top and bottom halves and kernel and user threads might seem messy but is actually far more usable. Another point: now everybody uses multiprocessor computers, but back in the day the multiple HAL were also a false good idea. MS recognize it now and only want to handle ACPI computers, even on ARM. Other OSes do all kind of computers... Cutler pretended to not like the "everything is a file" approach, but NT does basically the same thing with "everything is a handle". And soon enough, you hit exactly the same conceptual limitations (except not in the same places) that not everything is actually the same, so that cute abstraction leaks soon enough (well, it does in any OS).
On a more result oriented approach, one of the things WSL makes clear is that file operations are very slow (just compare an exactly identical file heavy workload under WSL and then under a real Linux)
So of course there are (probably) some good parts, like in any mainstream kernel, but there are also some quite dark corners, and I am not an expert about all architectural design of NT but I'm not a fan of the parts I know, and I strongly prefer the Linux way to do equivalent things.
That's particular interesting now that SQL Server has been ported to Linux. Would be funny if they're going to use the Linux subsystem on Windows too.
Although I suspect SQL Server already talks to the kernel directly.
This is what I am looking forward to with WinRT, hence why Rust should make it as easy as C++/CX and C# to use those APIs. :)
An old HN commenter once wrote (mrb)
> There is not much discussion about Windows internals, not only because they are not shared, but also because quite frankly the Windows kernel evolves slower than the Linux kernel in terms of new algorithms implemented. For example it is almost certain that Microsoft never tested I/O schedulers, process schedulers, filesystem optimizations, TCP/IP stack tweaks for wireless networks, etc, as much as the Linux community did. One can tell just by seeing the sheer amount of intense competition and interest amongst Linux kernel developers to research all these areas.
>The net result of that is a generally acknowledged fact that Windows is slower than Linux when running complex workloads that push network/disk/cpu scheduling to its limit: https://news.ycombinator.com/item?id=3368771 A really concrete and technical example is the network throughput in Windows Vista which is degraded when playing audio! https://blogs.technet.microsoft.com/markrussinovich/2007/08/...
>Note: my post may sound I am freely bashing Windows, but I am not. This is the cold hard truth. Countless of multi-platform developers will attest to this, me included. I can't even remember the number of times I have written a multi-platform program in C or Java that always runs slower on Windows than on Linux, across dozens of different versions of Windows and Linux. The last time I troubleshooted a Windows performance issue, I found out it was the MFT of an NTFS filesystem was being fragmented; this to say I am generally regarded as the one guy in the company who can troubleshoot any issue, yet I acknowledge I can almost never get Windows to perform as good as, or better than Linux, when there is a performance discrepancy in the first place.
"Russia Factory for England" most likely exists inside of Russia and is for the English.
"John's mail for Sally [try: who is out of town]" even with the addition, I presume that John has authored mail for Sally and is not collecting the parcels to give to her.
Here's a trickier one:
"Sampsons' Dinner for Two". This could be the following:
1. A product named "Sampsons' Dinner for Two" bought from a retail store
2. An item "Dinner for Two" on a menu from a restaurant named "Sampsons"
3. A place named "Sampsons' Dinner for Two" with only two-person tables.
4. A product "Sampsons' Dinner" which comes in multiple sizes, one of them being designed for two people. (which is the ambiguous form - presuming there's also say Annie's Dinner for One/Two and Martha's Dinner for One/Two - each with a brand specific cuisine). Even here though, the ownership of which "Dinner for Two" product is still clear - it's the "Sampsons'" or "Martha's" brand.
Regardless of what kind of substitution, we go back to "Windows Subsystem for Linux" for the most part parsing as
"Windows [Subsystem for Linux]" like "Windows [Media Player]". I don't assume that it's "[Windows Media] Player" - as in some multi-platform software that is tasked with playing the proprietary windows media formats.
It seems weird, but I think it's unarguably the right choice.
This would be really useful for distributing Windows apps as Linux binaries. It would make it easier to develop from Linux and target Windows. Need the same for OSX.
Usage of the adjective "sophisticated" always precedes an outpouring either ignorance or straight bs.
dup->dup2->dup3 pipe->piep2 rename->renameat->renameat2
Best practice nowadays in linux is to allow overloading syscalls via a flags parameter.
see https://lwn.net/Articles/585415/
So modern linux syscalls may be bloated too.
It's similar to the various knobs in Linux /proc which require reading and writing specially formatted data. ioctl is simpler in that you don't need to worry as much about formatting the data (the struct declarations take care of that for you), but a file-oriented interface is nicer in that it's a higher-level abstraction--for example, it maps better to different languages, similar to how ioctl requires C or C-like shims whereas /proc can be used from any language that understands open/read/write/close, including the shell.
The approach is a little different though; ntdll exports all of the NT API, and you need to go through it to reach the NT API in a somehow more stable way than using syscall numbers. OTOH, the VDSO exports only virtual syscalls that gain (or have gained in the past) from being performed in userspace, and even then corresponding syscalls still exist in the kernel, with both stable numbers and even a stable API.
Unix is bristling with features designed to "allow you to save me some time". It was designed to make it easy to write quick, "one-off" programs in C. VMS -- the predecessor to Windows NT -- was designed to run long-lasting, high-performance, high-reliability business applications for real users with money on the line (i.e., not just hackers) and Windows NT inherits this legacy.
OK, so it just so happens this is what I love to do. I like writing small programs and continually trying to improve them.
So I guess I should be a UNIX user?
Is NT not good for this too?
BTW, I do like VMS. But despite the NT kernel, using NT feels nothing like using VMS.
The I/O model that Windows supports is a strict superset of the Unix I/O model. Windows supports true async I/O, allowing process to start I/O operations and wait on an object like an I/O completion port for them to complete. Multiple threads can share a completion port, allowing for useful allocation of thread pools instead of thread-per-request.
In Unix all I/O is synchronous; asynchronicity must be faked by setting O_NONBLOCK and buzzing in a select loop, interleaving bits of I/O with other processing. It adds complexity to code to simulate what Windows gives you for real, for free. And sometimes it breaks down; if I/O is hung on a device the kernel considers "fast" like a disk, that process is hosed until the operation completes or errors out.
Yes, it's true that many APIs would theoretically allow kernel-level asynchronous I/O, but in practice the story is not so rosy.
* Asynchronous disk I/O is in practice often not actually asynchronous. Some of these cases are documented (https://support.microsoft.com/en-us/kb/156932), but asychronous I/O also actually blocks in cases that are not listed in that article (unless the disk cache is disabled). This is the reason that node.js always uses threads for file i/o.
* For sockets, the downside of the 'completion' model that windows is that the user must pre-allocate a buffer for every socket that it wants to receive data on. Open 10k sockets and allocate a 64k receive buffer for all of them - that adds up quickly. The unix epoll/kqueue/select model is much more memory-efficient.
* Many APIs may support asynchronous operation, but there are blatant omissions too. Try opening a file without blocking, or reading keyboard input.
* Windows has many different notification mechanisms, but none of them are both scalable and work for all types of events. You can use completion ports for files and sockets (the only scalable mechanism), but you need to use events for other stuff (waiting for a process to exit), and a completely different API to retrieve GUI events. That said, unix uses signals in some cases which are also near impossible to get right.
* Windows is overly modal. You can't use asynchronous operations on files that are open in synchronous mode or vice versa. That mode is fixed when the file/pipe/socket is created and can't be changed after the fact. So good luck if a parent process passes you a synchronous pipe for stdout - you must special case for all possible combinations.
* Not to mention that there aren't simple 'read' and 'write' operations that work on different types of I/O streams. Be ready to ReadFileEx(), Recv(), ReadConsoleInput() and whatnot.
IMO the Windows designers got the general idea to support asynchronous I/O right, but they completely messed up all the details.
> * Asynchronous disk I/O is in practice often not actually asynchronous. Some of these cases are documented (https://support.microsoft.com/en-us/kb/156932), but asychronous I/O also actually blocks in cases that are not listed in that article (unless the disk cache is disabled). This is the reason that node.js always uses threads for file i/o.
The key to NT asynchronous I/O is understanding that the cache manager, memory manager and file system drivers all work in harmony to allow a ReadFile() request to either immediately return the data if it is available in the cache, and if not, indicate to the caller that an overlapped operation has been started.
Things like extending a file, opening a file, that's not typically hot-path stuff. If you're doing a network oriented socket server, you would submit such a blocking operation to a separate thread pool (I set up separate thread pools for wait events, separate to the normal I/O completion thread pools), and then that I/O thread moves on to the next completion packet in its queue.
> * For sockets, the downside of the 'completion' model that windows is that the user must pre-allocate a buffer for every socket that it wants to receive data on. Open 10k sockets and allocate a 64k receive buffer for all of them - that adds up quickly. The unix epoll/kqueue/select model is much more memory-efficient.
Well that's just flat out wrong. You can set your socket buffer size as large or as small as you want. For PyParallel I don't even use an outgoing send buffer.
Also, the new registered I/O model in 8+ is a much better way to handle socket buffers without the constant memcpy'ing between kernel and user space.
> IMO the Windows designers got the general idea to support asynchronous I/O right, but they completely messed up all the details.
I disagree. Write a kernel driver on Linux and NT and you'll see how much more superior the NT I/O subsystem is.
I'm guessing you're coming from the opposite position of ignorance I am (i.e. you've worked on Windows, but not Linux or other modern UNIX), though, since "setting O_NONBLOCK and buzzing in a select loop, interleaving bits of I/O with other processing" doesn't describe anything developed in many, many years. 15 years ago select was already considered ancient.
Windows will also take care of managing a thread pool to handle the event completion callbacks by means of BindIoCompletionCallback [4]. I don't think kqueue or Event Ports has a similar facility.
[1]: https://msdn.microsoft.com/en-us/library/windows/desktop/aa3... [2]: https://www.freebsd.org/cgi/man.cgi?query=kqueue&sektion=2 [3]: https://illumos.org/man/3C/port_create [4]: https://msdn.microsoft.com/en-us/library/windows/desktop/aa3...
> The “Why Windows?” (or “Why not Linux?”) question is one I get asked the most, but it’s also the one I find hardest to answer succinctly without eventually delving into really low-level kernel implementation details. >
> You could port PyParallel to Linux or OS X -- there are two parts to the work I’ve done: a) the changes to the CPython interpreter to facilitate simultaneous multithreading (platform agnostic), and b) the pairing of those changes with Windows kernel primitives that provide completion-oriented thread-agnostic high performance I/O. That part is obviously very tied to Windows currently. >
> So if you were to port it to POSIX, you’d need to implement all the scaffolding Windows gives you at the kernel level in user space. (OS X Grand Central Dispatch was definitely a step in the right direction.) So you’d have to manage your threadpools yourself, and each thread would have to have its own epoll/kqueue event loop. The problem with adding a file descriptor to a per-thread event loop’s epoll/kqueue set is that it’s just not optimal if you want to continually ensure you’re saturating your hardware (either CPU cores or I/O). You need to be able to disassociate the work from the worker. The work is the invocation of the data_received() callback, the worker is whatever thread is available at the time the data is received. As soon as you’ve bound a file descriptor to a per-thread set, you prevent thread migration >
> Then there’s the whole blocking file I/O issue on UNIX. As soon as you issue a blocking file I/O call on one of those threads, you have one thread less doing useful work, which means you’re increasing the time before any other file descriptors associated with that thread’s multiplex set can be served, which adversely affects latency. And if you’re using the threads == ncpu pattern, you’re going to have idle CPU cycles because, say, only 6 out of your 8 threads are in a runnable state. So, what’s the answer? Create 16 threads? 32? The problem with that is you’re going to end up over-scheduling threads to available cores, which results in context switching, which is less optimal than having one (and only one) runnable thread per core. I spend some time discussing that in detail here: https://speakerdeck.com/trent/parallelism-and-concurrency-wi.... (The best example of how that manifests as an issue in real life is `make –jN world` -- where N is some magic number derived from experimentation, usually around ncpu X 2. Too low, you’ll have idle CPUs at some point, too high and the CPU is spending time doing work that isn’t directly useful. There’s no way to say `make –j[just-do-whatever-you-need-to-do-to-either-saturate-my-I/O-channels-or-CPU-cores-or-both]`.) >
> Alternatively, you’d have to rely on AIO on POSIX for all of your file I/O. I mean, that’s basically how Oracle does it on UNIX – shared memory, lots of forked processes, and “AIO” direct-write threads (bypassing the filesystem cache – the complexities of which have thwarted previous attempts on Linux to implement non-blocking file I/O). But we’re talking about a highly concurrent network server here… so you’d have to implement userspace glue to synchronize the dispatching of asynchronous file I/O and the per-thread non-blocking socket epoll/kqueue event loops… just… ugh. Sure, it’s all possible, but imagine the complexity and portability issues, and how much testing infrastructure you’d need to have. It makes sense for Oracle, but it’s not feasible for a single open source project. The biggest issue in my mind is that the whole thing just feels like forcing a square peg through a round hole… the UNIX readiness file descriptor I/O model just isn’t well suited to this sort of problem if you want to optimally exploit your underlying hardware. >
> Now, with Windows, it’s a completely different situation. The whole kernel is architected around the notion of I/O completion and waitable events, not “file descriptor readiness”. This seems subtle but it pervades every single aspect of the system. The cache manager is tightly linked to the memory management and I/O manager – once you factor in asynchronous I/O this becomes incredibly important because of the way you need to handle memory locking for the duration of the I/O request and the conditions for synchronously serving data from the cache manager versus reading it from disk. The waitable events aspect is important too – there’s not really an analog on UNIX. Then there’s the notion of APCs instead of signals which again, are fundamentally different paradigms. The digger you deep the more you appreciate the complexity of what Windows is doing under the hood. >
> What was fantastic about Vista+ is that they tied all of these excellent primitives together via the new threadpool APIs, such that you don’t need to worry about creating your own threads at any point. You just submit things to the threadpool – waitable events, I/O or timers – and provide a C callback that you want to be called when the thing has completed, and Windows takes care of everything else. I don’t need to continually check epoll/kqueue sets for file descriptor readiness, I don’t need to have signal handlers to intercept AIO or timers, I don’t need to offload I/O to specific I/O threads… it’s all taken care of, and done in such a way that will efficiently use your underlying hardware (cores and I/O bandwidth), thanks to the thread-agnosticism of Windows I/O model (which separates the work from the worker). >
> Is there something simple that could be added to Linux to get a quick win? Or would it require architecting the entire kernel? Is there an element of convergent evolution, where the right solution to this problem is the NT/VMS architecture, or is there some other way of solving it? I’m too far down the Windows path now to answer that without bias. The next 10 years are going to be interesting, though.
https://groups.google.com/forum/#!topic/framework-benchmarks...
Further information: https://www.fsl.cs.sunysb.edu/~vass/linux-aio.txt
Because that is like pulling teeth on UNIX. See: https://groups.google.com/forum/#!topic/framework-benchmarks...
Explain? Pretty much the only thing you can do with a handle is to release it. That's very different from a file, which you can read, write, delete, modify, add metadata to, etc... handles aren't even an abstraction over anything, they're just a resource management mechanism.
So the naming distinction is quite arbitrary.
Uh, no, they are very crucial details. For example, it means the difference between letting root delete /dev/null like any other "file" on Linux, versus an admin not being able to delete \Device\Null on Windows because it isn't a "file". The nonsense Linux lets you do because it treats everything like a "file" is the problem here. It's not a naming issue.
On the contrary. It's only when one considers what happens, especially in the local APIC world as opposed to the old 8259 world, that what the model is actually does finally make sense.
* http://homepage.ntlworld.com./jonathan.deboynepollard/FGA/ir...
IRQL is a completely software abstraction thing, in the same way top/bottom halves and various threads are under Linux (hey, in some version of the Linux kernel it even transparently switches to threaded IRQ for the handlers, there is no close relationship with any interrupt controller at this point...). IRQL is shit because most of the arbitrary levels it provides are not usable to distinguish anything continuously from an application point of view (application in the historical meaning, no "App" bullshit intended here), even so in seemingly continuous areas (DIRQL), so there is no value in providing so many levels with nothing really distinguishing between them -- or at some level transitions too many things completely different. It's even highly misleading, to the point the article you link is needed (but does not even provide the whole picture.) I see potential for misleading people with PIC knowledge, people used to real time OSes (if you try to organize application priority by basing on IRQL, you will miserably fail), people with background in other kernels, well, pretty much everybody.
I would go so far as to say that a large part of why audio is such a CF under Linux is -- wait for it -- lack of real asynchronous I/O.
Audio is asynchronous by nature, and to do that right under Linux you need a "sound server" with all the additional overhead, jank, and shuffling of data between kernel and at least two different user spaces that implies. Audio under Linux was best with OSS, which was synchronous in nature and not suitable for professional applications. JACK mitigated that somewhat, but for an OS to do audio right you need a kernel-level async audio API like Core Audio or whatever Windows is doing these days.
I use Linux regularly to record and edit audio, it's free , it works, and I dont have to worry my OS is active reducing the functionality of my equipment.
11 param functions don't say "power" to me. They say "poorly thought out API design". Much can be said for most Windows APIs in general.
Dave Cutler's skills aside, Unix predates Windows by decades, and to anyone remotely familiar with kernel development it is clear that the sheer quantity and complexity of subsystems stem from the fact that nobody but Microsoft can actually see, modify, and redistribute Windows' source code.
Unless you can actually say "here's why Windows is qualitatively better" and point out specific tasks Windows does better, I'll just point you to the fact that the internet infrastructure and most of the servers on it, along with every Apple desktop and pretty much every mobile device, run Unix.
I wonder how much of the internet infrastructure would run Unix if free (as in beer) clones like *BSD and GNU/Linux did not exist in first place.
How much internet infrastructure would run actually Unix if ISPs had to choose between Aix, HP-UX, Solaris, Digital UX, Tru64 and Windows licenses?
Free is always more valued than quality.
And of course this worked in reverse, when Netscape released their commercial webserver Microsoft rushed to give away IIS.
Also, on an high performance poll/epoll/kevent based system you only need to poll cold fds, while you can do speculative direct read/writes to hot fds, so no need for extra syscalls in the fast case.
That doesn't mean that completion notification doesn't have its advantages, especially when coupled with NT builtin auto-sizing thread pool, but it is not strictly better.
(FYI, I've read the "internals" book for a relatively old version of Windows, along with plenty of books about attacking the Windows kernel through its huge attack surface that exists to accommodate various needs of various software vendors...)
Now at one point, way in the past, NT was far above Linux, and some Linux fanboys existed that did not even knew what they were talking about, yet had strong opinions of superiority about the kernel they used. Now we are ironically in the opposite situation: Linux has basically caught up on all the things that matters (preemptive kernel, stability, versatility, scalability) and then quickly overtook NT, yet some people like to talk endlessly about the supposed architectural superiority of NT, that did not provide anything concrete in the real world in the long term and widely used, and that MS had to work around and/or redo with an other approach (while keeping vestigial of all the old ones) to do all its modern stuff.
What kernel hackers know to do, is to detect problem in architecture that look neat on paper. Brillant ones are able to anticipate. I don't even have to: history has shown were NT has been hold back by its original design.
It follows the same line of narrative as The Soul of a New Machine
[1] https://www.amazon.com/Showstopper-Breakneck-Windows-Generat...
The author also e-mailed me saying thanks when I tweeted him how much I liked the book, which I thought was super nice.
I know there are lots of file descriptors not usable with epoll or rather async i/o in general and that sucks (e.g. regular files).
For networking, I find epoll/sockets nicer to work with than Windows' IOCP, because with IOCP you need to keep your buffers around until the kernel deems your operation complete. I think you have 3 options:
1) Design the whole application to manage buffers like IOCP likes (this propagates to client code because now e.g. they need to have their ring buffer reference-counted).
2) You handle it transparently in the socket wrapper code by using an intermediate buffer and expose a simple read()/write() interface which doesn't require the user to keep a buffer around when they don't want the socket anymore.
3) You handle it by synchronously waiting for I/O to be cancelled after using CancelIo. This sounds risky with potential to lock up the application for an unknown amount of time. It's also non-trivial because in that time IOCP will give you completion results for unrelated I/Os which you will need to buffer and process later.
On the other hand, with Linux such issues don't exist by design, because data is only ever copied in read/write calls which return immediately (in non-blocking mode).
In Linux, you don't, and userspace and kernelspace both end up doing unnecessary copying, and it means with shared buffers, something might poll and not-block, but actually block by the time you get around to using the buffer.
This is annoying, and it generally means you need more than two system calls on average for every IO operation in performance servers.
As a rule, you can generally detect "design faults" by the number of competing and overlapping designs (select, poll, epoll, kevent, /dev/poll, aio, sigio, etc, etc, etc). I personally would have preferred a more fleshed out SIGIO model, but we got what we got...
One specific fault of epoll (compared to near-relatives) is that the epoll_data_t is very small. In Kqueue you can store both the file descriptor with activity (ident) as well as a few bytes of user data. As a result, people use a heap pointer which causes an extra stall to memory. Memory is so slow...
Solaris event ports are good, but they're still ultimately backed by a readiness-oriented I/O model, and can't be used for asynchronous file I/O.
https://blogs.oracle.com/dap/entry/libevent_and_solaris_even...
https://blogs.oracle.com/praks/entry/file_events_notificatio...
And Solaris, (unlike Linux historically at least), supports async I/O on both files and sockets. Linux (historically) only supported it for sockets. I have no idea if Linux generally supports async I/O for files at this point.
http://www.visualcomplexity.com/vc/project.cfm?id=392
Are you saying the Windows flow looks like spaghetti only because the software tested software (Apache) wasn't designed for Windows?
Also do you have an opinion on BeOS?
NT solves it properly. Efficient multithreading support and I/O (especially asynchronous I/O) are just so intrinsically related. Trying to bend UNIX processes and IPC and signals and synchronous I/O into an efficient threading implementation is just trying to fit a square peg in a round hole in my opinion.
As for reading list... I've bought so many old books lately. Here's my "makes the short list" bookshelf: http://imgur.com/DfTUVQx
And the more ridiculous one that I use as a cover page on my resume: http://imgur.com/0u9OZcN
What things in particular are you interested in?
Thanks for the answer. I guess what I'm interested is somewhat obscure/historical operating systems and also HW that are in some way superior to currently popular solutions. The more comparative the better.
Also your reading list has quite a few Oracle SQL entries so I'm guessing it's your preferred DB of choice. What features are you using that aren't available in MySQL or Postgres?
You can do dual synchronous/asynchronous socket I/O in Windows. I use this very approach with PyParallel (and 0 byte send buffers): https://github.com/pyparallel/pyparallel/blob/branches/3.3-p...
Depending on current load, that will either immediately do an asynchronous operation, or attempt synchronous non-blocking ones up to a certain number, then fall back to asynchronous.
Described here: https://speakerdeck.com/trent/pyparallel-how-we-removed-the-...
Regarding the differences between IOCP and epoll/kqueue, it all comes down to completion-oriented versus readiness-oriented.
https://speakerdeck.com/trent/pyparallel-how-we-removed-the-...
IMO one of the biggest problems with the old API is that there is only one pool. This can cause crazy deadlocks due to dependencies between work items executing in the pool. The new API allows you to create isolated pools.
The old API did not give you the ability to "join" on its work items before shutting down. You could roll your own solution if you knew what you were doing, but more naive developers would get burned.
You also get much finer grained control over resources.
I really sympathize with Len Holgate though... he's had to nurse Server Framework through all of that transition, which must have been painful: http://www.serverframework.com/asynchronousevents/2016/06/an...
False. You ASSUMED facts based on co-relation - "Its used everywhere" doesn't mean anything. "But people must have a reason to use them" STILL doesn't mean anything. "Well, so why don't they use windows" STILL doesn't get you anywhere.
> I could be entirely illiterate and my argument would still hold because it's based on fact.
No. You can't enter into an argument when you know nothing about the subject. That is not how it works.
Why don't YOU present actual facts about the design? Show us you actually understand the internals of the kernel or have atleast some rudimentary knowledge. Otherwise you'd just be wasting everyone's time.
This is because Linux's server workload is mainly the Web. But every departmental office needs an Exchange server...
2. `mklink` [0] has existed since Windows Vista for NTFS file system. No settings toggling required.
3. What is your argument against PowerShell? In what ways does it fall short? I have been pretty successful with using it for various tasks.
4. This is about the only legit claim. Windows always requires full credentials to execute as another user. Windows does provide `runas.exe`, but you must provide the target user's full credentials.
[0] https://technet.microsoft.com/en-us/library/cc753194%28v=ws....
There are several limitations in the Windows/NTFS implementation, however:
1. You have to specify the target type (file or directory) at link creation time.
2. Creating symbolic links requires either being an Administrator user, or having the "Create symbolic links" group policy enabled for your account.
3. No real directory hard links. (EDIT: For some reason, I forgot that Linux doesn't have these, either. Maybe I was thinking of bind mounts.)
Windows isn't the only OS that disallows creating directory hard links.
http://askubuntu.com/questions/210741/why-are-hard-links-not...
Powershell is an acceptable scripting language. It's a horrible interactive shell. They shoudn't have made "shell" part of its name if they weren't going to at least include basic interactive features like readline compatibility and usable tab completion.
My experience with tab completion in PowerShell is great. It completes file paths, command names, command parameter names, and even command parameter values if they're an enumeration. Could you describe what else you would expect to see?
I would call it something more than acceptable scripting language. It is object oriented and it can easily use C# libraries, which is pretty neat.
b) http://mridgers.github.io/clink/ is bloody fantastic.
NT has a root directory like Unix does. Drive letters are symbolic links inside a directory called \DosDevices.
Granted, this is not user-visible but an implementation detail. The needs of Win32 applications dictate a lot of user-visible behavior.
> 2. Creating symbolic links to files and folders,
NT supports symbolic links. Open cmd and type "mklink".
The shell itself and the rest of userland has very little to do with the kernel. It seems its the userland you are upset with. Swapping out the kernel won't fix that.
You can create hard and soft links. PowerShell is great, just different. UAC is not sudo, but works very well. It's a different OS.
For some values of well. If you logon interactively and start a powershell session, you do not have administrative powers and cannot get them without opening a new shell. If you logon via PS remoting, you have administrative powers by default and cannot lose them.
UAC is a GUI kludge, and is very grating especially in Powershell.
This is probably the number one cause of me banging my head against the desk and wishing Windows behaved more like Linux.
OTOH there are other limits that are not dictated by dwShareMode. Such as deleting files while handles are open - this blocks a new file with the same name from being created until all handles are closed. That's probably the worst one. There are some other crappy ones involving directory handles that I don't care to enumerate.
It's neither. It's a common misconception. See https://news.ycombinator.com/item?id=11415366 .
Windows isn't the only OS having file locking implemented at kernel level.
> 1. The use of drive letters A-Z for file system access.
Indeed it is not. The kernel sees a single root for the object namespace, not drive letters.
3. Userland issue. You can compile bash and an ssh server for Windows if you want. PowerShell is quite different, yes.
4. exists, both in GUI and commandline.
Symbolic links is supported by NTFS, just not exposed to normal users.
That's just your opinion about powershell...
UAT, and runas?
Why is this a problem? As a user, I've always preferred to have drive letters - it makes it immediately clear if, for example, I'm moving files between different physical drives.
Both epoll and kqueue permit multiple threads to poll the same event set. Normally you do this in tandem with edge-triggered readiness (EPOLLET on Linux, EV_CLEAR on BSD) so that only one thread will dequeue an event.
How do think IOCP is implemented in Windows? There's a thread pool in the kernel which _literally_ polls a shared event queue. It's just hidden so you can pretend it's magical. But conceptually it works almost identically to how you would do it in Unix.
The benefit of IOCP is that it's a native API. It's warts and shortcomings notwithstanding, developers never even need to think about how it's actually implemented. Whereas with epoll and kqueue you either have to roll your own framework, or select from various third-party options. Seeing how the sausage is made can turn some people off. But just because you don't see the gory details doesn't mean it's implemented using magical fairy dust.
There's much to recommend Windows, and many things the NT kernel conceptually gets right. But IOCP vs polling? The only real difference architecturally is how much of the stack sits in user-space vs kernel-space, and how much of the stack is delivered by Microsoft (all of if in the case of IOCP) vs other sources (in Linux, glibc does AIO, while all the event loop and callback code is provided by various libraries or written yourself).
Putting more of the stack in kernel-space doesn't magically make it easier to perform optimizations. That's marketing speak and kernel fetishism. You have to first show why those optimizations can't be achieved elsewhere, like in the I/O or process scheduler. Various Linux components traditionally are more performant (e.g. process scheduling) than in Windows, so many of the optimizations wrt IOCP is arguably clawing back performance lost elsewhere in the system.
According to your website pretty much every other technology runs better on Linux than it does on Windows, and of course pyparallel runs better than everything you tested.
How can I run these tests my self? I specifically want to test it against golang.
Source: https://github.com/tpn/pyparallel-tefb
Go-specific comment thread: https://www.reddit.com/r/programming/comments/3jhv80/pyparal...
https://www.reddit.com/r/programming/comments/3jhv80/pyparal...
heh..
I have a PC connected via on-board HDMI to a Denon AVR solely for the purpose of getting the audio to the amplifier. Windows doesn't let me use that audio interface without extending or mirroring my desktop to that HDMI port. Since there is no display connected to the AVR I don't want to extend the desktop, and mirroring heavily decreases performance of the system.
On Debian Sid the computer by default allows me to use the HDMI audio without doing anything to my desktop display. It seems the system realizes that there is no display connected to the AVR but it's still a valid sink for audio.
The Microsoft article cited above (https://support.microsoft.com/en-us/kb/156932) directly contradicts you:
> Be careful when coding for asynchronous I/O because the system reserves the right to make an operation synchronous if it needs to. Therefore, it is best if you write the program to correctly handle an I/O operation that may be completed either synchronously or asynchronously.
Microsoft is directly saying that it reserves the right to violate the guarantee you are counting on at any time, and it documents several known cases of this. You can try to guess when this will happen and put those I/O operations on a different thread pool, but you're just playing whack-a-mole. And you're violating Microsoft's own recommendations.
You wouldn't be using compression or encryption for a file that you wanted to be able to submit asynchronous file I/O writes to in a highly concurrent network server. Those have to be synchronous operations. You'd do everything you can to use TransmitFile() on the hot path.
If you need to sequentially write data, wanted to employ encryption or compression, and reduce the likelihood of your hot-path code blocking, you'd memory map file-sector-aligned chunks at a time, typically in a windowed fashion, such that when you consume the next one you submit threadpool work to prepare the one after that (which would extend the file if necessary, create the file mapping, map it as a view, and then do an interlocked push to the lookaside list that the hot-path thread will use).
I use that technique, and also submit prefaults in a separate threadpool for the page ahead of the next page as I consume records I'm writing to. Before you can write to a page, it needs to be faulted in, and that's a synchronous operation, so you'd architect it to happen ahead of time, before you need it, such that your hot-path code doesn't get blocked when it writes to said page.
That works incredibly well, especially when you combine it with transparent NTFS compression, because the file system driver and the memory manager are just so well integrated.
If you wanted to do scatter/gather random I/O asynchronously, you'd pre-size the file ahead of time, then simply dispatch asynchronous writes for everything, possibly leveraging SetFileIoOverlappedRange such that the kernel locks all the necessary sections into memory ahead of time.
And finally, what's great about I/O completion ports in general is they are self-aware of their concurrency. The rule is always "never block". But sometimes, blocking is inevitable. Windows can detect when a thread that was servicing an I/O completion port has blocked and will automatically mark another thread as runnable so the overall concurrency of the server isn't impacted (or rather, other network clients aren't impacted by a thread's temporary blocking). The only service that's affected is to the client that triggered whatever blocking I/O call there was -- it would be indistinguishable (from a latency perspective) to other clients, because they're happily being picked up by the remaining threads in the thread pool.
I describe that in detail here: https://speakerdeck.com/trent/pyparallel-how-we-removed-the-...
> > Be careful when coding for asynchronous I/O because the system reserves the right to make an operation synchronous if it needs to. Therefore, it is best if you write the program to correctly handle an I/O operation that may be completed either synchronously or asynchronously.
That's not the best wording they've used given the article is also talking about blocking. If you've followed my guidelines above, a synchronous return is actually advantageous for file I/O because it means your request was served directly from the cache, and no overlapped I/O operation had to be posted.
And you know all of the operations that will block (and they all make sense when you understand what the kernel is doing behind the scenes), so you just don't do them on the hot path. It's pretty straight forward.
I wrote Windows drivers and file systems for about 10 years, and Unix drivers and file systems also for about 10 years.
I'd rather practice substance agriculture for the rest of my life than deal with Windows drivers again.
Can programming against the userspace interface the I/O subsystem really be compared to programming against the kernel driver interface to I/O subsystem? In Linux, kernel drivers have access to structures, services, and layers that userspace doesn't. And can these be compared between a monolithic and a micro-kernel approach, other than what has been debated ad nauseam for micro/monolithic kernels in general (not just used for I/O)?
I just meant that writing an NT kernel driver will really give you an appreciation of what's going on behind the scenes in order to facilitate awesome userspace things like overlapped I/O, threadpool completion routines, etc.
Your example of device files is hardly universal, and the way it works is useful.
It literally doesn't make any sense whatsoever for many of these devices to behave like physical files, e.g. be deletable or whatnot. Yes there is an exception to every nonsense like this, so yes, some devices do make sense as files, but you completely miss the point when you ignore the widespread nonsense and justify it with the exceptions.
"Everything is a file" is about reducing most operations to 4 very abstract operations--open, read, write, and close. The latter three take handles, and it's only the former that takes a path. But you're conflating the details of the underlying filesystem implementation with the relevant abstraction--being a file implies that it's part of an easily addressable, hierarchical namespace. Being a file doesn't imply it needs to be deletable. unlink/remove is not part of the core abstraction. But they are hints that the abstraction is a little more leaky than people let on. Instantiating and destroying the addressable character of a file poses difficult questions regarding what the proper semantics should be, though historically they're deletable simply because using major/minor device nodes sitting atop the regular persistent storage filesystem was the simplest and most obvious implementation at the time.
On Linux if a socket is set to non-blocking it will not block. I don't really understand your point with shared buffers. You wouldn't typically share a TCP socket since that would result in unpredictable splitting/joining of data.
> In Linux, you don't, and userspace and kernelspace both end up doing unnecessary copying
I'm not so sure the Linux design where copies are done in syscalls must be inherently less efficient. I'm pretty sure with either design, you generally need at least one memcpy - for RX, from the in-kernel RX buffers to the user memory, and for TX, from user memory to the in-kernel TX buffers. I think getting rid of either copy is extremely hard and would need extremely smart hardware, especially the RX copy (because the Ethernet hardware would need to analyze the packet and figure out where the final destination of the data is!). Getting rid of TX copy might be easier but still hard because it'd need complex DMA support on the Ethernet card that could access potentially unaligned memory addresses. On the other hand, I also don't think you need more than one copy, if you design the network stack with that in mind.
> you need more than two system calls on average for every IO operation in performance servers.
True but it's not obvious that this is a performance bottleneck. Consider that a single epoll wait can return many ready sockets. I think theoretically it would hurt latency rather than throughput.
> As a rule, you can generally detect "design faults" by the number of competing and overlapping designs.
On Linux, I think for sockets, there are only: blocking, select, poll, epoll. And the latter three are just different ways to do the same thing. On Windows, it's much more complicated - see this list of different methods to use sockets (my own answer): http://stackoverflow.com/questions/11830839/when-using-iocp-...
> One specific fault of epoll (compared to near-relatives) is that the epoll_data_t is very small.
Pretty much universally when you're dealing with a socket, you have some nontrivial amount of data associated with it that you will need to access when it's ready for I/O, typically a struct which at least holds the fd number. Naturally you put a pointer to such a struct into the epoll_data_t. I don't see how one could do it more efficiently outside of very specialized cases.
Windows overlapped IO can map the user buffer directly to the network hardware, which means that in some situations there will be zero copies on outbound traffic.
> especially the RX copy I also don't think you need more than one copy, if you design the network stack with that in mind.
When the interrupt occurs, the network driver is notified that the DMA hardware has written bytes into memory. On Windows, it can map those pages directly onto the virtual addresses where the user is expecting it. This is zero copies, and just involves updating the page tables.
This works because on Windows, the user space said when data comes in, fill this buffer, but on Linux the user space is still waiting on epoll/kevent/poll/select() -- it has only told the kernel what files it is interested in activity on, and hasn't yet told the kernel where to deposit the next chunk of data. That means the network driver has to copy that data onto some other place, or the DMA hardware will rewrite it on the next interrupt!
If you want to see what this looks like, I note that FreeBSD went to a lot of trouble to implement this trick using the UNIX file API[0]
> On Linux, I think for sockets, there are only: blocking, select, poll, epoll. And the latter three are just different ways to do the same thing.
Linux also supports SIGIO[1], and there are a number of aio[2] implementations for Linux.
epoll is not the same as poll: Copying data in and out of the kernel costs a lot, as can be seen by any comparison of the two, e.g. [3]
Also worth noting: Felix observes[4] SIGIO is as fast as epoll.
> I don't see how one could do it more efficiently
Dereferencing the pointer causes the CPU to stall right after the kernel has transferred control back into user space, while the memory hardware fetches the data at the pointer. This is a silly waste of time and of precious resources, considering the process is going to need the file descriptor and it's user data in order to schedule the IO operation on the file descriptor.
In fact, on Linux I get more than a full percent improvement out of putting the file descriptor there, instead of the pointer, and using a static array of objects aligned for cache sharing.
For more on this subject, you should see "what every programmer should know about memory"[4].
[0]: http://people.freebsd.org/~ken/zero_copy/
[1]: http://davmac.org/davpage/linux/async-io.html#sigio
[2]: http://lse.sourceforge.net/io/aio.html
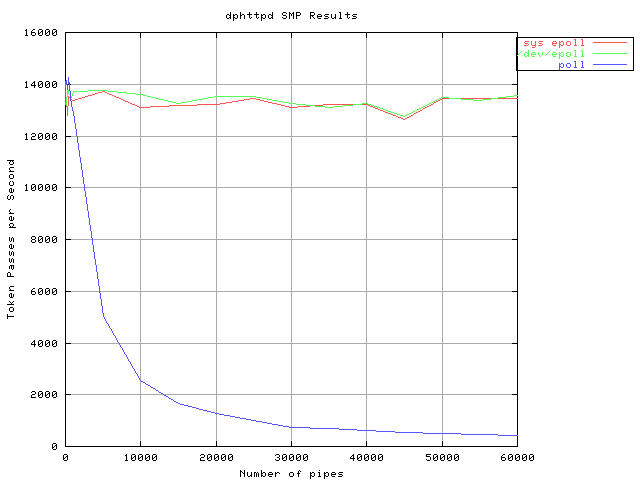
[3]: http://lse.sourceforge.net/epoll/dph-smp.png
I'm curious about sending data for TCP through, don't you need to have the original data available anyway, in case it needs to be retransmitted? Do the overlapped TX operations (on Windows) complete only once the the data has also been acked? Are you expected to do multiple overlapped operations concurrently to prevent bad performance due to waiting for ack of pending data?
It's hard to evaluate this in any way more than "yeah that's a cute spaghetti diagram". If I wanted to drag Linux through the mud visually I'd depict how much time every socket I/O op spends in vfs/fsync stuff. (i.e. you can depict anything to make your point)
This isn't a terrible recap of async file I/O issues on contemporary operating systems: http://blog.libtorrent.org/2012/10/asynchronous-disk-io/
The difference between Windows Overlapped I/O and POSIX AIO is that on Windows it's a black box, so people can pretend it's magical. Whereas on Linux there hasn't been interest (AFAIK) to merge patches that provide a kernel-side pool of threads for doing I/O, and the decades-long debates have spilled out onto the streets. If you view userspace code as somehow inelegant or fundamentally slow, then of course all the blackbox Windows API and kernel components look appealing. What has held Linux back regarding AIO is that Linux (and Unix people in general) have historically preferred to keep as much in userspace as possible.
This is why NT has syscalls taking 11 parameters. In the Unix world you don't design _kernel_ APIs that way, or any APIs, generally. In the Unix world you prefer simple APIs that compose well. read/write/poll compose much better than overlapped I/O, though which model is most elegant and useful in practice is highly context-dependent. As an example, just think how you'd abstract overlapped I/O in your favorite programming language. C# exposes overlapped I/O directly in the language, but doing so required committing to very specific constructs in the language.
As for performance, both Linux and FreeBSD support zero-copy into and out over userspace buffers. The missing piece is special kernel scheduling hints (e.g. like Apple's Grand Central Dispatch) to optimize the number of threads dedicated per-process and globally to I/O thread pools. But at least not too long ago the Linux kernel was much more efficient at handling thousands of threads than Windows, so it wasn't really an issue. That's another thing Linux prefers--optimizing the heck out of simpler interfaces (e.g. fork), rather than creating 11-argument kernel syscalls. IOW words, make the operation fast in all or most cases so you don't need more complex interfaces.
No. The difference is that in Windows you can check for completion and set up an overlapped I/O operation in one system call. Requiring multiple system calls to do the same thing means more unnecessary context switches, and the possibility of race conditions especially in multithreaded code. That and, as trentnelson stated, the Windows implementation is well integrated with the kernel's filesystem cache. Linux userspace solutions? Hahaha.
Supplying this capability as a primitive rather than requiring userland hacks is the right way to do it from an application developer's perspective.
My understanding is that Solaris event ports were intended to offer equivalent functionality to Windows' I/O completion ports, so this should not be surprising.
Solaris also has its own native async I/O API in addition to supporting POSIX async.
You can do some phenomenally sophisticated things... I extensively leveraged things like partitioning, parallel execution (dbms_parallel_execute!), lots of PL/SQL using the pipelined table cursor stuff, data mining stuff (dbms_frequent_itemset!), index-organized tables, and my god, bitmap indexes were a godsend, direct insert tricks for bulk data loading, external tables were fantastic (you can wrap a .csv in an external table and interact with it in parallel just like any other table -- great for ingesting large amounts of janky .csv data from other parts of the business).
The parallel execution and robust partitioning options were probably the most critical pieces that have no particularly good counterpart in open source land.
For batch-oriented stuff where you're getting pretty consistent data at a regular interview I'd go with SQL*Loader.
> don't you need to have the original data available anyway, in case it needs to be retransmitted? Do the overlapped TX operations (on Windows) complete only once the the data has also been acked?
I don't know. My knowledge of Windows is almost twenty years old at this point.
If I recall correctly, the TCP driver actually makes a copy when it makes the packet checksums (since you have the cost of reading the pages anyway), but I think behaviour this is for compatibility with Winsock, and it could have used a copy-on-write page, or given a zero page in other situations.
They took a code completion technique that works alright for an IDE and put it on the command line, losing some key usability in the process when they could have just implemented the paradigm that has been standard in the Unix world for decades.
Yes, it does a great job of identifying what the completion possibilities are in almost every context. That's good enough for an IDE, but only half the job when you're making an interactive command line shell.
As for other readline features: it's really annoying to only partially implement a well-known set of keyboard shortcuts.
Also, at least in PowerShell 5, if you run the ISE instead of the cmd-based terminal, it shows an IDE-like overlay of completions while you're typing.
PowerShell depends (or is based) in no way on cmd.
As for IOCP being "well integrated", what does that even mean? In Windows when file I/O can't be satisfied from the buffer cache, Windows uses a thread pool to do the I/O (presuming it just doesn't block your thread; see https://support.microsoft.com/en-us/kb/156932), just like you'd do it in Unix. There's nothing magical about that thread pool other than that the threads aren't bound to a userspace context. Maybe you mean that the kernel can adjust the number of slave threads so that there aren't too many outstanding synchronous I/O requests? But the Linux I/O scheduler can implement similar logic when queueing and prioritizing requests. It's six of one and a half-dozen of the other.
[1] At least, assuming you're doing it correctly. But sadly many libraries do it incorrectly. For example, I once audited for a startup Zed Shaw's C-based non-blocking I/O and coroutine library. IIRC, he had devised an incredibly complex hack to fallback to poll(2) instead of epoll(2) because in his tests epoll(2) didn't scale when sockets were heavily used; he only saw epoll scale for HTTP sockets where clients were long-polling. But the problem was that every time he switched coroutine contexts, he was deleting and re-adding descriptors, which completely negated all the benefits of epoll. Why did do this? Presumably because to use epoll properly you need to persist the event polling. But if application code closes a descriptor, the user-space event management state will fall out of sync with the kernel-space state, which is bad news. He tried to design his coroutine and yielding API to be as transparent as possible. But you can't do that. Performant use of epoll requires sacrificing some abstraction, similar to the hassles IOCP causes with buffer management.
The benefit of IOCP isn't performance--whether it's more performant or not is context-dependent. The biggest benefit of IOCP, IMO, is that it's the defacto standard API to use. You don't need to choose between libevent, libev, Zed's Shaws library, or the other thousands of similar libraries. On Windows everybody just uses IOCP and they can expect very good results.
The myth that IOCP is intrinsically better, or intrinsically faster, is a result of what I like to call kernel fetishism--that things are always faster and better when run in kernel space. But that's just a myth. IOCP nails down a very popular and very robust design pattern for highly concurrent network servers, but it's not necessarily the best pattern. And sticking to IOCP imposes many unseen costs. For example, it makes it more difficult to mix and match libraries each doing I/O because when you're having to juggle callbacks from many different libraries your code quickly becomes obtuse and brittle. It also demands a highly threaded environment with lots of shared state, but that likewise leads to very complex and bug prone code.
(Also, curiously when the data's in the cache that page shows a performance penalty for async reads that complete synchronously from the cache compared to sync reads. Wonder why.)
I've never had a single issue with "async things suddenly becoming synchronous which blocks the main thread" -- if you architect things properly that just never happens, blocking operations are off the hot path, and when you absolutely must block, IOCP's concurrency self-awareness kicks in and another thread is scheduled to run on the core, ensuring that each core has one (and only one) runnable thread.
Because a synchronous operation is always faster than an overlapped operation if it can be completed synchronously.
Lots of stuff happens behind the scenes when an overlapped operation occurs.
It's just that every console application on Windows uses that host. This includes cmd, PowerShell, Far Manager, or even vi. Sorry, I may have seen it conflated with cmd too often. It just nags me. For Linux users it's probably when everyone starts calling a terminal (emulator) "bash".
{kind=link}
{kind=link}