Maybe Blockchain Really Does Have Magical Powers(bloomberg.com) |
Maybe Blockchain Really Does Have Magical Powers(bloomberg.com) |
"In other words, the only thing previously stopping the standardization of reconciliation processes was the unwillingness of financial institutions to collaborate."
No, actually, the one thing the blockchain provides, which was literally unsolved before pre-Nakamoto, was a working implementation of "trustless" consensus. Turns out fraud prevention is kind of a big deal shuffling around billions or trillions among numerous third parties, but I'm sure that's just because they're "security-conscious egoists."
That's the part banks do not care about so I think it's largely irrelevant in the context of this article.
I have no idea where you got that idea, but it's not true. Which is why any deal that happens between institutions (and sometimes intra-institution) has an army of middle men who are responsible for verifying, monitoring, reporting, etc etc.
Unfortunately, even at this point, Smart Contracts probably still have many security challenges to overcome before banks can adopt it.
Resistance to new technology is definitely a thing at banks, I remember when I worked at one I mentioned blockchain one day and everyone looked at me like deer in the headlights.
Ripping Bitcoin in two gives you two fairly uninteresting things: 1) hash-cash and 2) a database full of public keys/signatures. Only combining the two gives you something interesting: negotiable/fungible hash cash (hash cash that can be transferred from person to person via a distributed database).
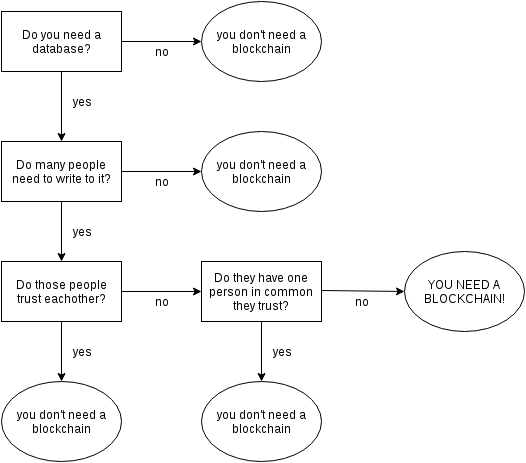
This is the naive view that has allowed the financial industry to ditch Bitcoin and run with blockchain. The problem that Bitcoin solves and private blockchains do not is called the Byzantine generals problem which did not have a known solution until Bitcoin came along.
Private blockchains cannot solve the Byzantine generals problem because they cannot ensure that one of it's limited number of parties is not employing massively more computing power in order to cheat. Bitcoin only works because an unlimited number of players are mining as hard as they can making it improbable that a single entity can exceeded 50% of the total hash power. With private blockchains it will always be reasonable to assume that cheating would be with in reach.
With bitcoins, there is no possibility for dispute: bank A gives bank B the money during the transfer.
Any other scheme involves a promise (a legal contract), so you will not know for sure that bank A really had the money to give to bank B. The solutions to this are all in use today:
(1) Bank A previously gave B money (they have a correspondence account in B). So the transfer is really between accounts at bank B.
(2) Bank A gives bank B physical money.
(3) Bank A transfers money to B between accounts at some other bank (or the fed). It means A had money in the other bank to begin with.
(4) Bank B gives credit to bank A (i.e., Bank B trusts Bank A) and accepts IOUs from them. The banks could cancel out each others IOUs. The IOUs become new money. This used to be done in the old days, but the basis for trust was each bank's gold reserves.
Can anyone provide some ideas of how I, as a solo entrepreneur, could improve software by using a blockchain? I get how it might provide tremendous values for bigcorps, but I'm not part of that audience.
I haven't read the article, and I been tired of blockchain hype for multiple years, but if this is an accurate tldr of the article, it isn't true at all. Blockchains are far more than simple shared ledgers. They're trustless shared ledgers, which is a huge leap forward from simple shared ledgers, and a pretty big deal for financial institutions, for whom dealing with trust issues is a major headache.
Also they probably don't want Proof of Work for its wastefulness.
I would have thought it was the coca.
>Similarly, the term “blockchain” has been so misappropriated that no one knows what it means anymore.
Thankfully, those who no longer know can just grab the paper at bitcoin.org/bitcoin.pdf and get a refresher.
First, solutions to Byzantine agreement for known numbers of processes predate Bitcoin.
Second, Nakamoto Consensus is not Byzantine agreement. Byzantine agreement forbids committed writes from being reverted, and each replica sees the same history of writes. However, Nakamoto Consensus only offers probabilistic write durability (our transactions can get orphaned arbitrarily far into the future), and different peers can see divergent histories of arbitrary length even under normal operation.
Third, Byzantine agreement is defined in terms of the set of peers. Systems where the agreement protocol does not know the number of peers cannot solve the Byzantine agreement problem, since they can't prove that no more than f of 3f+1 peers are faulty (neither quantity is known to the system).
Fourth, open-membership Byzantine agreement was published this year: http://hackingdistributed.com/2016/08/04/byzcoin/. The membership set changes every "block", but the peers in the set during the current epoch are known.
EDIT: typo
Mining is a function of turning electricity into coins. Since coin generation rate is fixed through a difficulty adjustment, mining becomes a winner-take-all game where only those miners with the lowest electricity costs can effectively compete. Thus the system collapses quickly into a mining oligarchy.
What does Byzcoin propose to resolve the as-yet unresolved problem of mining centralization, which is fundamental to the success of any of these coins?
I'm not an expert in any way, but the Wikipedia page for Byzantine Fault Tolerance suggests a solution to this problem was known as early as 2001, used in the Boeing 777 avionics software. See abstract of the paper below. That significantly predates Bitcoin. Or am I misunderstanding something?
Not that improbable: http://www.coindesk.com/ghash-io-never-launch-51-attack/
In a regulated industry there are other ways to prevent cheating. Making cheating obvious and undeniable is probably enough to prevent it from happening (due to legal risk).
In cash transactions, it's hard to beat the speed of a trusted third party with a deposited "float" for ensuring that you can pay at the end of the day - even a bad day where a part defaults.
In securities, there is perhaps some room for a blockchain solution, as the infrastructure is much more complex and underdeveloped - due to the historically gigantic margins.
In this model, individuals would not need to store the entire chain as they could lazily fetch parts of the chain as they are needed. This would allow individuals to store very little of the historical blockchain data if their use case doesn't require them to access that historical data.
There are nuances to this solution. IPFS can be thought of as one giant torrent, and with torrents, someone must have the part you need for you to be able to fetch it. There is a theoretical failure mode in this model where everyone happens to delete the same part of the blockchain thinking that they won't need it and if they do they'll get it from someone else. In this case, this portion of the chain history would be lost. This failure mode should be simple to mitigate, especially since many people participating in the network need access to significant portions of the historical data, and everyone won't use the IPFS based storage layer so, when a chunk is not available over IPFS, the client can just fetch it over normal means.
I can imagine this working in a low volume chain. I do really doubt it would ever work on current Bitcoin chain or anything bigger.
You'd need to keep enough of the chain live for all "live" transactions; that would likely have a time bound (days, perhaps). People who run a "full" client that verifies the complete blockchain then just need to have enough storage for the complete transaction volume over that time period. (And people who only need to worry about their own transactions and don't care about verifying other people's transactions can hold onto even less data.)
Vitalik Buterin (Ethereum lead) also posted a description of how Ethereum will implement State Tree Pruning [2].
These are short/medium-term scaling solutions.
Many people are pushing sidechain [3] / child-chains [4] as longer-term ("Visa" level) solutions.
* Lightning Network [5][6] is what Blockstream and others are pushing for Bitcoin scaling.
* Raiden Network [7] is the Ethereum version, and may come out before Lightning, funnily enough.
For those interested in the topic matter, Vitalik wrote a pretty dense paper on blockchain scaling last year [8].
While sidechains will be an option, Ethereum is also pursuing on-chain scaling as well.
Sharding is scheduled for the upcoming Serenity release [9] (which also switches to Proof of Stake (Casper), another important scaling-related change). Writeup on Serenity PoC2 [10].
In general for scaling atm, processing/network latency/bandwidth for initial sync is more of a bottleneck than raw storage. By that measure, I'm actually a lot more interested in the on-chain tx-processing that Casper/PoS might bring [11].
Of course there's no requirement for a single chain to handle everything. Especially over the past few months, we've seen a few relatively smooth migrations to multiple chains as Bitcoin tx processing has "maxed out" (or more recently as fungibility/privacy issues have loomed). At the same time, Bitcoin volatility has stabilized, so it might be just the natural life cycle for blockchains to "scale" until they can't. It's still early days, so who knows?
[1] https://bitcoin.org/en/bitcoin-paper
[2] https://blog.ethereum.org/2015/06/26/state-tree-pruning/
[3] https://gendal.me/2014/10/26/a-simple-explanation-of-bitcoin...
[4] https://www.ardorplatform.org/
[5] https://lightning.network/
[6] https://lightning.network/lightning-network-paper.pdf
[8] https://github.com/vbuterin/scalability_paper/blob/master/sc...
[9] https://github.com/ethereum/EIPs/issues/53
[10] https://blog.ethereum.org/2016/03/05/serenity-poc2/) from March
[11] https://twitter.com/VitalikButerin/status/760185856057638913
(phew, maybe one day HN will have markdown support, maybe one day...)
It is not even close to that yet. Eventually yes. Right now the bitcoin blockchain is about 80GB.
What real numbers are you using to predict this being a problem?
BTW a 120TB SSD meant for read heavy workloads was announced not long ago. Huge, fast random access and made for reads is exactly what you would want.
Beyond that my own prediction is that there will be many successful crypto-currencies. Most people won't store the blockchain of any of them, but whoever wants to be more involved could pick and choose.
This somewhat makes sense since one of Corda's departures is that consensus and validation are limited in scope to the participants.
Back when I was doing trading systems, my traders would have murdered me if my response time graph looks like the Bitcoin one does. [3]
[1] http://martinfowler.com/articles/lmax.html
[2] https://blockchain.info/charts/n-transactions-per-block
[3] https://blockchain.info/charts/avg-confirmation-time?timespa...
ByzCoin has PoW to be Bitcoin compatible, but it can change to PoS or PoA or even permissioned systems (e.g hyperledger).
I have been asking this question for a long time and not yet seen a satisfactory answer. At this point I'm sure that either I or a bunch of blockchain advocates are missing something important. Glad to know somebody else sees the problem too.
Imagine you wanted to build a Hubspot/Triggermail/Vero type system, where you send emails to users when certain events are triggered.
Now suppose you use Sendgrid or Amazon to actually transmit your mail. You are unlikely to give very many developers actual sendgrid keys or access to call sendgrid. Most developers will call an internal API to send mail. This internal API will then perform a bunch of sanity checks - duplicate detection, rate limits, dirty word filters, etc.
Can you "cut out the middle man" by letting each internal service have their own internet connected SMTP server, and stop paying sendgrid and fire whoever builds the internal API? That would be pretty silly.
Similarly, a bank can't really get rid of the risk checks, money laundering checks, data normalization checks, etc.
For usage, one of the mains advantages would be for systems that you don't want to use a centralized system anymore - for whatever reason from privacy to control over your data to simply infrastructure reasons (i.e you want 100% uptime and no censorship), and want to transform it into a decentralized system.
Though we've rather ruined the twist ...
If you have block D, and want to fetch block A, you don't actually know if it's the real block A unless you also have blocks B, and C. Block D (which you have) contains the hash of block C, which contains the hash of block B, which contains the hash of block A. You need the hash of block A to be able to verify that it is indeed the real block A.
Of course, because of things like SSL/TLS, you can be sure nobody tampered with the block on it's way from the server to you. With that in mind, ensuring you receive the real block just requires you to trust the server giving you the blocks, which may or may not be worth it depending on how much time/space it saves you. In some ways, the server would become your 'central authority' on the block-chain.
In reality though, I can't really imagine there's much they could do. Sending you fake blocks may work for a while but would fail if the client caches them and asks for the surrounding blocks (Their fake block isn't going to match the hash of the real block). I think it would be a bit hard to pull off for any length of time.
It suffices to have the headers of blocks B and C. Which, at only 80 bytes per header, is quite manageable.
Imagine that block n, when produced, in addition to the hash of the previous block n-1, gave the hash of block n-2, n-4, n-8, ..., n-2^n. This implies that the block size grows linearly, but it should give you the following: whenever you request and obtain a past block A and you have the current block D, you can use these pointers starting at D to easily request and obtain a sequence of blocks (of length log n) which allows you to authenticate A from D. (Of course the algorithm to reach from A is simply to request the first block authenticated in the header of D which is after A.)
Come to think of it, why does the variable number of generals make a difference? When you are making a single decision, is that decision not an atomic operation such that the number of generals influencing it is fixed? Otherwise, wouldn't necessarily the outcome of the vote be (marginally) affected by the order in which you evaluate the votes cast? (That seems like a very bad property for a consensus algorithm to have.)
Thus if you have the header, you do indeed have everything you need to produce a hash and verify that it matches the hash referenced in the succeeding block. You do not need the information describing individual transactions.
If you think of your bitcoins as following a path from address to address, the pruning process would retain the final node or two on that path but discard any previous nodes. So your 10 year old bitcoins at address X are still the most recent node on that chain and are kept around. However, once they are finally sent to another address the bits recording your current address can be forgotten.
SET a 2
SET b 4
SET a 6
SET b 10
SET a 20
SET a 20
SET b 10
So let's say I buy a bunch of bitcoins and I just sit on them.
A year or two from now, they're worth a bunch of money, so I use them or sell them. How does everyone with the truncated blockchain know that the bitcoins I'm using aren't being double-spent?
{kind=link}