Six Years of Professional Clojure(engineering.nanit.com) |
Six Years of Professional Clojure(engineering.nanit.com) |
> To understand a program you must become both the machine and the program.
- Epigrams in Programming, Alan Perlis
Two of the big advantages of (gradually-) typed languages are communication (documentation) and robustness. These can be gained back with clojure spec and other fantastic libraries like schema and malli. What you get here goes way beyond what a strict, static type systems gets you, such as arbitrary predicate validation, freely composable schemas, automated instrumentation and property testing. You simply do not have that in a static world. These are old ideas and I think one of the most notable ones would be Eiffel with it's Design by Contract method, where you communicate pre-/post-conditions and invariants clearly. It speaks to the power of Clojure (and Lisp in general) that those are just libraries, not external tools or compiler extensions.
The current crop of statically typed languages (from the oldest ones, e.g. C#, to the more recent ones, e.g. Kotlin and Rust) is basically doing everything that dynamically typed languages used to have a monopoly on, but on top of that, they offer performance, automatic refactorings (pretty much impossible to achieve on dynamically typed languages without human supervision), fantastic IDE's and debuggability, stellar package management (still a nightmare in dynamic land), etc...
Only if you are skimping on tests. There's a tradeoff here - "dynamically typed" languages generally are way easier to write tests for. The expectation is that you will have plenty of them.
Given that most language's type systems are horrible (Java and C# included) I don't really think it's automatically a net gain. Haskell IS definitely a net gain, despite the friction. I'd argue that Rust is very positive too.
Performance is not dependent on the type system, it's more about language specification (some specs paint compilers into a corner) and compiler maturity. Heck, Javascript will smoke many statically typed languages and can approach even some C implementations(depending on the problem), due to the sheer amount of resources that got spent into JS VMs.
Some implementations will allow you to specify type hints which accomplish much of the same. Which is something you can do on Clojure by the way.
Automatic 'refactorings' is also something that's very language dependent. I'd argue that any Lisp-like language is way easier for machines to process than most "statically typed" languages. IDEs and debugability... have you ever used Common Lisp? I'll take a condition system over some IDE UI any day. Not to mention, there's less 'refactoring' needed.
Package management is completely unrelated to type systems.
Rust's robust package management has more to do with it being a modern implementation than with its type system. They have learned from other's mistakes.
Sure, in a _corporate_ setting, where you have little control over a project that spans hundreds of people, I think the trade-off is skewed towards the most strict implementation you can possibly think of. Not only type systems, but everything else, down to code standards (one of the reasons why I think Golang got popular).
In 2021, I would expect people to keep the distinction between languages and their implementations.
My conclusion is that it's a matter of personal preference honestly. Those are all really good languages. Personally I have more fun and enjoy using Clojure more. I would say I tend to find I'm more productive in it, but I believe that's more a result of me finding using it more enjoyable then anything else.
I don't pick Clojure for its dynamic typing, I pick it for other reasons. I've tried Haskell but it really doesn't seem to mesh with the way I tend to develop a program. But I would love to have more static languages with the pervasive immutability of Clojure.
...are we talking about the thing pioneered by Smalltalk's Refactoring Browser?
Oh man. This is the fundamental disagreement. Sure, you can have a type system that is never wrong in its own little world. But, that's not the problem. A lot of us are making a living mapping real world problems into software solutions. If that mapping is messed up (and it always is to some degree) then the formal correctness of the type system doesn't matter at all. It's like you got the wrong answer really, really right.
Yes this is the fundamental tradeoff. Specs et al are undoubtedly more flexible and expressive than static type systems, at the expense of some configurable error tolerance. I don't think one approach is generally better than the other, it's a question of tradeoffs between constraint complexity and confidence bounds.
It is a design decision to be able to build a clojure system interactively while it is running, so a runtime type checker is a way for the developer to give up the safety of type constraints for this purpose—by using the same facility we already need in the real world, a way to check the structure of data we can’t anticipate.
You just don't get an interpreter/compiler and have to sort everything else by yourself, no, there is a full stack experience and development environment.
Is this refinement types, which most static languages provide? https://en.wikipedia.org/wiki/Refinement_type
> freely composable schemas,
My understanding is that you can compose types (and objects) https://en.wikipedia.org/wiki/Object_composition
I'm assuming that types are isomorphic with schemas for the purposes of this discussion.
> automated instrumentation
I know that C# and F# support automated instrumentation/middleware.
> and property testing. You simply do not have that in a static world.
QuickCheck has entered the chat: https://en.wikipedia.org/wiki/QuickCheck
Well it does include that kind of behaviour but it's quite a bit more than just that. E.g. you could express something like "the parameter must be a date within the next 5 business days" - there's no static restriction. I'm not necesarily saying you should but just to give an illustrative example that there's less restrictions on your freedom to express what you need than in a static system.
>> types are isomorphic with schemas
I don't think that's a good way to think of this, you're imagining a rigid 1:1 tie of data and spec yet i could swap out your spec for my spec so that would be 1:n but those specs may make sense to compose in other data use cases so really it's m:n rather than 1:1
With "freely composable" I mean that you can program with these schemas as they are just data structures and you only specify the things you want to specify. Both advantage and the disadvantage is that this is dynamic.
An even better example of this would be Excel, the horror stories are almost incredible.
So even if your environment is dynamic, you want clarity when you made a mistake. Handling errors gracefully and hiding them are very different things. The optimal in a dynamic world is to facilitate reasoning while not restricting expression.
Eg, spec can warn you when an argument doesn't make sense relative to the value of a second argument. Eg, with something like (modify-inventory {:shoes 2} :shoes -3) spec could pick up that you are about to subtract 3 from 2 and have negative shoes (impossible!) well before the function is called - so you can test elsewhere in the code using spec without having to call modify-inventory or implement specialist checking methods. And a library author can pass that information up the chain without clear English documentation and using only standard parts of the language.
You can't do that with defrecord, but it is effectively a form of documentation about how the arguments interact.
I like a REPL for testing things out, or for doing quick one-off computations, but that's it. I would never want to, say, redefine a function in memory "while the code is running". Not just because of ergonomics, but because if I decide to keep that change, I now have to track down the code I typed in and manually copy it back over into my source files (assuming I can still find it at all). And if I make a series of changes over a session, the environment potentially gets more and more diverged from what's in sourced if I forget to copy any changes over. So I'd often want to re-load from scratch anyway, at least before I commit.
Am I missing something? Am I misunderstanding what people mean when they talk about coding from a REPL?
You also can get an experience like PHP, where you just have to change and save some files, and your subsequent requests will use the new code. This is so much better than shutting down everything and restarting and is a large part of why CGI workflows dominated the web.
Common Lisp takes these experiences and dials them to 11, the whole language is built to reinforce the development style of dynamic changes, rather than an after-thought that requires a huge IDE+proprietary java agent. It's still best to use some sort of editor or IDE, and then you don't have any worry about source de-syncs -- frequently you'll make multiple changes across multiple files and then just reload the whole module and any files that changed with one function call, which you might bind to an editor shortcut, but crucially like debugging is not centrally a feature of the editor but the language; the language's plain REPL by itself is just a lot more supportive of interactive development than Python/JS/Ruby's. Clojure, and I personally think even Java with the appropriate tools, are between Python and CL for niceness of interactive development, but Clojure tends to be better than the Java IDE experience because of its other focus on immutability.
One of the best parts about lisp style repl development is that you end up doing TDD automatically. You just redefine a function until it does what you want from sample data you pass in - without changing files or remembering how your test framework works. You can save the output of some http call in a top level variable and iterate on the code to process it into something useful. The code you evaluate lives in the file that will eventually house it anyway so it’s pretty common to just eval the entire file instead of just one function.
Since you don’t ever shut the repl down, developing huge apps is also quite pleasant. You only reload the code that you’re changing - not the rest of the infra so things like “memoize” can work in local development. That’s why it’s a bit closer to your bash shell in other languages.
If you’ve never tried it, I highly recommend trying the Clojure reloaded workflow [1] to build a web app with a db connection. You can really get into a flow building stuff instead of waiting for your migrations to run on every test boot.
[1] https://cognitect.com/blog/2013/06/04/clojure-workflow-reloa...
That reads like what someone would think when they used the typesystem of Java 6 and now think that this is what "statically typed programming" means.
No, you can _not_ get back what types give you by any kind of spec - if anything you can get some of the benefits of types, but you also pay a price.
The thing is - dynamically typed languages don't really seem to evolve anymore. They add a bit of syntatic sugar here and there and sometimes add some cool feature, but mostly only features that already existed for a long time in other languages. At least that is what I have seen over the past couple of years, I would be happy to be proven wrong.
Looking at statical typesystems however, there is much more progress, simply because they are much more complex and not as optimized. From row-types over implicits and context-expressions towards fully fledged value-dependent typesystems, which have amazing features that start to slowly trickle down into mainstream languages like Typescript or Scala.
While both dynamically and statically typed languages have their pros and cons and it will stay like that forever, I expect that statically typed languages will proceed to become the bigger and bigger piece of the cake, simply because they have more potential for optimizations going forward.
I keep seeing lisp people bandy about all of this design by contract/arbitrary predicate validation stuff. Can you give an example of an instance in which static types + runtime checks don't completely subsume this?
My intuition is that almost all of these methods people are talking about would have to be enforced at run-time, in which case I don't see how it's providing anything fundamentally more than writing an assertion or a conditional.
Why static typing makes those things impossible?
I should have made clear that I'm emphasizing the advantages of being dynamic to describe and check the shape of your data to the degree of your choosing. Static typing is very powerful and useful, but writing dynamic code interactively is not just "woopdiedoo" is kind of the point I wanted to make without being overzealous/ignorant.
In an OOP language, types are hugely important, because the types let you know the object's ad-hoc API. OOP types are incredibly complicated.
In lisps, and Clojure in particular, your information model is scalars, lists, and maps. These are fully generic structures whose API is the standard Clojure lib. This means that its both far easier to keep the flow of data through your program in your head.
This gives you a 2x2 matrix to sort languages into, static vs dynamic, and OOP vs value based.
* OOP x static works thanks to awesome IDE tooling enabled by static typing
* value x static works due to powerful type systems
* value x dynamic works due to powerful generic APIs
* OOP x dynamic is a dumpster fire of trying to figure out what object you're dealing with at any given time (looking right at you Python and Ruby)
CLOS is "OOP x dynamic".
Common Lisp has arrays, structures and stack allocation.
IDE were invented from Smalltalk and Lisp development experience.
But then you get to Clojure proper, and you run into additional syntax that either convention or functions/macros that look like additional syntax.
Ok, granted, -> and ->> are easy to reason about (though they look like additional syntax).
But then there's entirely ungooglable ^ that I see in code from time to time. Or the convention (?) that call methods on Java code (?) with a `.-`
Or atoms defined with @ and dereferenced with *
Or the { :key value } structure
There's way more syntax (or things that can be perceived as syntax, especially to beginners) in Clojure than the articles pretend there is.
(defn ^:export db_with [db entities]
(d/db-with db (entities->clj entities)))
(defn entity-db
"Returns a db that entity was created from."
[^Entity entity]
{:pre [(de/entity? entity)]}
(.-db entity))
(defn ^:after-load ^:export refresh []
(let [mount (js/document.querySelector ".mount")
comp (if (editor.debug/debug?)
(editor.debug/ui editor)
(do
(when (nil? @*post)
(reset! *post (-> (.getAttribute mount "data") (edn/read-string))))
(editor *post)))]
(rum/mount comp mount)))I learned to code in Python. Loved it. Dynamically typed dicts up the wazoo!
Then I learned why I prefer actual types. Because then when I read code, I don't have to read the code that populates the dicts to understand what fields exist.
If we don’t get some big companies to take on this roll the language is going nowhere.
I’m saying this because I’m a huge fan of Clojure (as a syntax and language, not crazy about the runtime characteristics) and I hope I get the opportunity to use it.
- Cisco - has built their entire integrated security platform on Clojure
- Walmart Labs and Sam's club - have some big projects in Clojure
- Apple - something related to the payment system
- Netflix and Amazon, afaik they use Clojure as well
even NASA uses Clojure.
I think the language "is going somewhere"...
[1] https://eli.thegreenplace.net/2017/notes-on-debugging-clojur...
[2] https://cognitect.com/blog/2017/6/5/repl-debugging-no-stackt...
I have had the pleasure of contributing to their code since we used their product at a previous company I worked at, and I must say I am sold on Clojure. Definitely a great language to have in your toolbox.
You should try deeper profiling tools like JFR+JMC (http://jdk.java.net/jmc/8/) and MAT (https://www.eclipse.org/mat/).
Then wait a bit, right click it again, and select "Dump JFR"
What you get is a Flight Record dump that contains profiling information you can view that's more comprehensive than any language I've ever seen.
I used this for the first time the other day and felt like my life has been changed.
Specifically, if you want to see where the application is spending it's time and in what callstacks, you can use the CPU profiling and expand the threads -- they contain callstacks with timing
There's some screenshots in an issue I filed here showing this if anyone if curious what it looks like:
https://github.com/redhat-developer/vscode-java/issues/2049
Thanks Oracle.
It didn't feel like a first class experience.
That's because that's not how Clojure developers normally work. You don't do changes and then "run the program". You start your REPL and send expressions from your editor to the REPL after you've made a change you're not sure about. So you'd discover the missing argument when you call the function, directly after writing it.
The other one is just getting good at the REPL and inspecting the implementation for functions to quickly see what keys and all they make use of.
Something the article didn't really cover either is that it's not really the lack of static type checking that's the real culprit, its the data-oriented style of programming that is. If you modeled your data with generic data-structures even in Haskell, Java, C# or any other statically typed language, you'd have the same issue.
If Clojure used abstract data-types (ADTs) like is often the case in statically typed languages, things would already be simpler.
(defrecord Name [first middle last])
(defn greet
[{:keys [first middle last]
:as name}]
(assert (instance? Name name))
(println "Hello" first middle last))
(greet (->Name "John" "Bobby" "Doe"))
(defn greet
[{:keys [first middle last]
:as name}]
(println "Hello" first middle last))
Ummm... I am a little bit fearful about your codebase.
If you don't see the need for designing your FP system it probably mostly means it is being designed ad hoc rather than explicitly.
If you are trying to compare to OOP system done right, you will notice that this includes a lot of work in identifying domain model of your problem, discovering names for various things your application operates on, and so on. Just because you elect to not do all of this doesn't mean the problem vanishes, it most likely is just shifted to some form of technical debt.
> Clojure is a dynamic language which has its advantages but not once I stumbled upon a function that received a dictionary argument and I found myself spending a lot of time to find out what keys it holds.
Dynamic typing is a tradeoff which you have to be very keenly aware of if you want to design a non-trivial system in a dynamically typed language.
It is not a problem with Clojure, it is just a property of all dynamically-typed languages.
Why does FP seem to imply that things are designed ad hoc rather than with purpose? I've been working exclusively with FP codebases for the last 5 year, and all designs have been by identifying the domain model and implement it with purpose, with a plan.
> includes a lot of work in identifying domain model of your problem
FP does not exclude creating a domain model of your problem, discovering names and so on, not sure why you think so? Love to hear the reasoning behind this view you have.
To reiterate my point: whether OOP or FP you still need to invest time researching, understanding and writing down domain model and designing your application.
And if you don't, the problem doesn't go away and instead hides in some form of technical debt.
This seems to be the case for the author's open-source work (https://github.com/nanit/kubernetes-custom-hpa/blob/master/a...)
If I find myself having to repeat myself justifying a certain decision time and time again, it's an indicator that the decision needs to be revised to be something which is a more intuitive fit for the organization.
{:pre [(de/entity? entity)]}
(hash-map (keyword "pre") (vector (de/entity? entity)))
(.getAttribute mount "data")
Finally,
@*post
(deref *post)
Most of what you believe to be syntax are convenience "reader macros" (https://clojure.org/reference/reader), and you can extend with your own. You can write the same code without any of it, but then you'll have more "redundant" parenthesis.
And yet, you need to know what all those ASCII symbols mean, where they are used, and they are indistinguishable from syntax.
Moreover, even Clojure documentation calls them syntax. A sibling comment provided a wonderful link: https://clojure.org/guides/weird_characters
Usually this is made worse by bespoke build tools and optimizations that make the system punishing to pick up.
"Normal language"?
You mean, whatever language is most popular at the company. What's "normal" at one would be completely alien at another. Even things like Java. If you don't have anything in the Java ecosystem, the oddball Java app will be alien and will likely get rewritten into something else.
The reason Clojure remains niche is that some people somehow think it's not a "normal" language, for whatever reason.
What clojure really needs is some kind of opinionated framework or starter template, something like create-react-app. That has all these things figured out so a beginner like me can start playing with actual clojure, which documents all the steps to setup the repl and editor and what not. The last time I asked for this I was told about lein templates, they help but there's no documentation to go with those.
There needs to be some push from the top level. create-react-app was produced by facebook. Elm reactor (which lets you just create a .elm file and play with elm) was created by Evan the language creator himself.
tldr: There's a huge barrier to start playing with clojure that needs to come down and the push needs happen from the top level.
The advantage is that maps are extensible. So, you can have middleware that e.g. checks authentication and authorization, adds keys to the map, that later code can check it directly. Namespacing guarantees nobody stomps on anyone else's feet. Spec/malli and friends tell you what to expect at those keys. You can sort of do the same thing in some other programming languages, but generally you're missing one of 1) typechecking 2) namespacing 3) convenience.
[0]: spec-ulation keynote from a few years ago does a good job explaining the tradeoffs; https://www.youtube.com/watch?v=oyLBGkS5ICk
IIRC, the preference for complecting things via maps, and then beating back the hordes of problems with that via clojure.spec.alpha (alpha2?) is a Hickey preference. I don't recall exactly why.
Not wanting to misquote the above / Rich himself I would TLDR it to:
- flexibility of data manipulation
- resilience in the face of a changing outside world
- ease of handling partial data or a changing subset of data as it flows through your program
Please note that no one (I hope) is saying that the above things are impossible or even necessarily difficult with static typing / OOP. However myself and other clojurists at least find the tradeoff of dynamic typing + generic maps in clojure to be a net positive especially when doing information heavy programming (e.g. most business applications)
TBH I've never understood the attraction of the untyped dict beyond simple one-off hackups (and even there namedtuples are preferable), because like you say you typically have no idea what's supposed to be in there.
2. Assuming you don’t know the answer to that question, will the type system you use be able to tell you the answer to that question?
This is a pretty simple constraint one might want (a constraint that only certain requests have a body) but already a lot of static type systems (e.g. the C type system) cannot express and check it. If you can express that constraint, is it still easy to have a single function to inspect headers on any request? What about changing that constraint in the type system when you reread the spec? Is it easy?
The point isn’t that type systems are pointless but that they are different and one should focus on what the type system can do for you, and at what cost.
2. Sure. The request type has a body property.
Granted, you may have a framework do a fair bit of that. Depends how much you want between receipt of the request and code you directly control.
I do like static typing. But honestly, no other PL¹ (statically typed or otherwise) even comes close in terms of the ergonomics and joy of writing software. Nothing is quite enjoyable for me like Clojure. Haskell is great but hard, and I'm years away from claiming I achieved production-ready proficiency with it. I don't want to berate other languages, but I looked into OCaml, F#, Kotlin, Scala, Rust, and a few others. And none of them feel to me as enjoyable as Clojure. After so many years of programming, I finally, truly feel like I love my job. Also, I never liked Python. Maybe just a little, in the beginning. Once I get to know it, I disliked it forever.
-------
¹ I mean languages used in the industry, not counting even more "esoteric" PLs
Really, if repeating the same justifications convinces people, then the problem isn't the justifications.
That being said, I salute these brave companies for sticking to these obscure languages. Do we want to live in a world where there's only 3 languages to do everything? Even 10 sounds boring. Hell, even a fantastic tool like Ruby is considered Niche in certain parts of the world. I don't want a world without Ruby so I don't want a world without Closure.
If you're a small company, you usually cannot afford to hire "mediocre" talent. It is much more expensive to undo the crapola they'd implement. Trying to hire those who are at least interested in learning and using languages like Clojure, Rust, Haskell, Elixir, Elm, etc., is a very good quality filter. ROI from hiring a smaller number of Clojure devs, rather than a few more "regular" engineers - is much higher.
> Finding answers to common questions on Google/Stackoverflow;
Clojure gives you far fewer reasons for Googling things than other language ecosystems. It is dense language and inspires you to write smaller functions, decreasing the surface area for the problem. Most of the time, asking questions in Clojurians Slack sends you halfway through the solution.
> I salute these brave companies for sticking to these obscure languages
They do not choose Clojure for the shtick; Clojure is a highly pragmatic and immensely productive instrument. There are many "success stories" with small and medium-sized companies. A few large companies like Cisco, Apple, Walmart, et al., actively develop in Clojure.
The same can be said about the engineers. They don't choose Clojure because "they hate Java". You can check any Clojure surveys of the past. Most Clojure engineers are experienced and "tired" developers. Seasoned hackers who have seen the action. For most of them - Clojure is a deliberate choice. Many of them landed in it after trying various other alternatives.
Oh that's easy - the voting system is a way to know how conformant you are to other opinions coffee smile
This is unlikely to be the case in the choice of programming languages. Some may be a bad fit, some may have ecosystems that are unpleasant to use, but it's generally not the biggest problem an organization will have.
Typesystem strong enough to express dynamic language and completely optional wherever you want.
So no, it's not a perfect model, but I think its more informative than looking at languages on a one dimensional static / dynamic axis.
As far as I know, some dynamic languages like Python don't have that issue.
I myself rarely use Google to find a solution to a problem, and certainly almost never have to google shit like: "how to open a file in Clojure"...
That's something that dependently-typed typesystems easily do as well if not better because inside of the function or data definition, the information is still available and used for code-completion, other compiletime checks etc.
It's usually outside the scope of functions, since you are likely going to want to reuse those declarations. For example, you can use spec to generate test cases for something like quick-check.
You can add pre and post conditions to clojure function's metadata that test wether the spec complies with the function's input/output.
From their website [0]: "On returning to our office in Palo Alto, California At the moment, our employees are currently living and working all over the country. When it’s safe to gather again, we fully intend to return to the office."
The Guide/Reference split obscures a lot of information (do I want guidance on Deps & CLI or do I want reference on Deps & CLI?) and the guides where that gem is hidden randomly mix advanced topics (eg, how to set up generative testing), beginner topics (how to read Clojure code) and library author topics (eg, Reader Conditionals).
When you think about it, there is nearly no trigger to look at the guides when the information you need is there. Clojure is a weird mix of both well documented and terribly documented. All the facts are on the website, very few of them are accessible when required. The people who make it past that gauntlet are rewarded by getting to use Clojure.
Hm, I don't follow. If I were to write this in F#, there would be a type `Within5BusinessDays` with a private constructor that exposes one function/method `tryCreate` which returns a discriminated union: either an `Ok` of the `Within5BusinessDays` type, or an `Error` type with some error message. Once I have the type, I can then compose it with whatever and send it wherever and since F# records are immutable, I won't have to worry about invariants not holding. And since it's a type, I have the compiler/type system on my side to help with correctness.
(Side note, this is a bad example since the type can become invalid after literally 1 second... but since Clojure has the same problem I'm just running with it.)
I'm still learning Clojure (only a few months into it), but if I were to to write a spec, I'd have to specify what to do do if the spec failed to conform - same as returning the `Error` case in F#.
> i could swap out your spec for my spec so that would be 1:n but those specs may make sense to compose in other data use cases so really it's m:n rather than 1:1
Sorry, but I'm still not following - I believe you can do the same with types, especially if the type system support generics.
That’s not really the same thing - it’sa valid alternative approach but you’ve lost the benefits of a simple date - from (de)serialisation to the rich support for simple date types in libraries and other functions, the simple at-a-glance understanding that future readers could enjoy. Now the concept of date has been complected with some other niche concern.
> the type can become invalid after literally 1 second
Every system I’ve ever seen that has the concept of a business date strictly doesn’t derive it from wall clock date. E.g. it’s common that business date would be rolled at some convenient time (and most often not midnight) so you’d be free to ensure no impacts possible from the date roll.
>> I believe you can do the same with types, especially if the type system support generics
You can do something similar but you’ll need to change the system’s code.
It would be almost like gradual typing, except you could further choose to turn it off or to substitute your own types / schema without making changes to the system / code.
It’s quite a lot more flexible.
(Apols for slow reply - i 1up’d your reply earlier when i saw it but couldn’t reply then)
I see what you mean - thanks!
> you could further choose to turn it off or to substitute your own types / schema without making changes to the system / code
This is still unclear to me. How can you make changes (turning off gradual typing/substituting your own schema) without making changes to code?
Point being, I don't really buy that a static type system saves me any time writing and maintaining tests, because type systems are totally unable to express algorithms. And with a working test suite (which you will need regardless of static vs dynamic) large refactors become just as mechanical in dynamic languages as they are in static languages.
You don't know much about types if you think that.
As for dynamic typing "helping" you to find code that you need to write tests for: There are already far more sophisticated static analysis tools to measure code coverage.
doubler :: Num a => [a] -> [a]
doubler xs = take 2 xs
I like static typing, but static typing advocates seriously overstate how much protection the type system gives you. Hickey really said it best: "We used to say 'If it compiles it works' and that's as true now as it was then."
As for dynamic typing "helping find code to write tests", that's not a feature, it's a huge downside. Neither side is perfect, but in my experience the benefits of the static checker are overblown since I need to write tests anyways. And also like you say, there's a variety of great static analysis tools you should be using as well.
So what you get, after running the file afterwards from clean state might be different than the result of your selective separate manual evaluations.
This looks like exactly the opposite of the F5 workflow in the browser where you can run your program from clean state with single keypress.
I haven't watched the video till the end though maybe there's a single key that restarts the repl and runs the files from clean state here too.
At first glance you could have the same workflow with JS, but there's not much need for it because JS VMs restart very quickly and also you'd need to code in JS in very particular style, avoiding passing function and class "pointers" around and avoid keeping them in variables. I guess clojure just doesn't do that very often and just refers to functions through their global identifiers, and if that's not enough, even through symbols (like passing the #'app in this video instead of just app).
So when I later call the function I created for example, it'll use the new evaluated code instead of the old. If I'm happy, I save the file, everything reloads from there while keeping the same state.
That's not my experience. It doesn't say a whole lot, it just says a person is bored a bit and is confident in his ability to learn new things, you can filter for learning abilities by looking at what the person achieved; doing new stacks is just one metric. Also it's sometimes the type of people who care more about learning/trying new tech on the job than actually helping the business (for exmaple by introducing GraphQL because they read about it in a blog and it looks cool, not because they really think the business needs it).
Just to name some of the costs of static types briefly:
* they are very blunt -- they will forbid many perfectly valid programs just on the basis that you haven't fit your program into the type system's view of how to encode invariants. So in a static typing language you are always to greater or lesser extent modifying your code away from how you could have naturally expressed the functionality towards helping the compiler understand it.
* Sometimes this is not such a big change from how you'd otherwise write, but other times the challenge of writing some code could be virtually completely in the problem of how to express your invariants within the type system, and it becomes an obsession/game. I've seen this run rampant in the Scala world where the complexity of code reaches the level of satire.
* Everything you encode via static types is something that you would actually have to change your code to allow it to change. Maybe this seems obvious, but it has big implications against how coupled and fragile your code is. Consider in Scala you're parsing a document into a static type like.
case class Record(
id: Long,
name: String,
createTs: Instant,
tags: Tags,
}
case class Tags(
maker: Option[String],
category: Option[Category],
source: Option[Source],
)In this example, what happens if there are new fields on Records or Tags? Our program can't "pass through" this data from one end to an other without knowing about it and updating the code to reflect these changes. What if there's a new Tag added? That's a refactor+redeploy. What if the Category tag adds a new field? refactor+redeply. In a language as open and flexible as Clojure, this information can pass through your application without issue. Clojure programs are able to be less fragile and coupled because of this.
* Using dynamic maps to represent data allows you to program generically and allows for better code reuse, again in a less coupled way than you would be able to easily achieve in static types. Consider for instance how you would do something like `(select-keys record [:id :create-ts])` in Scala. You'd have to hand-code that implementation for every kind of object you want to use it on. What about something like updating all updatable fields of an object? Again you'll have to hardcode that for all objects in scala like
case class UpdatableRecordFields(name: Option[String], tags: Option[Tags])
def update(r: Record, updatableFields: UpdatableRecordFields) = {
var result = r
updatableFields.name.foreach(r = r.copy(name = _))
updatableFields.tags.foreach(r = r.copy(tags = _))
result
}
(defn update [{:keys [prev-obj new-obj updatable-fields}]
(merge obj (select-keys new-fields updatable-fields)))
(update
{:prev-obj {:id 1 :name "ross" :createTs (now) :tags {:category "Toys"}}
:new-obj {:name "rachel"}
:updatable-fields [:name :tags]})
=> {:id 1 :name "rachel" :createTs (now) :tags {:category "Toys"}}
Anyways I could go on but have to get back to work, cheers!
This blog post[1] has a good explanation about it, if you can forgive the occasional snarkyness that the author employs.
In a dynamic system you’re still encoding the type of the data, just less explicitly than you would in a static system and without all the aid the compiler would give you to make sure you do it right.
[1]: https://lexi-lambda.github.io/blog/2020/01/19/no-dynamic-typ...
> they are very blunt
I'm more blunt than the complier usually. I really want 'clever' programs to be rejected. In rare situations when I'm sure I know something the complier doesn't, there are escape hatches like type casting or @ignoreVariace annotation.
> the problem of how to express your invariants within the type system
The decision of where to stop to encode invariants using the type system totally depends on a programmer. Experience matters here.
> Our program can't "pass through" this data from one end to an other
It's a valid point, but can be addressed by passing data as tuple (parsedData, originalData).
> What if there's a new Tag added? What if the Category tag adds a new field?
If it doesn't require changes in your code, you've modelled your domain wrong - tags should be just a Map[String, String]. If it does, you have to refactor+redeploy anyway.
> What about something like updating all updatable fields of an object
I'm not sure what exactly you meant here, but if you want to transform object in a boilerplate-free way, macroses are the answer. There is even a library for this exact purpose: https://scalalandio.github.io/chimney/! C# and Java have to resort to reflection, unfortunately.
Or this can wreak havoc :) Nothing stops you from writing Map<Object, Object> or Map[Any, Any], right?
If I'm understanding you correctly, you're saying statically typed language can't protect against design flaws, only implementation flaws. But implementation flaws are common, and statically typed languages do help to avoid those.
There's a big difference between a developer going off and writing something in one of the top five most used languages in the world and doing so in Scala.
Python may seem simple once you know it, but going in blind there's plenty of traps to bite you. Significant whitespace for one.
1. picking a language/tool that a company doesn't have personnel with experience using it
2. picking a language/tool that is esoteric, which generally implies #1 as well.
#1 on its own isn't great, but generally when sticking in the java/python/ruby/javascript/php/etc...mainstream languages, there's a lot more documentation, and there's a higher chance that _someone_ in the company will have some familiarity. If nothing else, it'd be easier to hire a replacement for.
My point is: these are all individual attempts (the book i mean) and there will always be something on page xyz broken and it can't be solved by individuals. To solve these problems, there needs to be constant time and money investment from someone serious (like facebook in case of create-elm-app).
There is some community effort to better fund the core infrastructure in Clojure through https://www.clojuriststogether.org/, hopefully they can continue to attract more funding developers and companies.
In general a lot of these issues could be alleviated if the community was just in general larger with more contributors. I think the Clojure community is quite welcoming to newbies in the sense that people are quite responsive, kind and helpful around the internet, in Clojurians Slack (try asking there btw, if you haven't yet and are still stuck at the start of the book), etc. But in other ways people seem averse to criticism or suggestions from outsiders. I think the Clojure world needs to do a bit of self reflection to understand why adoption is so low right now and honestly consider what needs to change to attract more developers and contributors.
Also it wasn't perfect, hence why Strongtalk was born, the remains of which now live on Hotspot.
So you can do a lot of refactorings with that such as:
Rename function, rename variable, rename namespace, extract constant, extract function, extract local variable, extract global variable, convert to thread-first, convert to thread-last, auto-import, clean imports, find all use, inline function, move function/variable to a different namespace, and some more.
The only thing is you can't change the "type" of something and statically know what broke.
Without them, all these refactorings can break your code (as in, not even compiling, let alone run).
One of the ideas behind IoC frameworks (which build on top of DI) is that you could swap out implementation classes. For a great deal of software (and especially in cloud-hosted, SaaS style microservice architecture) the test stubs are the only other implementations that ever get injected.
Most code bases could ditch IoC if Java provided a language-level construct, even if that construct were only for the test harness.
Spring is great when you need that dynamic control at runtime (especially when code dependencies are separated by modules) but you're just aping what good dynamic languages like Clojure or Common Lisp give you for free. But I can't complain too much, developing modern Java with its popular frameworks and with JRebel is getting closer to the Lisp experience every year, I'd rather have that than for Java to remain stagnate like in its 1.6/1.7 days.
Can you show me how you would mock the current time of that method in Java?
It's one line of Ruby/Javascript code to do that.
final Date testDate = someFixedDate;
User testUser = new User() {
@Override
Date say_current_time() {
return testDate;
}
};
But your point further down that in Java you have to think about your code structure more to accommodate tests is valid. I think it's easy to drink the kool-aid and start believing that many code structuring styles that enable easier testing in Java are actually very often just better styles regardless of language, but you're not going to really see the point if you do nothing but Ruby/JS where you can get away with not doing such things for longer. Mostly it has to do with dynamic languages offering looser and later and dynamic binding than static languages (which also frequently makes them easier to refactor even if you don't have automated tools). One big exception is if your language supports multiple dispatch, a lot of super ugly Java-isms go away and you shouldn't emulate them. The book Working Effectively with Legacy Code is a good reference for what works well in Java and C++ (and similar situations in other languages), it's mostly about techniques for breaking dependencies.
Mockito in Java has a nifty way of doing this with Mockito.mockStatic:
@Test
public void mockTime() throws InterruptedException {
LocalDateTime fake = LocalDateTime.of(2021, 7, 2, 19, 0, 0);
try (MockedStatic<LocalDateTime> call = Mockito.mockStatic(LocalDateTime.class)) {
call.when(LocalDateTime::now).thenReturn(fake);
assertThat(LocalDateTime.now()).isEqualTo(fake);
Thread.sleep(2_000);
assertThat(LocalDateTime.now()).isEqualTo(fake);
}
LocalDateTime now = LocalDateTime.now();
assertThat(now).isAfter(fake);
assertThat(now).isNotEqualTo(fake);
}
Instant testNow = ...
User u = new User(Clock.fixed(testNow, ZoneOffset.UTC));
u.sayCurrentTime();
User mock = mock(User.java)
when(mock.say_current_time()).thenReturn(someDate)Mocking dynamically typed languages is monkey patching, something that the industry has been moving away from for more than a decade. And for good reasons.
I can say the same about Rails + RSpec. It exists therefore it's good.
> Mocking dynamically typed languages is monkey patching, something that the industry has been moving away
That's a reach. There are millions of javascript/python/php/ruby/elixir devs that don't use types or annotations. They mock. "The industry" isn't one cohesive thing.
Which is why the async monad tends to infect everything. Clojure, as far as I can tell so far, doesn't support anything similar to computation expressions. So I'm guessing your "poked at it a couple times" was something like calling `pmap` and/or blocking a future? All my multithreaded Clojure code quickly blocks the thread... and I can't tell if this is idiomatic or if there's a better way.
IIRC/IIUC, Clojure's async support is closer to Go's (I've never used go), in the form of explicit channels. Though you can wrap that in a monad pretty easily, which I did for fun one day (https://gist.github.com/daxfohl/5ca4da331901596ae376). But neither option was easy to port AFAICT before giving up.
Note it's possible that porting async functionality to Clojure may have been easier that I thought at the time. Maybe adding some channels and having them do their thing could have "just worked". I was used to async requiring everything above it to be async too. But maybe channels don't require that, and you can just plop them in the low level code and it all magically works. A very brief venture into Go since then has made me wonder about that.
Async style comes into play generally for languages that lack real threads, or as a way to manage callbacks (even if single threaded), or in order to wait for blocking IO without the need for a real thread.
So ya, it's idiomatic to use blocking to coordinate between different threads in Clojure, same as Java.
Java decided to work on making stackful coroutines instead of stackless like C#. That requires a lot more work, but should be coming eventually to Java. At that point, your "blocking" code in Clojure will no longer block a real thread, but a lightweight fiber instead. But patience is needed for it.
In the meantime, if you're dealing with non-blocking IO that operates with callback semantics or other callback style code, what you can do in Clojure to make working with that easier is use one of:
> core.async - https://github.com/clojure/core.async
> Promesa - https://github.com/funcool/promesa
> Missionary - https://github.com/leonoel/missionary
> Missionary's lower level coroutine lib - https://github.com/leonoel/cloroutine/blob/master/doc/02-asy...
I'll check out your other links though, much appreciated. Also hearing that I should just be okay with blocking is well, good to hear explicitly.
It's best to refrain from debating static VS dynamic as generic stereotype and catch all.
You need to look at Clojure vs X, where if X is Haskell, Java, Kotlin and C#, what the article talks about doesn't apply and Clojure has the edge. If it's OCaml or F# than they in some scenarios don't suffer from that issue like the others and equal Clojure. But then there are other aspects to consider if your were to do a full comparison.
In that way, one needs to understand the full scope of Clojure's trade offs as a whole. It was not made "dynamic" for fun.
Overall, most programming languages are quite well balanced with regards to each other and their trade-offs. What matters more is which one fits your playing style best.
So, in statically typed languages, it is not idiomatic to pass around heterogeneous dynamic maps, at least in application code, like it is in Ruby/Clojure/etc. But one analogy we can draw which could drive some intuition for static typing enthusiasts is to forget about objects and consider lists. It is perfectly familiar to Scala/Java/C# programmers to pass around Lists, even though they're highly dynamic. So now think about what programming would be like if we didn't have dynamic lists, and instead whenever you wanted to build a collection, you had to go through the same rigamarole that you have to when defining a new User/Record/Tags object.
So instead of being able to use fully general `List` objects, when you want to create a list, that will be its own custom type. So instead of
val list = List(1,2,3,4)
case class List4(_0: Int, _1: Int, _2: Int, _3: Int)
val list = List4(1,2,3,4)
case class List5(_0: Int, _1: Int, _2: Int, _3: Int, _4)
def append(list4: List4, elem: Int): List5 = List5(list4._0, list4._1, list4._2, list4._3, elem)
def map(list4: List4, f: Int => Int): List4 = List4(f(list4._0), f(list4._1), f(list4._2), f(list4._3))
def sum(list4: List4): Int = list4._0 + list4._1 + list4._2 + list4._3
I think it's obvious what is missing, it's that all this code is way too specific, you can't reuse any code from List4 in List5, and just a whole host of other problems. Well, this is pretty much exactly the same kinds of problems that you run into with static typing when you're applying it to domain objects like User/Record/Car. It's just that we're very used to these limitations, so it never really occurs to us what kind of cost we're paying for the guarantees we're getting.
That's not to say dynamic typing is right and static typing is wrong, but I do think that there really are significant costs to static typing and people don't think about it.
I can think of instances where that might be useful and I think there’s even work being done in that direction in things like Idris that I really know very little about.
There are trade offs in everything. I’m definitely a fan of dynamic type systems especially things like Lisp and Smalltalk where I can interact with the running system as I go, and not having to specify types up front helps with that. Type inference will get you close to that in a more static system, but it can only do so much.
The value I see in static type systems comes from being able to rely on the tooling to help me reason about what I’m trying to build, especially as it gets larger. I think of this as being something like what Doug Englebert was pointing at when he talked about augmented intelligence.
I use Python at work and while there are tools that can do some pretty decent static analysis of it, I find myself longing for something like Rust more and more.
Another example I would point to beyond the blog post I previously mentioned is Rust’s serde library. It totally allows you to round trip data while only specifiying the parts you care about. I don’t think static type systems are as static as most like to think. It’s more about knowns and unknowns and being explicit about them.
You expect your programming language to be a continuation of your thoughts, it should be flexible and ductile to your improvisations. You see static typing as a cumbersome restricting bureaucracy you have to obey to.
Whereas I see type system like a tool that helps to structure my thoughts, define the rules and interfaces between construction blocks of my program. It is a scaffolding for a growing body of code. I found that in many cases, well defined data structures and declarations of functions are enough to clearly describe how some piece of code is meant to work.
It seems we developed different preferred ways of writing code, maybe, influenced by our primary languages, features of character, type of software we create. I used Scala for several years, but recently I regularly use Python. Shaping my code with dataclasses and empty functions is my preferred way to begin.
You can have a `Map k v` that is a record that dynamic languages have that they call object/map.(make k/v Object or Dynamic if you want)
You don't need to create a new type with precise information if you just want that(no you don't need to instantiate type params everywhere). There is definitely limitations in type-systems (requiring advanced acrobatics) but most programs don't run into them and HM type system (https://en.wikipedia.org/wiki/Hindley%E2%80%93Milner_type_sy...) has stood the test of time.
For a great introduction on the idea of a type system, see: https://www.youtube.com/watch?v=brE_dyedGm0 .
Yes, that was my point. I see it's possible in Java though, hurts my eyes a bit but possible :)
(2) this misses the meat of the question which is how to express that (eg) a GET request doesn’t come with a body and a POST request does. I suppose that you’re suggesting that one registers a url handler with a method type and that forces the handler to accept responses of a certain type. Or perhaps you are implicitly allowing for sun types (which aren’t a thing in many static type systems.)
(3) even in C++, isn’t this suggestion hard to work with. That is, isn’t it annoying to write a program which works for any request whether or not it has a body because the type of the body must be a template parameter that adds templates to the type of every method which is generic to it. But maybe that is ok or I just don’t understand C++.
2) If you want to distinguish GET and POST requests statically then you just need a type for them e.g.
GetRequest<TBody> implements Request<TBody> { }
3) Yes you'll have to make functions that don't care about the body type generic so this approach could become unwieldy if you have a few such properties you want to track.
It requires a bit of elbow grease to make it work with a CICD system... but it works :D
It's not only the language but the framework. For example I know javascript well enough but I now am quite a noob with Ember in my new role. I would say the framework is just as important as the language, at least when doing web development.
If it's just one component, implemented by a single dev, it really can make more sense to understand what it does and rewrite it in a language that's common in the company.
While core.async pays homage to go, it's simply not go, and it's harder to work with, and generally the changes are going to be more invasive, and looking around at modern resources, I don't see anything that indicates much has changed. So while I might have been more efficient if I'd had the go mental model, that was definitely not the only problem. Migrating was too much to do in my fairly large project, hunting and pecking at each instance I made an async call. Whereas with F# it was truly mechanical and hard to mess up, as I described above.
None of those seem to require type information from my reasoning (and are also all available in Emacs for Clojure)
For example, moving a function from one namespace to another, you know where this function is being used from the require declarations, and you know where you've been told to move it too and where it currently resides. So you can simply change the old require pointing to its old namespace to point to the new namespace and cut/paste the function from the old to the new. Nothing requires knowing the type or the arguments or the return value of the function.
See a gif of it in action: https://raw.githubusercontent.com/clojure-emacs/clj-refactor...
Even Smalltalk's refactoring browser made mistakes which humans had to fix by hand. Which is not surprising, because in the absence of type annotation, the IDE doesn't have enough knowledge to perform safe refactorings.
In Clojure, I'm talking about renaming a function, which can be done without types.
See the difference is that with a method:
x.f()
You have to know the type of `x` to find the right `f`, but with a function in Clojure:
(ns foo
(:require [a :refer [f]]))
(f x)
And this is unambiguous in Clojure because there cannot be more than one `f` inside `a`.
If you had two `f` this would be the code in Clojure:
(ns a)
(defn f [] "I'm in a")
(ns b)
(defn f [] "I'm in b")
(ns foo
(:require [a :refer [f]]
[b :refer [f]
:rename {f bf}]))
(f x)
(bf x)
However you are talking about typing as if all typing is static - static typing has little value beyond warm and fuzzies on the developers part, dynamic typed systems are able to perform just as well. At which point, the dynamic part can allow you to mostly drop the types.
statically typed systems, you will note, tend to come with ecosystems dedicated to using the static bits as little as possible. And they provide no guarantee of correctness.
Yes, new devs might be able to latch onto some specific typing a bit better, but I don't care if you have all the automated refactors and a hundred new employees, if your codebase sucks and is incorrect, your static analysis is worth didly squat.
And again if this is possible I will admit ignorance and tip my hat at the Java guys.
There is little use in wrapping a call in `Maybe` to then immediately unwrap the result on the next line. Doing so isn't really using the construct... One would expect the lines following the creation of `Maybe` to bind calls through the monad.
In the end I see almost no meaningful difference between their "Paying it forward" example and simply utilizing an `if` to check the result and throw. In essence the author is using a parse and validate approach!
FWIW SPJ has called this blog's author a "genius" so... I think they do know how `Maybe` works. https://gitlab.haskell.org/ghc/ghc/-/issues/18044#note_26617...
I generally agree with the premise of the post.
case nonEmpty configDirsList of
Just nonEmptyConfigDirsList -> pure nonEmptyConfigDirsList
Nothing -> throwIO $ userError "CONFIG_DIRS cannot be empty"
The code I've quoted that checks which case we have, is the only place that needs to handle that `Maybe`. Or maybe `main`, if we want to be more graceful. The author (I wouldn't say I know her but I know that much) does know how to chain maybes with bind but it's not necessary in this example code.
I'm sure `main` could be written to "bind"/"map" `getConfigurationDirectories` with `nonEmpty`, `head`, and `initializeCache` in a way that puts the `throw` at the top-level (of course the above implementations may need to change as well). Unfortunately I'm not familiar enough with Haskell to illustrate it myself.
Sure you can unwrap it right away, but that isn't necessary because you could also just "bind" the next function call to the monad (which is more idiomatic to the construct). You never have to worry about that value in this case because... well... that's the benefit of using `Maybe`.
I'm not super familiar with Haskell, but my sense is that the author is trying more to please the compiler (at a specific point in the program!) than simplify the logic. That is, they want a concrete value (`configDirs`) to exist in the body of `main` more than they want the cleanest representation of the problem in code.
That said, maps as the only tool is clearly messy. And is a straw man.
I'd say the main one is that it enables automatic refactorings, which are mathematically impossible to achieve when you don't have type annotations.
Thanks to automatic refactorings, code bases are easier to maintain and evolve, as opposed to dynamically typed languages where developers are often afraid to refactor, and usually end up letting the code rot.
It's also a great way to document your code so that new hires can easily jump on board. It enables great IDE support, and very often, unlocks performance that dynamically typed languages can never match.
Yeah, it's really not impossible. Maybe in theory, it's "mathematically impossible", but in practice, doing a search on your local codebase and understanding the code you find makes it easy to do refactors too. Dynamic languages also can help making refactoring obsolete, as you can create data structures that doesn't matter if they are User or Person, as long as it has a Name, print the name (or whatever, just a simple example) whereas with a static type system, you'd have to change all the User to Person. You're basically locking your program together, making it coupled and harder to change.
> It enables great IDE support
Is there anything specific that IDEs support for static typing that you can't have for dynamic languages? I mostly work with Clojure and have everything my peers have when using TypeScript or any other typed language.
> unlocks performance that dynamically typed languages can never match
I think there is a lot more to performance than just types. Now the TechEmpower benchmarks aren't perfect, but a JS framework is at the 2nd place in the composite benchmark, beating every Rust benchmark. How do you explain this if we consider your argument that types will for sure make everything faster and more efficient?
https://www.techempower.com/benchmarks/#section=data-r20&hw=...
Let me give you one example.
When I'm coding in Rust and I forget to match on one of my sum type's variants, the compiler will immediately yell at me.
When I'm coding in Elixir, the compiler doesn't care if I do exhaustive pattern matching because it doesn't know all possible return values. In these conditions it's extremely easy to not write code that deals with a return value that appears rarely.
That's one of the values of static typing for me.
The pattern matching example is one that often comes up talking about typing. Yes it's great that the type checker finds all the places you didn't deal with your new sum type varient...except here's the rub. All that code was working just fine before. Your static type checker is forcing a bunch of code that never needed to know or care about certain values onto all places where you used pattern matching. I don't think this speaks to the value of static typing, I think it suggests that pattern matching is a bad idea that leads to overly coupled code where parts of the system that really shouldn't need to know about each other are now forced to deal with situations they don't care about.
It's not "forcing" anything, you are evolving your program and the compiler is helping you not play a whack-a-mole by actually telling you every place that must be corrected in order to account for the change.
Wasn't aware that evolving a project is called forcing. :P
> I think it suggests that pattern matching is a bad idea that leads to overly coupled code where parts of the system that really shouldn't need to know about each other are now forced to deal with situations they don't care about.
That's a super random statement, dude. If a sum type change makes 7 places in your code not compile then obviously those pieces of code do care about it -- you wouldn't write it that way if it didn't. Nobody put a gun on your head forcing you to include the sum type in these places in the code just because, right?
Overall I am not following your train of thought. You seem to be negatively biased. I've seen from my practice only benefits by enforcing exhaustive pattern matching. Many times I facepalmed after I got a compiler error in Rust and was saying "gods, I absolutely would've missed that if I wrote it in a dynamic language".
If you can do that, that's awesome, but I'm not seeing how.
As for a function that will "double" a list, i.e. turn [1,2] into [1,1,2,2]: That is definitely possible with dependent types as they can express arbitrary statements. I'm not sure if you can do it without dependent types, but I'm inclined to say yes: something like an HList should work. Universal quantification over the HList parameters will ensure that the only way to create new values of the parameter types is to copy the old ones, as long as you disallow any form of `forall a. () -> a` in the type system.
Something like this, which is just the `double` function lifted into the universe of types, _might_ work, though its utility is questionable:
type family DoubleList xs :: 'HList -> 'HList where
DoubleCons ('HCons x ': xs) = 'HCons x ': 'HCons x ': Double xs
DoubleNil 'HNil = 'HNilIn this case, it's to provide a better error message in case there's an empty list than `fromList` would provide.
> You never have to worry about that value in this case because... well... that's the benefit of using `Maybe`.
But you do, your entire program doesn't live in `Maybe` so at some point you have to check whether it's `Just a` or `Nothing`. Once again, the whole point of the post is to argue that getting out of the `Maybe` as close to parsing time as possible is preferable so you have a more specific type to work with after that. You also see right away what didn't parse instead of just knowing that something didn't parse, which is what would happen if you stayed in the `Maybe` monad for all your parsing.
Well... if your entire program is dependent on some input that may or may not exist at runtime... then it kind of does live in `Maybe`.
I have no issue with unwrapping a `Maybe` to throw an exception. But I do find it a bit ironic that the post is about parsing instead of validating, that the perfect construct is right there to exemplify how it could be done, but the author then chooses to eschew it and instead show examples of how validation could look.
The body of `main`, for example, could be refactored to something like:
maybeInitialized <- (getConfigurationDirectories >>= head >> initializeCache)
https://javadoc.io/static/org.mockito/mockito-core/3.11.2/or...
User mock = mock(User.java)
Should have been
User mock = mock(User.class)
I was less than impressed with type systems because like the blog post says, they tend to just kick the can down the road. The blog post uses a technique like you did in your example where rather than emitting more complicated type, they use the type system to protect the inputs of the function thus moving handling with the problem to the edges of the system which seems like a huge win. Between your example and that post I'm starting to see what people mean when they talk about programming in types, as its almost like the type system become a DSL with its own built-in test suite with which to program rather than a full programming language.
Either way very thought provoking, thank you for your responses.
Hmm, I think you can do that too, but you'd have to assign each int value its own singleton type, which would be ridiculous and not gain you anything since you're just moving the logic up one level in the hierarchy of universes.
> what people mean when they talk about programming in types
If the type system is powerful enough then you can express any function at the type level. Some languages with universal polymorphism make no difference between types and terms. Any function can also be used at the type-level, kind-level and so on. Though usually just defining a simple wrapper type with smart constructor will get you 80% of the way in a business application with 2% of the effort of real type-level programming.
getConfigurationDirectories: unit -> Maybe [FilePath]
nonEmpty: [a] -> Maybe [a]
head: [a] -> Maybe a
initializeCache: FilePath -> unit
maybeInitialized <- (getCofigurationDirectories >>= head >> initializeCache)
My critique is exactly that unwrapping the `Maybe` immediately in order to throw an exception is kind of the worst of both worlds. I mentioned this in a sibling comment, but my sense is that the author is more concerned with have a concrete value (`configDirs`) available in the scope of `main` than best-representing the solution to the problem in code. It is a shame because I agree with the thesis.
You are already handling a `Maybe` type because it's possible for your input to not exist. Because the first implementation of `head` also returns a `Maybe`, it is possible to "bind" them together (I'm leaving out `IO` because I am both unsure of the syntax[0] and it is immaterial to the example):
head :: [a] -> Maybe a
head (x:_) = Just x
head [] = Nothing
getConfDirs :: Maybe [FilePath]
initializeCache :: FilePath -> Cache
useCache:: Cache -> Value
main :: ()
main = do
// you don't need concrete values here
maybeCache <- (getCofDirs >>= head >> initializeCache) // Maybe Cache
// one option
case maybeCache of
Just c -> useCache c
Nothing -> error "CONFIG_DIRS cannot be empty"
// another option
maybeValue <- (maybeCache >> useCache) // Maybe Value
The two functions `head` and `getConfDirs` are "parsers" because they both return `Maybe`. Contrary to
> Returning Maybe is undoubtably convenient when we’re implementing head. However, it becomes significantly less convenient when we want to actually use it!
It is trivial to use a reference to `Maybe` because it is a monad that it is specifically designed to be used more conveniently than the alternative approaches in the case when a value may (or may not) exist.
maybeCache <- (getCofDirs >>= head >> initializeCache)
The monadic operators make it convenient to propagate missing values through a chain of operations but they are not the primary benefit of an explicit Maybe type. Much like IO, the benefit of having an explicit Maybe type is when you _don't_ have it since its absence represents more information at that point in the program. Likewise a (NonEmpty a) contains more informatation than [a] which consequently makes the implementation of head more informative.
The parsers in this approach have types like
a -> Maybe b
[a] -> Maybe [a]
Furthermore, my example is a much better illustration of the axiom ("Parse don't validate") than what the author is doing -- which is more like "Parse and validate".
You need to clarify "continuously guard". Sure you have to invoke methods like:
maybeCache >> useCache // map
maybeCache |> useCache // not sure how Haskell pipes
The purpose of `Maybe` is to simplify code that needs to deal with a value that might not exist. Attempting to organize your code to avoid using `Maybe` is, by definition, going to be more cumbersome than simply leaning into the construct (that's what it's for!). It also better-illustrates how "parse don't validate" should work. Using an exception to guard against an invariant is... validating not parsing.
You don't need to defend the author here. It's just a matter of fact the the code provided could be organized differently according to a more idiomatic usage of `Maybe`, and therefore a more illustrative example of their own point. The choice to exemplify something else is unfortunate and the thrust of this entire comment thread -- I felt like I had to say something now seeing that link a second time.
> Really, a parser is just a function that consumes less-structured input and produces more-structured output. By its very nature, a parser is a partial function—some values in the domain do not correspond to any value in the range—so all parsers must have some notion of failure. Often, the input to a parser is text, but this is by no means a requirement, and parseNonEmpty is a perfectly cromulent parser: it parses lists into non-empty lists, signaling failure by terminating the program with an error message.
So the properties checked by the parser are reflected in the output type. Reifying these properties in the type is what allows the validation to be done once at the top level and avoided throughout the rest of the program. Your complaint about throwing exceptions is focusing on an irrelevant detail in a small example - yes this could have been moved into the main function but doesn't affect the overall behaviour.
However your argument that propagating Maybe values is more idiomatic than parsing into a more precise type is one I - and I assume most - static typing advocates would disagree with. Given the choice you would always prefer an 'a' over a 'Maybe a' since a Maybe represents a point of uncertainty which you would rather not have. As a result, having to chain this imprecision using various combinators is inherently more complex than not having to do so. Yes, using bind etc. is preferable to manually destructing Maybe values but avoiding Maybe is more preferable still.
You can't avoid `Maybe` in this system. It is in the nature of the problem (as it is designed) that the input might not exist (and therefore a list might be empty). The question isn't one of avoidance, rather, integration. How do we deal with problems like the example?
"Parse don't validate" is a great way to deal with it! Even more convenient is the existence of a tool that can be used to offload all of the redundancy involved when choosing to parse instead of validate (i.e. throw an error).
It is the author's prerogative to value having a concrete value at one specific point in the program (`main`) over demonstrating how using `Maybe` can make parsing a breeze. Clearly you also value (for whatever reason) knowing that a variable contains a value at some specific, rather arbitrary point in the example program[0]. But it is an unfortunate choice given the title of the post.
Not only does the example code in the post not illustrate "parse don't validate" very well, it convolutes the solution considerably. My example above is able to achieve identical behavior in an easier-to-digest flow while also illustrating how parsing instead of validating can be done.
[0] Of course we know that any function to which we `map` to our `maybeCache` will for sure be invoked with an instance of `Cache`.
What is important is that we know we will have to deal with the possibility of something not existing. That is where the complexity lies, and where we want to take care to make our program as sensible as possible. Validating your input to throw an exception or return is one way to satisfy the compiler, another way is to use `Maybe` as intended. The author's "solution" is simply a poor illustration of parsing over validation (read that sentence again).
I suspect, and this applies to you as well, that they are just not comfortable working with the `Maybe` construct. Adding extra ceremony to remove a `Maybe` is simply not worth the trouble, and your idea of "continuously propagating" is severely overblown. Again, we can write every single line of the rest of our program as if `Cache` exists. You don't need to "handle" anything extra (other than the holding the concept of a slightly more complex value in your mind).
getConfigurationDirectories :: IO [FilePath]
getConfigurationDirectories :: IO (NonEmpty FilePath)
Yes the second version could have been changed to one of:
getConfigurationDirectories :: IO (Maybe (NonEmpty FilePath))
getConfigurationDirectories :: MaybeT IO (NonEmpty FilePath)
your attempted 'improvement' of using
getConfigurationDirectories :: IO (Maybe [FilePath])
maybeCache >>= useCache
[FilePath] -> IO a
I cannot stress this enough. You do not need to remove the possibility of a value not existing in order to compose a simple, coherent program. This is because `Maybe` is designed to handle all of the extra ceremony involved with utilizing such values. You only need to use `>>` (map) instead of `|>` (pipe) when invoking your functions. That is it.
All of the above is really beside the point though, because I am not arguing that one way is necessarily better than the other. I am arguing that the author's post is titled "Parse don't validate", that the perfect construct is right there to exemplify how parsing unstructured data into/through a system can be done, but then the author eschews it in favor of... validation (with what appears to be some tricks to fool the compiler)!
If your guard against an invalid state is to throw an exception you are validating. Attempting to redefine the terms to fit a particular narrative is a distraction that serves no one.
> Neither I nor the author is unaware that there are many combinators that make this more convenient than explicit matching against Just/Nothing but doing so is strictly worse than returning a FilePath directly
useFilePath :: FilePath -> a
maybeFilePath <- (getConfigDirs >>= head)
maybeFilePath >> useFilePath
filePath <- getConfigDir // might throw
filePath |> useFilePath
Yes, sorry it's actually the line
maybeCache <- (getConfDirs >>= head >> initializeCache)
> but then the author eschews it in favor of... validation (with what appears to be some tricks to fool the compiler)!
I think the author is pretty clear about how they're using the terms 'validation' and 'parsing' in the post - validation functions do not return a useful value while parsers refine the input type and carry a notion of failure. The first two examples of parsers they give are:
nonEmpty :: [a] -> Maybe (NonEmpty a)
parseNonEmpty :: [a] -> IO (NonEmpty a)
checkNoDuplicateKeys :: (MonadError AppError m, Eq k) => [(k, v)] -> m ()
MonadError e m => a -> m b
If you were translating this approach to other languages like Java or C# though you proabably would throw exceptions to indicate failure e.g.
interface Parser<A, B> { B parse(A input) throws ParseException; }
> I'd like you to define "strictly worse" here
I'm saying you would always prefer to be handed an instance of an `a` instead of a (Maybe a) since it's more precise. You can trivially construct a (Maybe a) from an a but you can't easily go in the other direction. You either need to produce a dfeault value or use a partial function like fromJust to obtain an 'a' from a 'Maybe a'. The motivation for the post is to show how using a more precise data type allow you to remove these from the rest of the code.
> But why are variables in this scope (`main`) so important
The issue doesn't happen in main, it happens throughout the rest of the program. The high-level structure is something like:
main :: IO ()
main = do
maybeDirs <- getConfigDirs
maybeDirs >>= restOfProgram
1. Use fromJust since the list should be non-empty 2. Produce a default value 3. Propagate the Maybe in the return type of funN
Option 1 is messy, 2 is also unlikely for a low-level function and 3 forces fun1 to fun (N - 1) to either handle or propagate the partiality. Yes using >>= and <=< etc. can hide this plumbing but can be made unnecessary in the first place.
> I'm saying you would always prefer to be handed an instance of an `a` instead of a (Maybe a) since it's more precise.
> You can trivially construct a (Maybe a) from an a but you can't easily go in the other direction. You either need to produce a dfeault value or use a partial function like fromJust to obtain an 'a' from a 'Maybe a'
This is starting to feel like a waste of time. You are very much hung up on trying to defend the idea that using `Maybe` is something to be avoided. I understand where you are coming from. I really do. But you are simply not going to convince me because I prefer to model systems as a whole and I prefer to avoid doing extra gymnastics to solve already-solved problems. Throwing an exception? C'mon... we both know that example sucks.
My critique of the post really has nothing to do with choosing `Maybe` vs validating. My critique is that the author's code is utterly failing to exemplify parsing over validation! Using `Maybe` to chain parsers together in order to build an input would have been perfect. Unfortunately, they kind of mucked it up halfway through because they appear to be afraid of `Maybe`. It's a shame given that the post seems to have gotten around.
[0] This whole `NonEmpty` non-sense is a sideshow that's not worth discussing (other than to further illustrate how `Maybe` can be used to simplify multi-step parsing). What happens when you need the Nth element? You just keep re-defining the type to include more values? When we get to `NonEmpty6` I think maybe we will have realized we are on the wrong path. For our purposes it's better to think of `[FilePath]` as `Input` and not get bogged down in the specifics of its shape. The important bit is that it might not exist.
Type-driven design is based around encoding invariants as much as is practical in the type system (what constitutes 'practical' is constrained by the type system you're using). The (NonEmpty a) type is just used to demonstrate a very simple example of this principle. In the same way that type 'a' is smaller than the type (Maybe a), so (NonEmpty a) is smaller than a [a] which means the operations on it are similarly more precise, which shows up in the two version of head:
head :: NonEmpty a -> a
head :: [a] -> Maybe a
type User {name :: String}
type User = JsonValue
getName :: User -> String}
getName :: JsonValue -> Maybe String
In your post the argument to restOfProgram has type [FilePath] but in the post it is (NonEmpty FilePath) so you need to handle the potential non-emptiness of the list everywhere you try to access it, either by propagating missing values to a higher level or using 'unsafe' functions like fromJust. It's defensible to prefer using a simpler representation type and dealing with the imprecision, but it's not doing the same thing - the types for a lot of the internals of your program will be quite different. This is probably the main philosophical difference with Clojure which prefers to use a small number of simple types along with dynamically checking desired properties at the point of use, something which tools like spec and schema make quite convenient. But people use static languages because of the global property checking, so it seems odd to me to endorse explicit modelling of missing values with Maybe while rejecting doing the same thing for non-emptiness since they are both lightweight approaches.
The insight of the original post is that if you choose to try make your types precise in this way (and most Haskell programers would I believe) then the process of checking the properties you want to enforce from a less-precise representation is inseperable from the process of converting into the narrower representation. This narrowing process could fail and must therefore encode the representation for the failure case. Your insistence that Maybe should be used as the one true failure representation is wrong I think, throwing exceptions in Haskell is rare but but they could have also chosen (Either String) for example. Maybe isn't even a particularly good representation since it doesn't contain any way of describing the reason for the failure, just that it happened. I agree it would have been nice to see an example of parser composition using <=< etc. would have been useful there but it's not the main point of the article.
> In your post the argument to restOfProgram has type [FilePath] but in the post it is (NonEmpty FilePath) so you need to handle the potential non-emptiness of the list everywhere you try to access it
getConfiguration :: () -> Maybe { cache :: FilePath }
> Your insistence that Maybe should be used as the one true failure representation
// returns a non-empty list of string
getConfigurationDirectories: () => [string, ...string[]] = () => {
const dirs = getEnv("dirs").split(",");
if (dirs.length < 1) throw "ERROR";
return dirs;
}
> The above is not best-understood as a "parser". The above is validating the input
Yes the example you gave is an example of validating in the author's formulation because it does not enforce the property it's checking in the return type. You check the list is non-empty but this information is not available anywhere else in the program. A parser would return a (NonEmpty String) as its result since that does enforce the constraint.
> Trying to redefine "parsing" to mean "the result has a different return type"
That's not a redefinition of parsing, that's what a parser is.
I'm sure you could imagine my example record containing more keys no?
The requirements from the post are arbitrary and could (should) be anything that best-illustrates the thesis of the post. For example by choosing a representation of their "configuration" that suffers from this silly problem of containing unknown content after parsing, the author introduces the whole `NonEmpty` gymnastics. It's totally avoidable. The irony is that the author was so close to getting it right!
> You check the list is non-empty but this information is not available anywhere else in the program
The function in my example does statically define that the returned list is non-empty. A "parser" would maybe return the non-empty list if parsing was successful. That's how parsers work.
[0] The requirement from the post is, in fact, to only have a single file path. That is the only data actually being used (i.e. required). The other intermediate data structures are a choice of the author.
The post is showing how using more expressive types can simplify your code through a very simple example. You started out saying the NonEmpty type is unnecessary and now you're complaining it's not complicated enough, so it's not clear what your actual objection is here.
> The function in my example does statically define that the returned list is non-empty
The type given in your example was
getConfDirs :: Maybe [FilePath]
> A "parser" would maybe return the non-empty list if parsing was successful
That's exactly what the nonEmpty function in the post does:
nonEmpty :: [a] -> Maybe (NonEmpty a)This is called "using a type system" and has nothing to do with parsing or validation. You just don't "get it" I suppose. I feel like we are talking right past each other. You are so hung up on the types that you are just failing to take in the essence of what's going on.
I'll say this one more time: the specific type returned by `getConfDirs` is completely irrelevant -- other than whether it is wrapped in `Maybe` or not (because this best-illustrates parsing vs. validation). The returned type is an implementation detail that is chosen by the author. It is not necessary or "required" that we parse a string into a list (read that again). It's really quite simple:
// this is parsing
getConfDirs :: Maybe Config
// this is validation
getConfDirs :: Config // might throw
// more parsing
maybeCacheDir <- (confDirs >>= first) // or second, third, fourth, etc.
// 1. This is their first example
class ConfigurationDirectories {
dirs: FilePath[];
constructor(env) {
let dirs = env("config").split(",");
if (dirs.length < 1) throw "Error!";
this.dirs = dirs;
}
get cacheDir() {
if (this.dirs.length < 1) throw "Cannot happen!";
return this.dirs[0];
}
}
// 2. This is their "fixed" example with all sorts of unnecessary "NonEmpty" gymnastics because they have chosen the wrong abstraction
type NonEmpty<T> = [T, ...T[]];
const eg: NonEmpty<string> = []; // error
class ConfigurationDirectories {
dirs: NonEmpty<FilePath>;
constructor(env) {
let dirs = env("config").split(",");
if (dirs.length < 1) throw "Error!";
this.dirs = dirs as NonEmpty<FilePath>;
}
get cacheDir() {
// now the compiler also knows dirs is not empty
return this.dirs[0];
}
}
// 3. This is BETTER than their "fixed" example because it is even simpler
class ConfigurationDirectories {
cacheDir: FilePath;
constructor(env) {
let dirs = env("config").split(",");
if (dirs.length < 1) throw "Error!";
this.cacheDir = dirs[0];
}
}
// usage
const config = new ConfigurationDirectories(getEnv());
const cache = initializeCache(config.cacheDir);
I'm not really sure why you are dying on this hill. You can't "win" this argument. The best you can accomplish is to learn something yourself through this discussion. It's just a matter of fact that the author is (mis)using `Maybe` to the detriment of their examples. And that isn't an attack on the author! You needn't defend them. We've all written code that wasn't perfect. This is just another instance.
Maybe if the title were something like, "How to validate with static guarantees in Haskell" I wouldn't have said anything...
* I thought you were referring to my TS example (which does statically define the return-type to be non-empty)
The post is about type-driven design, which is about representing invariants in the type system where possible. The post is very clear about this. The example chosen to illustrate it is a very simple one where a list is augmented with an extra property (non-emptiness). The exact representation is not important, so yes they could have created their own custom type instead of using (NonEmpty a) but this is beside the point. You have now made two attempts to 'improve' this representation, first by just using a plain list (which the post explicitly rejects) and now by just using a single 'cache dir' instead. You can't 'simplify' the solution by just throwing away half the requirements - it's a collection of items which must also be non-empty.
> The author's example code is NOT illustrating parsing. Period
Once again, the author is very clear about what they mean by 'validation' and 'parsing':
The difference lies entirely in the return type: validateNonEmpty always returns (), the type that contains no information, but parseNonEmpty returns NonEmpty a, a refinement of the input type that preserves the knowledge gained in the type system.
You appear to be insisting that validation is just anything that throws exceptions, but this is wrong - validation is when the properties being checked are not reflected in the input type. Parsers have to be able to signal errors, and exceptions is one of the ways of doing that. This is why your previous example of 'parsing' is just validating:
const dirs = getEnv("dirs").split(",");
if (dirs.length < 1) throw "ERROR";
return dirs;
> Their examples are defining a function with a guard that validates the input. The author then get confused and decides to go on this side-quest of how to trick the compiler because the first function wasn't actually accomplishing their goal (they have to validate twice!). But you know what would have avoided all of it? Parsing
This is literally what the post is showing by switching
getConfigurationDirectories :: IO [FilePath]
getConfigurationDirectories :: IO (NonEmpty FilePath)
> It's just a matter of fact that the author is (mis)using `Maybe` to the detriment of their example
There's no mis-use of Maybe in the post, and as I've already explained, the point of the post is to eliminate Maybes. It's only used in two places - to represent the partiality of the head and nonEmpty functions.
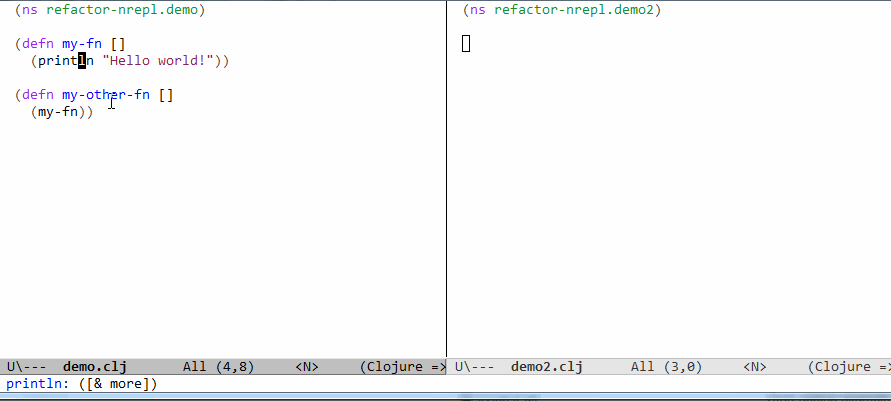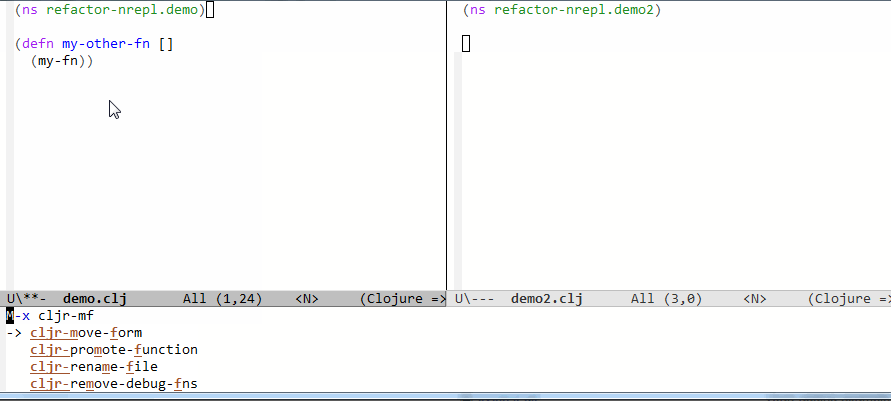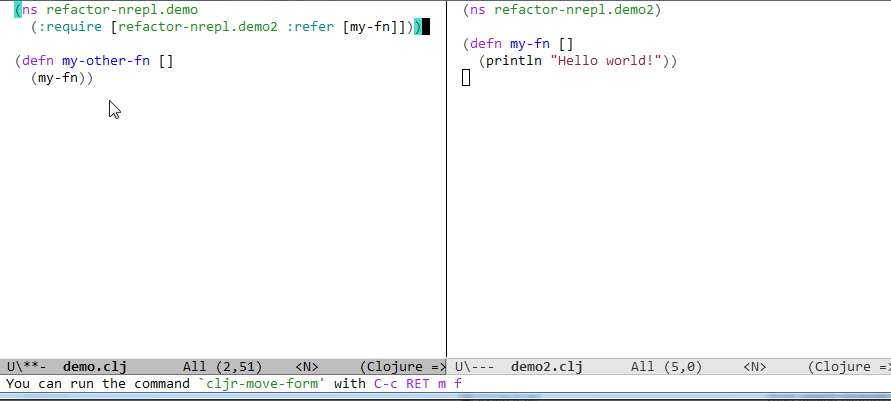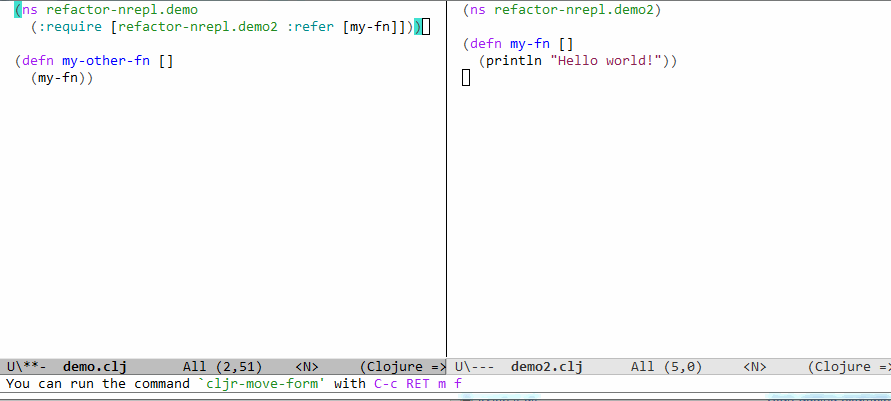{kind=link}