Don't use the greater-than sign in programming (2016)(llewellynfalco.blogspot.com) |
Don't use the greater-than sign in programming (2016)(llewellynfalco.blogspot.com) |
If we were optimizing for readability and predictability, we'd standardize on the most commonly used format.
``if (x > 5 && x < 10)``
Putting a rule that variables should always be on the left hand side of a comparison also gives you only 2 ways to write any conditional, so it's just as good as getting rid of ``>``. It also has the advantage of being by far the most widespread way that people already write conditionals, so you don't need to hold a team meeting where you explain to a bunch of grumpy senior programmers why even though they think their coding style is easier to read it actually isn't.
But by far the best option is to not have a meeting at all and to not care about things like this. In the absence of real, tangible data that conditional styles are causing bugs, these kinds of debates are very often a pre-optimization, and pre-optimization should be avoided.
When I put the effort into tracking and ordering the root causes of the majority of bugs in my software (both in personal projects and in large corporate environments) I am often surprised at the results. Very rarely are they consistent with the causes I would have predicted.
That's why I call things like this bikeshedding. In a large organization, it is probably more productive for you to hold another meeting about encapsulation and code reviews than it is for you to start up a Slack discussion about what style people use on their conditionals.
Indeed. This article reads like someone who doesn't understand inequalities, and proposes a quite possibly hazardous shortcut to it instead. To not understand such basic maths is baffling (this is primary-school stuff), and I wonder at the state of maths education these days to see adults struggling with these concepts.
I have never in over 3 decades of programming ever had to ask myself the question of how to write conditional expressions --- it's something that comes naturally, and in this specific case I would also write it with the variables on the left.
That said, I've come across code where the variable is always on the right. This often seems to be a throwback for some devs to alleviate the problem of mixing up equality and assignment.
That is, it seems that some people have been taught to use this expression (& stick to it religiously):
if (5 == x) ...
simply so that if they make a mistake and type
if (5 = x) ...
the (C/C++) compiler will reject it. So, these people always write the slightly more awkward case (imho) of:
if (5 < x && 10 > x) ...
but to me it doesn't read as cleanly, because we don't say it that way.
Of course, there's the problem of understanding the meaning of 'between' which can be inclusive of the end points, or exclusive...and you really can't tell from the english. In every case, it needs to be clarified. (eg 'pick a number between 1 and 10'):
if (x>=1 && x<=10)...
Not really the point I was getting at. I don't think the author is stupid, and I don't think their style is hazardous. I think it doesn't matter.
This is how I usually write inequalities. Have you considered that possibly the author and I understand how they work and would like a consistent way of formatting them to save time while reading them?
If you were working with me on a project, unless I had solid evidence that conditional styles were causing bugs, your style might warrant one curious comment on a single code review, but nothing else.
If it became obvious that it was causing bugs, we'd standardize on whatever the majority of people in the office already used, even if that was:
``if(10 > x && 5 < x)``
Are you serious? These are just 2 neat ways for expressing common boundaries conditions. The point is it's more readable instead of using '>'. That is all.
Counter-point: When checking if a variable is greater than a constant, using the less than is very confusing since we read left to right.
if(x > LIMIT) {
Read "If x exceeds LIMIT, then"
The opposite reads like "If the LIMIT is less than x", which sounds strange and emphasizes the wrong thing, implying LIMIT changed, not x.
But if the way you think about the domain is "if x is larger than LIMIT..." you should write it `if (x > LIMIT)`!
a < b <= c < d <= f <= g < h
You would then conclude that a < h holds.
I haven't looked at the article, but based on the comments it sounds like the author has this kind of thing in mind. I got the vibe that he was arguing that you shouldn't mix < with >, not that he was arguing that comparisons should only ever be made low-to-high.
But checking if an index is not too high for an array, is something I do very frequently.
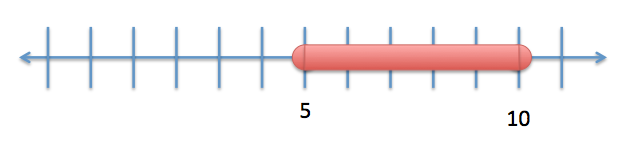
5 < x && x < 10 vs. x > 5 && x < 10
(5 < x && x < 10)
This is a nice way of expressing "x is between 5 and 10"
because it is literally between 5 and 10.
(< 5 x 10)
It has non-trivial advantages and drawbacks, which are interesting to document.
For similar reasons, I find this notation helps me prevent errors, because they become visually detectable.
5 < x && x < 10
x < 10 && 5 < x
So the number line analogy is incomplete and even when there is only </<= you still need careful reasoning.
'if x==4' was written as 'x[4]'
'if x>2 && x<4' was written as 'x(2,4)'
'if x>=2 && x<4' was written as 'x[2,4)'
Etc.
It was very easy to read and write... at least for me.
I made the scripting language as an easier way to program the 'rules' in the cell class. Dozens of little rules such as "if chemcial_0 is between 0.879 and .936 the increase chemical_1 by a smidgen," or "if chemical_23 equals 1.738 then undergo mitosis."
The little shorthand syntax was far easier to read than the mess of conditionals in C++.
It was pretty neat. Used Box2d for the physics part.
Got up to making a worm kinda thing with legs. But then gave up.
Trying to make identical cells differentiate into asymmetrical patterns is something that always intrigued me. Got interested after reading this: http://www.mvla.net/view/19352.pdf
How's that for a long-winded answer...
if-not x[-2,2]
x)-2,2(
x![-2,2] if (2...4).contains(x) $ swift
Welcome to Apple Swift version 4.2.1 (swiftlang-1000.11.42 clang-1000.11.45.1). Type :help for assistance.
1> let x = 3
x: Int = 3
2> if x in 2...4 {}
error: repl.swift:2:6: error: expected '{' after 'if' condition
if x in 2...4 {}
^
if case 2...4 = xNo, your are not smarter than everybody else. You just have different tastes, and you are not even covering all possible use cases (I would say that most people find "x > 0" more legible than "0 < x").
A lot of "Don't do" or "X considered harmful" article writers should really be a bit more careful before generalizing from "I like" to "everybody should" so quickly.
You also only end up with two options, in the same way, and IMO (x > 5 && x < 10) is much more readable than (5 < x && x < 10) .
(5 < x && x < 10)
if we're talking about X, whats wrong with defining the parameters of its constraints in terms of X instead of dancing around the numbers? 5 < X makes it sound like im setting constraints on the number 5.
5 < x && x < 10 is the attempt to replicate this in other languages but falls a bit short
You don't need this specific trick in python (as others have pointed out, `5 < x < 10` works), but in general python holds to a similar philosophy of using standardized idioms to make reading code easier. It's called "being pythonic".
> (x < 10 && 5 < x) which is a stupid option because it implies 10 < 5
What? no it doesn't!
> (5 < x && x < 10)
It's already very obvious that one can take 5 < x < 10 and split it into 5 < x && x < 10 right off the bat. Loads of examples of that out there.
The number line representation is incorrect. (5 < x && x < 10) represents x has possible values of 6,7,8,9 (assuming x is int), whereas the number line shows that 5 and 10 are inclusive, but that's not the case as per the provided example.
"which is a stupid option because it implies 10 < 5" No it doesn't.
And I stopped reading.
Let's say that I want to check that something is between 5 and 10.
...you did not specify explicitly whether the ends are inclusive/exclusive, and IMHO that (and the off-by-one errors it causes) is far more important.
Related: I've more than once had to ask someone whether "I will be away from 23 to 27" was inclusive or exclusive for the 27, because e.g. "meeting from 10 to 11" usually is exclusive at the upper end.
I’ve arrived to the same general conclusion independently, which is reassuring.
x.between?(6,9)
x.between?(5.0.next_float, 10.0.prev_float)Ruby is my main language and I would have to look up the boundaries of this function.
Your "explicit" statement is also so much worse than using `x < 5.0` or `x <= 5.0`, depending on what you want. This is terrible advice imho.
Anyway, ranges are another way of expressing the concepts in Ruby:
(5.0.next_float..10.0.prev_float).include?(x)
(5.0.next_float...10).include?(x)
(5..10).include?(x)
(and 7 other ways)
guard let array = obj.someArray,
array.count > 0 else {
throw SomeError
} guard !(obj.someArray?.isEmpty ?? true)Plus, I don't like abusing the nil coalescing operator. Once you're abusing anything, you're adding signal to noise and making the intent of a statement less clear than necessarily, I feel.
+1 for isEmpty, though. According to the docs, count iterates over collections that don't conform to RandomAccessCollection, so best to avoid unnecessary overhead by adopting good practice! Thanks for that.
guard let array = obj.someArray,
0 < array.count else {
throw SomeError
}
?I believe in self-documenting and obvious code, and I think if statements should read as much like a human sentence as possible.
Also in python you can just do `if 5 < x < 10` :)
On the contrary, it's Python that added the shorthand, mathematical-looking notation because the longer "desugared" form wasn't great.
But the point of being able to collapse a < b and b < c into a < b < c is there to make ranges easier to notate/read. That's seems to be nemo's wish. (Though perhaps he wishes the range to be completely separate, e.g., in the psuedosyntax `b in [1, 3)`.)
I don't think I've ever seen it actually used for anything else, and I would in advocate against it, in code review.
Yes, this would be a terrible practice. But that's what Python offers. The desire to express that a variable's value lies within a range is very common, and is presumably the reason for Python's bad choice. But that doesn't make Python's syntax a good response to the desire. The syntax expresses a conceptual mess; you're relying on people only using a tiny subset of what's there.
Contrast lisp, where you actually can express the concept of a range, as (< lowBound variable highBound). Unfortunately, that won't allow you to mix soft bounds with strict bounds. But it's vastly better than Python's approach.
Contrast Ruby, which offers almost every convenience in ranges, including literal notations, that you could ask for.
$ swift
Welcome to Apple Swift version 4.2.1 (swiftlang-1000.11.42 clang-1000.11.45.1). Type :help for assistance.
1> let x = 3
x: Int = 3
2> let y = 3.0
y: Double = 3
3> 2...4 ~= x
$R0: Bool = true
4> 2...4 ~= y
$R1: Bool = trueIn some languages, similar constructs test membership in a list/range, rather than an inequality.
Edit: I take that back. Here's a section from Python's range() documentation:
> The advantage of the range type over a regular list or tuple is that a range object will always take the same (small) amount of memory, no matter the size of the range it represents (as it only stores the start, stop and step values, calculating individual items and subranges as needed).
So it may be a O(1) operation under the hood.
Equivalent pseudocode:
function in_range(x, a, b):
for i=a; i<b; i++:
if x == i return true
return falseWhere I work, it might possibly come up in a code review, or be discussed when pair programming. I think most people would agree when pointed out that this rule makes sense.
Even when I've worked under fairly strict coding rules, no one has tried to tell me how to do this particular thing yet, so I was thinking I would start practicing this on Monday, since it seems reasonable.
Though in reality it will probably only come up 1-2 times per year, and most of my coding is in Python these days, so what am I even talking about...
And yes, adding something to a style guide should include you consulting your teammates, which also ideally shouldn't be on a one-on-one basis. If you do that, you instantly create one of those "I thought we all agreed that..." situations because of unclear communication.
> Though in reality it will probably only come up 1-2 times per year
That would be my guess from personal experience, too. In addition to that, those range checks would usually be error checks, in which case two other cases can crop up:
a) It's better to check them separately anyway (as part of the much more important "fail fast" rule). This way, you can produce two different error messages which is way more useful if you really have to deal with the case:
if (x < 0) throw ArgumentOutOfRangeException("x cannot be negative","x");
if (x > y) throw ArgumentOutOfRangeException("x cannot be greater than y","x");
b) You're checking within a unit test, where using some assert-function basically makes the decision for you. Asserts usually log an error message on failure, which is important to be readable and depends on the order of the arguments.
Thus, this won't be a real issue as much as you even encounter a range check. And that frequency just doesn't warrant the time effort to set in stone some arcane rule that half your team wouldn't remember anyway, since it only applies once a year at maximum.
On a personal note: My team recently went over our original style guide, which sadly was neglected for quite a while before I even joined it. I can tell you from personal experience that people are willing to define the most arcane rules you can imagine. We've hat people arguing for things they (as a single person) seem to have adopted two decades ago, are purely subjective (no objective upside whatsoever, as opposed to this one) and go against any established style guide in the programming language we use, which means that our style would always clash with third-party code in some really obscure way.
I wonder if the purpose isn't often to at any price avoid discussion and disagreement. I can see how a style guide is preferable to firing the people that are impossible to talk to, but that would be much healthier for the team.
Pull the lever when x < 0
Also, Unicode calls it U+003C LESS-THAN SIGN and U+003E GREATER-THAN SIGN.
At least, that's the terms that the article is using, and I think there's sufficient context to identify that, and go along w/ it.
The convention I've always seen is that `>` is "greater than" and `<` is "less than". Reading from left to right `x > 2` is "x is greater than 2" and `2 < x` is "2 is less than x". Functionally the same, yes, but with a distinction in the way the comparison is done (reading left to right). So with a preferred/dominant reading direction I would consider them different. This would be important if reading/describing a line of code to someone where it might be read/written left to right.
I don't know if the names are reversed in languages that are read right to left?
{kind=link}