VkFFT – Vulkan Fast Fourier Transform library(github.com) |
VkFFT – Vulkan Fast Fourier Transform library(github.com) |
-It now supports sequences up to 2^32 in all dimensions (algorithmically, in reality limited to allocatable memory size, switch to 64-bit addressing scheme is planned for future release)
-configurations optimized for bigger range of systems and vendors
-benchmarked Radeon VII and RTX 3080, shows that FFT is extremely bandwidth limited on modern GPUs
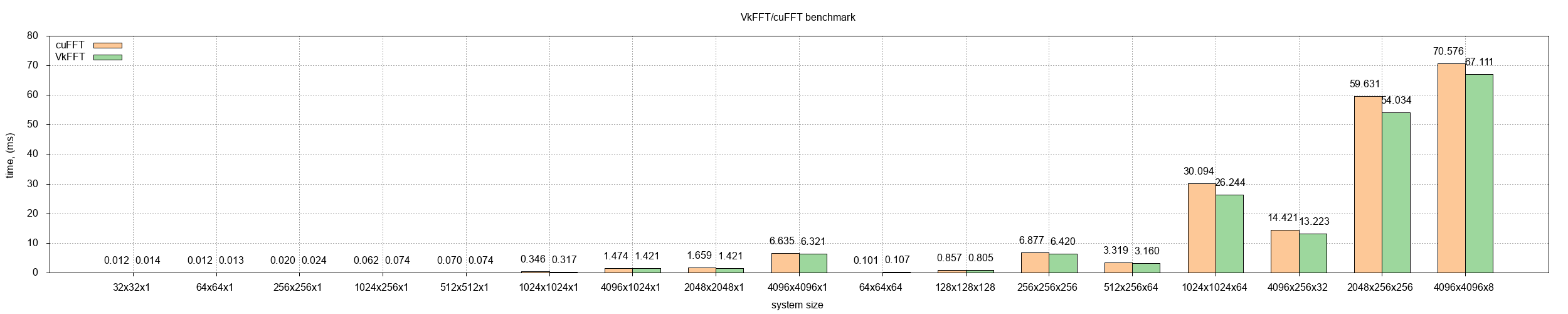
-VkFFT is able to match and outperform cuFFT on the whole tested range from 2^7 to 2^28 in single precision
-added double and half precision support and precision tests against FFTW on CPU
-improved native zeropadding - up to 3x performance boost
-switched license to MPL 2.0
Thanks for your attention! I am happy to answer any questions.
What is your explanation for this?
Is the VkFFT algorithm better? Is SPIR-V fundamentally more expressive than PTX? Are nVidia drivers better at compiling SPIR-V than PTX?
Have you compared the generated GPU assembly from both?
I don't know exactly what cuFFT does differently, but I am fairly certain they use very similar memory layout and algorithms behind their code (judging by execution times only).
What should be the main take from this is that Vulkan allows for similar in performance low-level memory control, while being cross platform and open source. I don't think that SPIR-V is more expressive - bet Nvidia wouldn't allow this. But it doesn't prohibit it from still being good.
Using the single precision at 1k FFT size as my example.
~165,000 kB/ms performance
Converts to 165,000 MB/s performance
Divide by 8 to convert to complex samples, so 20,625 M complex samples per second.
Divide by 1k to get FFT count of ~20.14M FFT/IFFTs per second?
These benchmarks also include transfer time to and from the GPU?
These benchmarks don't include transfers to and from GPU, as those are done with PCI-E bandwidth (30GB/s) which is really slow compared to VRAM-chip bandwidth (>500GB/s). This is why it is important to have enough VRAM and avoid CPU communications as much as possible.
Great to see that!
I expect huge improvements in that area with AMD's new RX series with SAM activated [0].
[0]: https://www.amd.com/en/technologies/smart-access-memory
The Bluestein's algorithm typically used for arbitrary prime sizes requires both zero-padding and convolutions support which are already efficiently implemented, so it is also not completely out of reach.
However, the Vulkan API which is also supported by most vendors (except Apple where you have to use a compatibility layer called MoltenVK) is gaining traction in the compute sector. If you trust the benchmarks, then this library here is showing that you can get a similar performance out of Vulkan compute than what you would expect from CUDA. It is just that this library only provides a very small fraction of the features of what the CUDA ecosystem does, so the Vulkan compute ecosystem still has a lot catching up to do.
Edit: In case it is not obvious from the title, the library is used to calculate the https://en.wikipedia.org/wiki/Fast_Fourier_transform
I think this view is too pessimistic. In fact, support either gets better (Intel oneAPI, Microsoft CLonD3D12, AMD ROCm, Mesa NIR-clover, …) or is unchanged but still maintained (NVIDIA). Moreover, Khronos noticed that OpenCL 2.x was a dead end and was to start over from a point that all vendors could agree on.
Again, I know no C++ and a very limited amount of C, so don’t put to much value in my comment. You seem to be very fond of switch statements, consider not stuffing to much code into each case. It make the flow hard to follow. Break the case code into functions and call those.
You have a switch with 40 cases, to load the SPIR-V. I feel like there’s a better way to deal with that. Maybe just a strict naming convention, so having the ID is enough to locate the file.
Impressive work in anycase.
With Vulkan you write a pipeline, and eventually draw a triangle.
OpenGL "hello triangle" is short only if you cut corners. If you do it the way you'd do in a production app, you're not that far off from the lines of code it takes to do it in Vulkan. It's still less, but on the same order of magnitude.
You wouldn't use Vulkan to render a single triangle for the same reasons why you wouldn't use a helicopter to get a bottle of milk from your local shop.
If you don't need low level control, you should be using middleware or a full blown engine (Godot, Unity, Unreal, etc).
Debugging your first segfault will also make you cry, but it's good for you. It builds character, and prepares you for the more insidious segfaults that are lurking out in the tall grasses.
This kind of "hardcore requirements to render a single triangle" is what is needed if you wish to have AAA game titles with realistic graphics at 60fps as it gives developers the freedom to do anything they wish.
More freedom -> better graphics at higher performance but more difficult to draw a single triangle.
Less freedom -> easier for beginners to draw a triangle but that is irrelevant in practice because that is not what those APIs are for.
Recent version of OpenGL are more difficult. But compared to OpenGL, Vulkan is in an entirely different class of difficulty.
I just like the switches as in glsl(shaders) compiler can optimize and unroll them, if the key is provided as a constant. This can provide a non-negligible algorithm speed increase. So over the course of development I came to the point that it is not hard to follow the switches logic for me.
It's daunting for a beginner but for a seasoned graphics programmer it is fairly straightforward. But still really verbose.
Parts of the industry focused on computing data as opposed to storing it, or retrieving it. Do you think there aren’t people who do this or do you use another word?
You might be more familiar with the habit of referring to "an invite" instead of "an invitation" or "a quote" instead of "a quotation", which fit the same pattern of "compute" instead of "computation". There's even "the big reveal" instead of "the big revelation" - using "revelation" would likely confuse many people, who would assume it was exclusively religious.
I don't know much about OpenCL and this statement confused me. Are you saying that OpenCL 2.x is dead, which seems to contradict what you just said? Unless there's a newer version that isn't dead - is there an OpenCL 3.x? Or is Kronos a code name for OpenCL 3?
> Looking to reset the ecosystem, as the group likes to call it, today Khronos is revealing OpenCL 3.0, the latest version of their compute API. Taking some hard earned (and hard learned) lessons to heart, the group is turning back the clock on OpenCL, reverting the core API to a fork of OpenCL 1.2.
> As a result, everything developed as part of OpenCL 2.x has now become optional: vendors can (and generally will) continue to support those features, but those features are no longer required for compliance with the core specification.
https://www.anandtech.com/show/15746/opencl-30-announced-hit...
Vendors which have had decent OpenCL implementations for a long time (i.e. Intel) will implement oneAPI on top of OpenCL, others will not (if they implement oneAPI at all).
but yeah, I think the default backend switched to level zero recently, so strikethrough the last sentence of my comment - apparently nobody will focus on opencl as a oneAPI backend.
https://github.com/kevinacahalan/piano_waterfall
With his motherboard it was impossible to keep both FFT views scrolling at full speed if they were large. He ended up creating a circular buffer in video memory so that he would be able to reduce the PCIe traffic to just the fresh new edge of the data. The fix doesn't work everywhere. Virtualization seems to break it, including with a Chromebook.
Is VkFFT a reasonable tool for attacking this problem? How difficult might it be to get the FFT result into the needed color component, gamma corrected and scaled, with all the other components?
AFAIK, virtualization software right now has no or very limited access to the GPU, so no extensive graphics can be done through it.
Do you know an application (other than 2-D/3D transforms) where someone would move data from CPU->VRAM then perform a whole bunch of 1-D FFTs on that memory? If any given complex value is only part of only 1-2 FFTs, then PCI-E bandwidth is the limiting factor.
As just a curiosity, why don't FFT benchmarks (CPU/GPU/otherwise) ever simply plot FFTs per second on the y-axis? That's the number we all care about right? It's always bandwidth (with some nuance as you described) or worse, MFLOPs with some arbitrary scaling factor. Fine for relative performance, but if your not comparing it to my platform, its not that useful unless I measure my platform and convert to the same representation.
About using simple time per iteration as a benchmark. I used to have this type of benchmark before the last update (see: https://raw.githubusercontent.com/DTolm/VkFFT/f7c8c45717006c...). As you can see, it is not really that informative, as you can't really compare smaller times to big ones here. The layout I use now doesn't make any assumptions about algorithm yet still provides very informative scaling - just by looking at it it is possible to jusge wether techinques like register overutilization actually work. Another important thing is that it can clearly prove that the problem is bandwidth bound and compare at which size VkFFT/cuFFT swwitch from 1 to 2 and then to 3 stage FFT algorithm. It also allows to detect wether algorithm deviates from predicted result.
{kind=link}