What every programmer should know about SSDs(databasearchitects.blogspot.com) |
What every programmer should know about SSDs(databasearchitects.blogspot.com) |
If you want to go fast & save NAND lifetime, use append-only log structures.
If you want to go even faster & save even more NAND lifetime, batch your writes in software (i.e. some ring buffer with natural back-pressure mechanism) and then serialize them with a single writer into an append-only log structure. Many newer devices have something like this at the hardware level, but your block size is still a constraint when working in hardware. If you batch in software, you can hypothetically write multiple logical business transactions per block I/O. When you physical block size is 4k and your logical transactions are averaging 512b of data, you would be leaving a lot of throughput on the table.
Going down 1 level of abstraction seems important if you want to extract the most performance from an SSD. Unsurprisingly, the above ideas also make ordinary magnetic disk drives more performant & potentially last longer.
In particular, the filesystem tends to undo a lot of the benefits you get from log-structuring unless you are using a filesystem designed to keep your files log-structured. Using huge writes definitely still helps, though.
A paper that I really like goes deeper into this: http://pages.cs.wisc.edu/~jhe/eurosys17-he.pdf
Edit: I had originally said "designed for flash" instead of "designed to keep your files log-structured." F2FS is designed for flash, but in my testing does relatively poorly with log-structured files because of how it works internally.
Edit 2: de-googled the link. Thank you for pointing that out.
In either case, the advice given in the article and by the OP is filesystem agnostic.
In my testing of these ideas, I've been able to push over 2 million transactions per second (~1Kb per transaction) to a Samsung 960 Pro. For reference, its rated for 2.1GB/s sequential writes, so I've got it pretty much 100% saturated.
The implementation for something like this is actually really underwhelming when you figure out how to put all the pieces together. I assembled this prototype (also a key-value store) using .NET5, LMAX Disruptor, and a splay tree implementation i copied from google somewhere. The hardest part was figuring out how to wait for write completion on the caller side (multiple calling threads are ultimately serialized into a single worker thread via the Disruptor). Turns out, busy wait for a few thousand cycles followed by a yield to the OS is a pretty good trick. You just do a while(true) over a completion flag on the transaction object which is set en masse by the handling thread after the write goes to disk. Batch sizes are determined dynamically based on how long the previous batch took to write. In practice, I never observed a batch that took longer than 2-3 milliseconds on my 960 pro. Max batch size is 4096, and it is permanently full when 100% loaded. A full batch = a nice big IO to disk.
I've always been told, "just treat SSDs like slow, permanent memory".
https://www.usenix.org/system/files/conference/inflow14/infl...
> Log-structured applications and file systems have been used to achieve high write throughput by sequentializing writes. Flash-based storage systems, due to flash memory’s out-of-place update characteristic, have also relied on log-structured approaches. Our work investigates the impacts to performance and endurance in flash when multiple layers of log-structured applications and file systems are layered on top of a log-structured flash device. We show that multiple log layers affects sequentiality and increases write pressure to flash devices through randomization of workloads, unaligned segment sizes, and uncoordinated multi-log garbage collection. All of these effects can combine to negate the intended positive affects of using a log. In this paper we characterize the interactions between multiple levels of independent logs, identify issues that must be considered, and describe design choices to mitigate negative behaviors in multi-log configurations.
This is out of pure speculation, but there had to be a period of time during the mass transition to SSDs that engineers said, OK, how do we get the hardware to be compatible with software that is, for the most part, expecting that hard disk drives are being used, and just behave like really fast HDDs.
So, there's almost certainly some non-zero amount of code out there in the wild that is or was doing some very specific write optimized routine that one day was just performing 10 to 100 times faster, and maybe just because of the nature of software is still out there today doing that same routine.
I don't know what that would look like, but my guess would be that it would have something to do with average sized write caches, and those caches look entirely different today or something.
And today, there's probably some SSD specific code doing something out there now, too.
But, fun to read and think about.
Unless you're writing desktop software or your application behaves in a way where you have actually selected the particular hardware components (most of us in cloud hosting don't do this), you probably don't [need to] care.
What every programmer should know about solid-state drives - https://news.ycombinator.com/item?id=9049630 - Feb 2015 (31 comments)
So I think that unless this "every programmer" is a database storage engine developer (not too many of them I guess) their only concern would be mostly - how close my SSD to that magical point where it has to be cloned and replaced before shit hits the fan.
Note though that memory use metrics on MacOS can been a misleading. Make sure that you're seeing what's actually there.
The heavy write bug Apple said was due to misreporting and was fixed ( so they say ).
I do think you should pay attention to it from time to time. iCloud Sync, Spotlight, Safari heavy tabs are all known to cause heavy paging in some corner case. You might end up having a TB of data written for no apparent reason. Apple used to ship their Macbook with MLC, on a 512GB MLC you could do 500TBW without problem, that is ~13 years of usage if you do 100GB write per day. Not sure about the M1 machines.
If you are doing Dev staging, Video and photos editing a lot these drive will fail quite quickly. In the space of 2 - 3 years. Although some would argue MacBook Air are not made for those task. And especially true if you have 8GB and 256GB NAND.
These are all reasons SSDs are much more pleasant to work with than old platter disks.
> A drive can be over-provisioned simply by formatting it to a logical partition capacity smaller than the maximum physical capacity. The remaining space, invisible to the user, will still be visible and used by the SSD controller.
Does the controller read the partition table to decide that the space beyond logic partition is safe to use as scrap?
So if you partition the entire thing, but just never write to the full disk (you never use all the space), that also works as overprovisioning.
Partitioning just forces that to happen.
Near the beginning they talk about how targeting the PlayStation 5, which has an SSD, drastically changed how they went about making the game.
In short, the quick data transfer meant they were CPU bound rather than disk bound and could afford to have a lot of uncompressed data streamed directly into memory with no extra processing before use.
And where did the word "drive" come from? I thought it referred to motors that spin the media, which SSDs also do not have.
The actual physical address on the storage chip and the physical address from the operating system's perspective don't have much to do with another. For harddrives, "un-partitioned space" means that there is a physical "chunk of metal" that is unused.
However, that's not the case for SSDs. SSDs dynamically remap "OS-physical" block numbers to whatever they want. (Preferably addresses that have never been used before or that have been discarded/trimmed. If there aren't any available, perhaps to the address that was previously used for the same block number.)
I'm replying to the whole of comments on this article. The write amplification problem goes up as the number of "free" sectors/blocks goes down. Many solutions have been presented that don't allocate X% of the hard drive... but I'm not sure than any of them let the hard drive's SSD controller know they aren't allocated.
For that to happen, the OS has to have TRIM support, AND the block in question has to be on a volume that the OS is managing.
My worry is that if you have a blank partition, it's not being actively managed by anything, and thus isn't going to be TRIMed, and thus the SSD doesn't know the blocks are free for use.
Thus, leaving an unpartitioned area isn't going to help.
However, random read performance is only somewhere between a 3rd to half as fast as sequential compared to a magnetic disk where it's often 1/10th as fast.
I suspect it has something to do with prediction on the controller but I'm also not confidently spewing a bunch of bullshit about drive architecture unlike this article.
The numbers involved was insane and I played with various scenarios, with/without compression (MessagePack feature), with/without typeless serializer (MessagePack feature), with/without async and then the difference between using sync vs async and forcing disk flushes. I also weighed the difference between writing 1 fat file (append only) or millions of small files. I also checked the difference between using .net streams versus using File.WriteAllBytes (C# feature, an all-in-memory operation, good for small writes, bad for bigger files or async serialization + writing). I also played with the amount of objects involved (100K, 1M, 10M, 50M).
I cannot remember all the numbers involved, but I still have the code for all of it somewhere, so maybe I can write a blogpost about it. But I do remember being utttterly stunned about how fast it actually was to freeze my application state to disk and to thaw it again (the class name was Freezer :p).
The whole reason was, I started using Zfs and read up a bit about how it works. I also have some idea about how ssd's work. I also have some idea how serialization works and writing to disk works (streams etc).. I also have a rough idea how mysql, postgres, sql server save their datafiles to disk and what kind of compromises they make. So one day I was just sitting being frustrated with my data access layers and it dawned on me to try and build my own storage engine for fun, so I started by generating millions of objects that sits in memory, which I then serialized with MessagePack using a Parallel.Foreach (C# feature) to a samsung 970 evo plus to see how fast it would be. It blew my mind and I still don't trust that code enough to use it in production but it does work. Another reason why I tried it out, was because at work we have some postgres tables with 60m+ rows that are getting slow and I'm convinced we have a bad data model + too many indexes and that 60m rows are not too much (since then we've partitioned the hell out of it in multiple ways but that is a nightmare on its own since I still think we sliced the data the wrong way, according to my intuition and where the data has natural boundaries, time will tell who was right).
So I do believe there is a space in the industry where SSD's, paired with certain file systems, using certain file sizes and chunking, will completely leave sql databases in the dust, purely by the mechanism on how each of those things work together. I haven't put my code out in public yet and only told one other dev about it, mostly because it is basically sacrilege to go against the grain in our community and to say "I'm going to write my own database engine" sounds nuts even to me.
it's really about linking to the tutorial and papers it links at the end, which is some thing from 2014
And that was discussed here 6 years ago: https://news.ycombinator.com/item?id=9049630
I'd be more interested in the trends in SSD behaviour are. It seems SSDs have bigger and bigger DRAM caches and wear ceased to be an issue many years ago, so there's not much payoff in the write side advice of the article.
On a Windows server we were having SSD performance issues where sequential reads were often down to 100MB/s, it was kind of confusing but we tried all sorts of ways to copy it with the same result. I eventually tested the drive with a fragmentation tool and it was really high at 80% but most importantly the problem files had so many fragments that they were tending towards 4k IO reads.
What I did was remove all the files to another drive, force trimmed the drive and gave it several hours to sort itself out and then copied them back and performance was restored to 550MB/s as would be expected.
I wrote a quick go program to test sequential read speed of all files across all the drives and I found plenty of files where performance was degraded. This was across a range of SSDs I had, SATA and NVMe from differing vendors. I suspect this is a bigger problem than most people realise, normal use absolutely can get the drive into a bad performing state and trim wont fix it. Very few people expect that the drive will degrade down to its 4K IO speed on a sequential copy but it apparently can.
The canonical case is minimize time to load a level. Keep that level’s assets contiguous. And maybe duplicate data that is shared across levels. It’s a trade off between disc space and load time.
I’m not familiar with major tricks for improving after a disc is installed to drive. (PS4 games always streamed data from HDD, not disc.)
Even consoles use different HDD manufacturers. So it’d be pretty difficult to safely optimize for that. I’m sure a few games do. But it’s rare enough I’ve never heard of it.
I've turned on plenty of cell phones that hadn't been charged or powered on for a couple of years and everything worked normally. Same with thumb drives I've picked up after years.
I mean, anything can fail after three months. Your statement doesn't really add anything without stating the failure rates. For all I know the failure rate could be less than that of physical hard drives.
Outside of that narrow scenario, the three months figure is wildly wrong and should not be repeated. Lower temperatures, a consumer drive, and not having used up 100% of the write endurance will all drastically lengthen data retention.
(However, under no circumstances should you trust a cheap USB thumb drive to retain your data. Those tend to use lower-grade flash memory and lower-quality controllers. If you need an external device to reliably cart around data, shop for a "portable SSD", not a "USB flash drive".)
Then there's the matter of how much data is in the queue, rather than how many commands are queued. Imagine a 4 TB SSD using 512Gbit TLC dies, and an 8-channel controller. That's 64 dies with 2 or 4 planes per die. A single page is 16kB for current NAND, so we need 2 or 4 MB of data to write if we want to light up the whole drive at once, and that much again waiting in the queue to ensure the drive can begin the next write as soon as the first batch completes. But you can often hit a bottleneck elsewhere (either the PCIe link, or the channels between the controller and NAND) before you have every plane of every die 100% busy.
If you're working with small files, then your filesystem will be producing several small IOs for each chunk of file contents you read or write from the application layer, and many of those small metadata/fs IOs will be in the critical path, blocking your data IOs. So even though you can absolutely hit speeds in excess of 3 GB/s by issuing 2MB write commands one at a time to a suitably high-end SSD, you may have more difficulty hitting 3 GB/s by writing 2MB files one at a time.
Typically the SSDs with DRAM have a ratio of 1GB DRAM per TB of flash.
SLC caching is using a portion of the flash in SLC mode, where it stores 1 bit per cell rather than the typical 2-4 (2 for MLC, 3 for TLC, 4 for QLC) in exchange for higher performance. SLC cache size varies wildly. Some SSDs allocate a fixed size cache, some allocate it dynamically based on how much free space is available. It can potentially be 10s of GBs on larger SSDs.
Although they started removing it entirely for NVMe SSDs, I guess the direct transfer speed is enough to not need a cache at all.
Drives that include less than this amount of DRAM show reduced performance, usually in the form of lower random read performance because the physical address of the requested data cannot be quickly found by consulting a table in DRAM and must be located by first performing at least one slow NAND read.
I encourage anyone to go write their own little storage engine for fun. It will force you think about IO, Parallelization, Serialization, Streams, and backwards compatibility.
It is really fun (and not even that hard) and even if it works I still recommend against using it in production, but it will help take some of the magic away on how databases work and reveal the real challenge. The real difficult part for me comes from building a query language, parser and optimizer (like sql) and to handle concurrent writes properly. It is still difficult for me to comprehend how something like a sql query string gets converted into instructions that pull data out of a single file (say sqlite file), where that file's structure on disk can be messy and unknowable upfront when sqlite gets compiled. You essentially have a dynamic data structure and you are able to slice & order the data however you want, it is not known at compile time with hard-coded rules. So I think in that regard sql adds a ton of value. So sqlite is still my go to for most flat-file scenarios.
Remaining non-native apps include Dropbox, Spotify, LibreOffice and a few others. And basically all games with very few exceptions.
This website has a decently up-to-date list of what has been ported and what hasn't: https://isapplesiliconready.com/
There was a time where people thought of hard drives as "just random access storage" and consequently "there is little to worry about" and "unoptimized workloads are always going to work better on SSDs". Yup, SSDs are way faster than what came before them, but that if anything tends to mean that data structures & algorithms that used to make sense might not make much sense any more.
It it is also worth noting that many SSD's are over-provisioned by the manufacture anyway, in those drives manual over-provisioning might achieve very little anyway.
It runs periodically and lets the SSD know about unused areas.
So as long as you don't fill up the drive and let trim do its thing the unused areas effectively do the same thing as over provisioning.
The easiest way to achieve this is to create a partition with no filesystem, and use blkdiscard or similar to trim the LBAs corresponding to that partition.
Deleted pages and obsolete pages are actively put back into a free list (tracked by another b+tree), which will be reused for new page allocation. This avoids the long garbage collection phase to walk all the live pages for compaction (no vacuum is needed).
Looks like you have the other details right.
So, you've got firmware that is pretending you've got 512B/4kB chunks when really you have 16kB, and anticipating how the other layers might be doing things in order to maximize performance.
Then you have a filesystem/VFS layer, which tries to optimize its access patterns anticipating how the underlying solid state storage might be really doing things in 16kB sizes and how it might be optimizing 512KB & 4kB accesses to fit that.
Both those layers are dealing with filesystem journaling and how that might impact performance.
Then you might have a database, which is now trying to anticipate how the filesystem and the underlying firmware might be optimizing access patterns, and so it's trying to optimize to fit all that.
You also potentially have application logic that is trying to anticipate how the database might do things...
What you tend to end up with are many layers of redundant caching that are all working against each other in a very inefficient manner.
The only open SSD platform I've read about is http://openssd.io/ but I've never played with it. One of the challenges is the NAND manufacturers a lot of the critical documentation under an NDA these days. You really need that information to make a reliable SSD. When you learn how the internals of an SSD work, its a wonder that it retains data at all!
In terms of integrating SSD with the higher software level, I believe FusionIO was doing this in the past. They put the whole logical to physical mapping into the host memory.
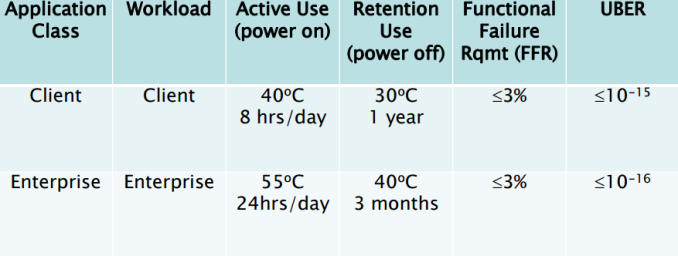
> It depends on the how much the flash has been used (P/E cycle used), type of flash, and storage temperature. In MLC and SLC, this can be as low as 3 months and best case can be more than 10 years. The retention is highly dependent on temperature and workload.
Are there any modern sources provide more accurate stats? "3 months to 10 years" is so vague as to be useless.
To achieve that target, when they are new they must have a retention time of a few years, but you should better not count on that.
And the linked article makes clear it's not a worry at all. Key part:
> All in all, there is absolutely zero reason to worry about SSD data retention in typical client environment. Remember that the figures presented here are for a drive that has already passed its endurance rating, so for new drives the data retention is considerably higher, typically over ten years for MLC NAND based SSDs...
Average users virtually never pass the endurance rating, so @teddyh's claim seems awfully sensationalistic.
I originally got the “three months” figure from the Dell document, which I got from here on HN: https://news.ycombinator.com/item?id=24229864#24232844
For example, way back in the day, to get more life out of my laptop during college, I configured the kernel to only write to disk once an hour or when the buffer filled up. That effectively meant I was only writing to disk once per hour when I shut down to change classes.
The modern linux kernel doesn't actually write to disk when fsync is called. It buffers the writes in a cache. Also, the SSD itself has a cache.
There are lots of abstractions between SQLite and the disk.
Source for this? This seems to be contradicted by the man page for fsync
https://man7.org/linux/man-pages/man2/fdatasync.2.html
fsync() transfers ("flushes") all modified in-core data of (i.e.,
modified buffer cache pages for) the file referred to by the file
descriptor fd to the disk device (or other permanent storage
device) so that all changed information can be retrieved even if
the system crashes or is rebooted. This includes writing through
or flushing a disk cache if present. The call blocks until the
device reports that the transfer has completed.
Sounds great until you get a kernel panic or random shutdown, in which case you potentially get file corruption and/or data loss.
Do you have a reference for this? That would break every ACID database that I'm aware of, including sqlite and postgresql. There has been a lot of work in the last few years to fix data durability issues with fsync (e.g. https://lwn.net/Articles/752063/), so I would be very surprised to hear that fsync is now a no-op.
> The modern linux kernel doesn't actually write to disk when fsync is called.
This is false.
Almost all open source databases' durability guarantees are based upon fsync (including SQLite, Postgres, MySQL, and so on). fsync will result in the corresponding underlying storage flush commands. You configure Linux to ignore fsync, but this is is not the default, on any Linux distribution I'm aware of. It would not make any sense.
That's not true, you can tell in many ways but one of the easiest is because fsync is quite slow and noisy (on hard drives).
I feel that operating systems need to provide self-contained reliable APIs designed for atomically overwriting configuration files, without losing permissions or overwriting symlinks or such. Or perhaps supply more powerful primitives, like a faster/weaker fsync that serves as an ordering barrier rather than flushing to disk, or an API to replace a file without altering permissions. One issue I've heard is:
> I even had an issue with atomic writes over ssh that created the temp file but where not able to rename it, so the old one stayed.
manhandling /dev/nvme0 seems equally likely to corrupt data in the event of a power failure.
Doesn’t mean it isn’t easier to deal with as a file from an administration perspective (and you can do snapshots, or whatever!), but Lvm can do that too for a block device, and many other things.
Do you have numbers showing an advantage of going directly to the block device? Personally, I'd consider the management advantages of a filesystem compelling absent specific performance numbers showing the benefit of direct partition access.
I'm able to saturate a PCIe 3.0 x4 link doing direct IO to an NVMe drive with a single 1.7 GHz Power PC core without breaking a sweat. This is through ext4.
My accesses are sequential though. Maybe there's more of a penalty with random IO.
[0] https://www.ign.com/articles/fortnites-latest-patch-makes-it...
If that really is cause and effect, that's a bit disappointing. For any game that isn't assuming you have an ultra-fast SSD, normal CPU decompression can handle things quite well. Such a hard nudge shouldn't have been necessary.
The hardware decompression acceleration in new consoles doesn't exactly make it easier to use compression for the game assets. Rather, it makes it practical to load compressed assets on-demand instead of reading and decompressing into RAM during the loading screen.
Well, we can point to fortnite up there, but also a very large fraction of the games I have on steam can be shrunk by a third just by applying filesystem-level compression, despite it using weak algorithms and small blocks. I'm sure there's compression involved, but it's not even meeting a minimum bar of competency.
Since you get most of the same advantages management wise with lvm while using the block interface (including snapshots, resizing, and all the other management goodies), you’re not exactly getting much extra functionality either.
Do you have numbers or not?
Since most of what we’re talking about is unnecessary complexity for no real gain, what concrete metric do you think would be useful exactly? I just pointed out that you can get the same management advantages without it (say for a dev environment or rollbacks or whatever). And you get a simpler, cleaner story without extra layers if you don’t want to use lvm (such as in production), which you can’t get from O_DIRECT.
I also have this thread from Linus calling O_DIRECT brain damaged and to never use it. [https://lkml.org/lkml/2007/1/10/233]
If we make the reasonable assumption that this subthread is discussing a server use case, then we can assume that the SSD is tolerant of power failures and has the capacitors necessary to finish any cached writes it has reported as complete. Thus, having fewer layers between the hardware and the application means there are fewer opportunities for some layer to lie to those above it about whether the data has made it to persistent storage.
Whether or not you're bypassing large parts of the operating system's IO stack, the application needs to have a clear idea of what data needs to be flushed to persistent storage at what times in order to properly survive unexpected power loss without unnecessary data loss or corruption.
A storage application that need to bypass the filesystem will already be implementing its own caching system anyways. The idea is to persist the data to maintain durability without sacrificing latency.
> manhandling /dev/nvme0 seems equally likely to corrupt data in the event of a power failure.
That is what O_SYNC flag is for.
On PostgreSQL create an adequately-caped tmpfs, create a TABLESPACE on it, then store temporary tables into this TABLESPACE. No SSD (I have access to) beats this. Hint: before shutting PG down you may DROP this TABLESPACE.
It also is useful for a blockchain, amazingly fast (and a relief for HDDs), in most cases alleviating the need for a SSD. Place the blockchain file(s) on the tmpfs mount. Before machine shutdown stop any blockchain-using software, then store a compressed copy of the blockchain file(s) on permanent storage (I use "zstd -T0 --fast"...), and upon reboot restore it on the tmpfs mount. If anything fails the blockchain-writing software will re-download any missing block.
The main problem is that copying a file to tmpfs will drop extended attributes. Old versions of tmpfs dropped all extended attributes, modern versions of tmpfs keep some security-related extended attributes, but they still drop any user-defined extended attributes.
Old versions of tmpfs truncated some high-resolution timestamps, e.g. those coming from xfs, but I do not know if this still happens on modern versions of tmpfs.
Before learning these facts, I could not understand while some file copies lost parts of their metadata, after being copied via /tmp between 2 different users, on a multi-user computer where /tmp was mounted on tmpfs.
Now that I know, when I have to copy a file via tmpfs, I have to make a pax archive, which preserves file metadata. Older tar archive formats may have the same problems like tmpfs.
Postgres temp tables on ramdisk are a problem for a different reason, the WAL, as pointed to by a sibling comment.
https://www.2ndquadrant.com/en/blog/postgresql-no-tablespace...
See https://www.postgresql.org/message-id/CAB7nPqTkZvESuZ3qcN_Tj...
TEMPORARY tables are UNLOGGED, and therefore they aren't WALed
{kind=link}