eBPF – The Future of Networking and Security(cilium.io) |
eBPF – The Future of Networking and Security(cilium.io) |
For the last few years, I managed the Container Runtime group at Facebook. My experience has been:
1. `if (has_capability(..., X)) { ... }` gets put into code pretty haphazardly in a way that's not necessarily super well structured. Once it's there, it's ABI, and you're screwed if you want to iterate on it. That's why cap_sys_admin is /almost/ root.
2. If you wanted to do the right thing from the jump (e.g. for bpf itself), you'd have to add a new capability. This is a heavy lift for something that might not actually get any traction. It requires changing a bunch of common tools, and you likely end up breaking a bunch of applications.
3. Debugging capability failures is a pain in the ass. We ended up building and deploying capability tracing infrastructure just to figure out what people are actually using.
4. For gradual roll outs of enforcement/changes, you need the flexibility to warn first, enforce second. We did large scale monitoring of all such changes to make sure we didn't break the workloads.
5. Even if you nail all of the above, the ability to make finer-than-capability-grained decisions (i.e. binding to port 20 or 80 is okay but not port 22) is really valuable.
I'm all for kernel abstractions that just work and solve all problems for all people, but I think the overwhelming trend has been towards kernel interfaces that provide a lot of flexibility and then more opinionated libraries/tools that kind of let us have our cake and eat it to (io_uring => liburing, bpf => libbpf, btrfs => btrfstools).
[1]: https://www.tcpdump.org/papers/bpf-usenix93.pdf
[2]: https://ebpf.io/what-is-ebpf#hook-overview
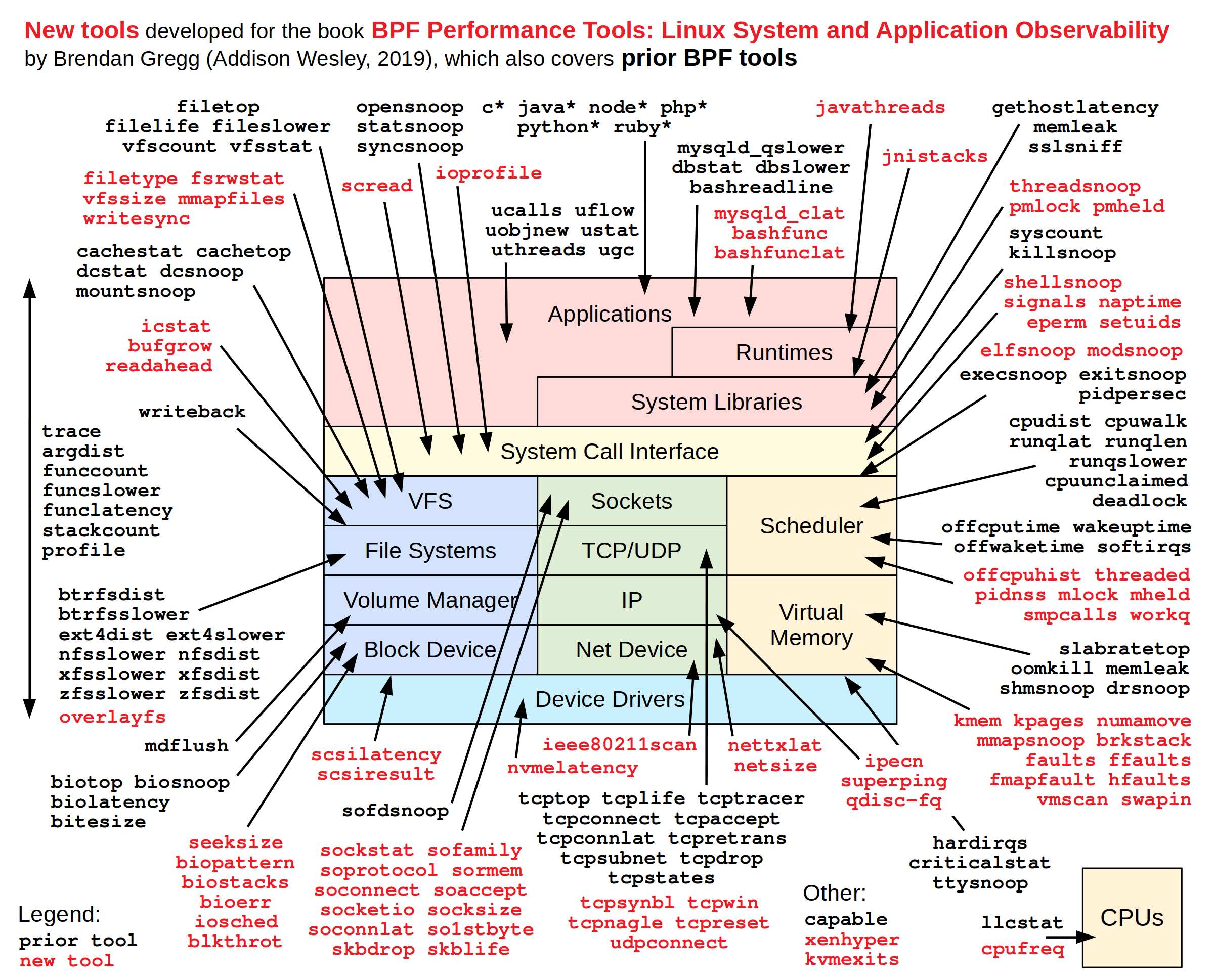
[3]: http://www.brendangregg.com/BPF/bpf_performance_tools_book.p...
https://fly.io/blog/bpf-xdp-packet-filters-and-udp/
An interesting fact is that packet filtering as a problem domain has been dominated by in-kernel virtual machines going back into the 1980s; it's an idea that comes all the way from Xerox.
https://github.com/xdp-project/xdp-tutorial
It's a good thing, I think! Compared to loading new unmanaged C code into the kernel, BPF is a really nice way to add functionality to Linux.
Happy to answer any questions.
As for the question: How are you looking to make money?
https://github.com/solana-labs/rbpf
Unlike more common Rust + LLVM + WASM toolchain, Solana smart contracts use Rust + LLVM + eBPF.
They appear to be running some kind of "open security test"[1] but are only paying out their own imaginary funny money. I'd suggest you run for the hills as fast as you can instead of considering Solana.
0: https://github.com/solana-labs/rbpf/blob/f7007d6ae8728e61401... 1: https://forums.solana.com/t/tour-de-sol-stage-1-details/317
We’re currently moving to Kubernetes for our infrastructure at the Berkeley OCF (https://ocf.berkeley.edu/), and picked Cilium for all the networking things.
It’s good to see that there’s a company backing it now!
The Future of Networking? Networking is not only linux. eBPF is linux-only. Everyone else uses the secure variant dTrace, which has even wide-spread user-space support. So you can trace across the kernel, processes and its extensions/scripts. For decades.
Future of Security? eBPF is insecure. User-accessible arrays in the kernel can never be secure. dTrace did not do that for a reason, it was already compromised with the spectre-like attacks, and the fixes were laughable at best to safe face.
Linux might be advised to do better (or is just NIH?), but advertising Worse as Better was fashionable in the 80ies only.
Comparing dTrace and eBPF is definitely a very interesting question. I've actually asked Brendan Gregg in the Q&A of his keynote at eBPF summit this year how he compares dTrace and eBPF these days. Here is his answer (jumps right to the specific question): https://youtu.be/jw8tEPP6jwQ?t=4618
I doubt that eBPF will remain a Linux-only technology. Ports to FreeBSD are already underway it seems [0] and Microsoft declared intent to invest into eBPF [1]. I'm not sure what that means on timeline for eBPF availability on Windows though. There are also several user space implementations for eBPF which could become interesting to provide a universal programmability approach across traditional kernels like Linux, microkernels like Snap and application kernels like gVisor.
[0] https://papers.freebsd.org/2018/bsdcan/hayakawa-ebpf_impleme... [1] https://twitter.com/markrussinovich/status/12830391539203686...
That said, looking at the (apparently) leading implementation, capsicum
> Capsicum also introduces capability mode, which disables (with ECAPMODE) all syscalls that access any kind of global namespace; this is mostly (but not completely) implemented in userspace as a seccomp-bpf filter.
So I do feel that bpf ultimately enables building the kinds of abstractions that people want.
They pioneered many groundbreaking and game changing works on computing including (but not limited to) windowing desktop environment, integrated programming/structural editor with CEDAR/Tioga, SQL (team moved to Oracle), Ethernet networks, laser printer, VLSI and Jupiter operational transform for distributed computing (precursor to CRDT). Each of this technology is now an industry of its own.
[1] https://www.amazon.com/Dealers-Lightning-Xerox-PARC-Computer...
The best we have gotten so far are the hybrids .NET/Windows, JME, Android Java/Linux, Chrome/Linux, Swift/iOS/macOS.
That’s the type of history you’re articulating here.
Buggy kernel code will crash your machine. The kernel is not protected from a buggy kernel module. I think people assumed that this is just how things are; that's the price to do kernel programming. eBPF changed this dogma. It brought safety to kernel programming.
"It brought safety to kernel programming" , if you use eBPF and don't expose bugs in the parser, or checking or validation systems. (These have already happened).
Many people seem to make an assumption that kernel code is perfect and that when code is merged into the Linux kernel, it is automatically secure. That is definitely not the case. Kernel developers make mistakes as well and they have devastating consequences.
Right now, the security of the Linux kernel code depends on a combination of code review, fuzzing, controlling the pace of code changes, and running LTS releases to increase the chance others found the bugs already.
eBPF further increases the security model of kernel development by adding a verification step to the model. It means that there is an additional layer of protection in case of code imperfections.
The focus on eBPF safety is awesome. eBPF is software, software will have bugs, eBPF is no exception. The best way to improve the security of software is to question it. Given the wide spread use of eBPF in highly critical and exposed scenarios, the pressure on making it as bug-free as possible is very high so it's probably fair to assume that the scrutiny put in place, will lead to a high quality implementation of the verifier.
If anything, eBPF is less sound than classic BPF, because the verifier is dramatically more complicated, as is the execution environment.
I'm just here to say that eBPF and BPF are in fact pretty closely related. The eBPF design is uncannily similar to Begel, McCanne, and Graham's BPF+ design[1]; in particular, the BPF+ paper spends a fair amount of time describing an SSA-based compiler for a RISC-y register ISA, and eBPF... just uses (at this point) LLVM for a RISC-y register ISA.
Most notably, the fundamental execution integrity model has, until pretty recently, remained the same --- forward jumps only, limited program size. And that's to me the defining feature of the architecture.
The lineage isn't important to me, so much as the sort of continuous unbroken line from BPF to eBPF, regardless of what LKML says.
[1]: http://citeseerx.ist.psu.edu/viewdoc/download?doi=10.1.1.597...
{kind=link}