I think it's really sad, because when I don't see docs clearly stating the limits, I assume the worst and avoid the service.
Every environment has its footguns, after all.
It doesn't come up as often anymore since we generally have so many options at our fingertips, but when push comes to shove you will still discover this idea rattling around in people's skulls.
I, for one, prefer the calm way.
1. Never get involved in a land war in Asia
2. Never go in against a Sicilian when death is on the line
3. Never communicate through the filesystem
Earlier, we couldn't even figure out lifecycle policies to expire objects since naturally every PM had a different opinion on the data lifecycle. So it was old-fashioned cleanup jobs that were scheduled and triggered when a byzantine set of conditions were met. Sometimes they were never met - cue bill spike.
Thankfully, all the new data privacy & protection regulations are a life-saver. Now, we can blindly delete all associated data when a customer off-boards or trial expires or when data is no longer used for original purpose. Just tell the intransigent PM's that we are strictly following govt regulations.
That "absolutely essential thing" isn't essential any more when there is a possible GDPR/CCPA violation with a significant fine just around the corner.
I'm not intentionally trying to shill but this is exactly why people choose to use Vantage. We give them a set of features for automating and understanding what they can do to manage and save on costs. We're also adding multi-cloud support (GCP is in early access, Azure is coming) to be a single pane of glass into cloud costs.
If anyone needs help on this stuff, I really love it. We have a generous free tier and free trial. We also have a Slack community of ~400 people nerding out on cloud costs.
I gave vantage.sh 5 minutes and did not see anything for S3 that is not already available from the built-in Cost Explorer, Storage Lens, Cost and Usage Reports, and taking 1 hour to study the docs https://docs.aws.amazon.com/AmazonS3/latest/userguide/Bucket...
Most "cloud optimisation" products want to tell you which EC2 instance type to use, but can't actually give actionable advice for S3. Happy to be corrected on this.
Lifecycle rules are also welcome. Writing them yourself was always a pain and tended to be expensive with list operations eating up that api calls bill.
----
Once I supported an app that dumped small objects into s3 and begged the dev team to store the small objects in oracle as BLOBS to be concatenated into normal-sized s3 bjects after a reasonable timeout where no new small objects would reasonably be created. They refused (of course) and the bills for managing a bucket with millions and millions of tiny objects were just what you expect.
I then went for a compromise solution asking if we could stitch the small objects together after a period of time so they would be eligible for things like infrequent access or glacier but, alas, "dev time is expensive you know" so N figure s3 bills continue as far as I know.
This hits home so hard that it hurts. In my case is not S3 but compute bills but the core concept is the same.
Also S3 should no-op transitions for objects smaller than the break-even size for each storage class, even if you ask it to.
If I ever get to be a manager I'd go for an idea such as yours. Though I suspect too many managers are too far removed from the technical aspect of things and don't listen nearly enough.
If you replace all your hardware every year, the cloud is 4x more expensive. If you manage to use your getto-cloud for 5 year, you are 20x cheaper than Amazon.
To store one TB per person on this planet in 2022, it would take a mere $500M to do that. That's short change for a slightly bigger company these days.
I guess by 2030 we should be able to record everything a human says, sees, hears and speaks in an entire life for every human on this planet.
And by 2040 we should be able to have machines learning all about human life, expression and intelligence to slowly making sense of all of this.
That's a very good point.
Are you employed?
Would you like to join Meta?
A lot of sites like to do things like this for some reason. I haven't figured out why. I like to use Stylus to mitigate these if I can, rather than enabling JavaScript.
(presented as a data point for any poor soul trying to replicate your problem)
Here's an archive link that works without any tracking, ads, Javascript etc.: https://archive.is/F5KZd
How do you manage to navigate the web with that on by default? It breaks just about everything since nothing is a static site these days.
I wrote some tooling to help me with the cleanup. It's available on Github: https://github.com/someengineering/resoto/tree/main/plugins/... consisting of two scripts, s3.py and delete.py.
It's not exactly meant for end-users, but if you know your way around Python/S3 it might help. I build it for a one-off purge of old data. s3.py takes a `--aws-s3-collect` arg to create the index. It lists one or more buckets and can store the result in a sqlite file. In my case the directory listing of the bucket took almost a week to complete and resulted in a 80GB sqlite.
I also added a very simple CLI interface (calling it virtual filesystem would be a stretch) that allows to load the sqlite file and browse the bucket content, summarise "directory" sizes, order by last modification date, etc. It's what starts when calling s3.py without the collect arg.
Then there is delete.py which I used to delete objects from the bucket, including all versions (our horrible bucket was versioned which made it extra painful). On a versioned bucket it has to run twice, once to delete the file and once to delete the then created version, if I remember correctly - it's been a year since I built this.
Maybe it's useful for someone.
I thought, S3 can move stuff to cheaper storage automatically after some time.
If AWS' own tools work for you it's surely the better solution than my scripts. Esp. if you need something on an ongoing bases.
> The files are stored on a physical drive somewhere and indexed someplace else by the entire string app/events/ - called the prefix. The / character is really just a rendered delimiter. You can actually specify whatever you want to be the delimiter for list/scan apis.
> Anyway, under the hood, these prefixes are used to shard and partition data in S3 buckets across whatever wires and metal boxes in physical data centers. This is important because prefix design impacts performance in large scale high volume read and write applications.
If the delimiter is not set at bucket creation time, but rather can be specified whenever you do a list query, how can the prefix be used to influence where objects are physically stored? Doesn't the prefix depend on what delimiter you use? How can the sharding logic know what the prefix is if it doesn't know the delimiter in advance?
For example, if I have a path like `app/events/login-123123.json`, how does S3 know the prefix is `app/events/` without knowing that I'm going to use `/` as the delimiter?
But as a bonus, now you face huge risks and liabilities from single button pushes and none of those skills you learned are transferrable outside of AWS so you'll have to learn them again for gcloud, again for azure, again for Oracle ....
The egress and early deletion fees on those "cheaper options" killed a company that I had to step in and save.
Who would buy that? I guess if this happened enough then people would start "data salvager" companies that specialize in going through data they have no schema for looking for a way to sell something of it to someone else. I have to imagine the margins in a business like that would be abysmal, and all the while you'd be in a pretty dark place ethically going through data that users never wanted you to have in the first place.
Of course, all these questions are moot because if this happened the GDPR would nuke the cloud provider from orbit.
Proven by the fact that they happily went on to pay the bill for the next 6 months.
"This S3 request rate performance increase removes any previous guidance to randomize object prefixes to achieve faster performance. That means you can now use logical or sequential naming patterns in S3 object naming without any performance implications."
https://aws.amazon.com/about-aws/whats-new/2018/07/amazon-s3...
And couldn't that data be stored in an actual database?
It's cheaper to store them in S3 over a DB and use tools like Athena or Redshift spectrum to query.
And couldn't that data be stored in an actual database?
That overhead doesn't mean much if you have 10 users and 1gb of data. But it adds up in very large systems.
However it feels like something at that scale will only ever realistically be dealt with by enterprise-level software, and I'd hazard a guess that most developers - even those reading HN - are not working on enterprise-level systems.
So I'm wondering what "regular devs" are using cloud buckets for at such a scale over regular DBs.
- But why SageMaker?
- Why do some orgs choose to put almost everything in 1 buckets?
The article seems to be making the case it's because the delimiter makes it seem like there's a real hierarchy. So the ramifications of /bucket/1 /bucket/2 versus /bucket1/ /bucket2/ aren't well known until it's too late.
What's the difference?
Why single bucket? Once someone refers to a bucket as "the" bucket - it is how it will forever be.
You could ask the same thing of most times it gets used for ML stuff as well.
> Why do some orgs choose to put almost everything in 1 buckets?
Anecdote: ours does because we paid (Multinational Consulting Co)™ a couple of million to design our infra for us, and that's what the result was.
2 some jobs make a lot of data
There’s an important moment in the story, where they realize the fix will incur a one-time fee of $100,000. No one in engineering can sign off on that amount, and no one wants to try to explain it to non-technical execs.
They don’t explain why. But it’s probably because they expect a negative response like “how could you let this happen?!” or “I’m not going to pay that, find another way to fix it.”
In a lot of organizations it’s easier to live with a steadily growing recurring cost than a one-time fee… even if the total of the steady growth ends up much larger than the one-time fee!
It’s not necessarily pathological. Future costs will be paid from future revenue; whereas a big fee has to be paid from cash on-hand now.
But sometimes the calculation is not even attempted because of internal culture. When the decision is “keep your head down” instead of “what’s the best financial strategy,” that could hint at even bigger potential issues down the road.
Lifecycle rules can filter by min/max object size. (since Nov 2021)
Not easy, but is possible and effective.
Feel free to ask if you need help.
Do you have another, better, idea?
Anything limitless/easiest has a higher hidden cost attached.
We did an analysis of S3 storage levels by profiling 25,000 random S3 buckets a while back for a comparison of Amazon S3 and R2* and nearly 70% of storage in S3 was StandardStorage which just seems crazy high to me.
* https://www.vantage.sh/blog/the-opportunity-for-cloudflare-r...
Lifecycle policies are simple in concept, but it's actually not simple to decide what they should be in many cases.
Given the article quotes $100k to run an inventory (and $100k/month in standard storage) it's likely most of your objects are smaller than 128KiB and so probably wouldn't benefit from cheaper storage options (although it's possible this is right on the cusp of the 128KiB limit and could go either way).
Honestly, if you have a $1.2m/year storage bill in S3 this would be the time to contact your account manager and try to work out what could be done to improve this. You probably shouldn't be paying list anyway if just the S3 component of your bill is $1.2m/year.
One time I had to write a special mapreduce that did a multiple-step-map to converted my (deeply nested) directory tree into roughly equally sized partitions (a serial directory listing would have taken too long, and the tree was really unbalanced to partition in one step), then did a second mapreduce to map-delete all the files and reduce the errors down to a report file for later cleanup. This meant we could delete a few hundred terabytes across millions of files in 24 hours, which was a victory.
While developing GitFront, we were using S3 to store individual files from git repositories as single objects. Each of our users was able to have multiple repositories with thousands of files, and they needed to be able to delete them.
To solve the issue, we implemented a system for storing multiple files inside a single object and a proxy which allows accessing individual files transparently. Deleting a whole repository is now just a single request to S3.
Sure we could start with something simpler, but as you may have noticed, even the more basic hosting providers like DigitalOcean and Linode have been adding S3-compatible object storage because of its proven utility.
In terms of making something meaningfully simpler, I think Heroku was the high water mark. But even though it was a great developer experience, the price/performance barriers were a lot more intractable than dealing with AWS.
Yes, and making scaling frictionless brings a very tiny bit of value for everybody, but a huge amount of value for the cloud operator. Any bit of friction would completely remove that problem.
Also, focusing on scaling before efficiency benefits nobody but the cloud provider.
Not sure how it scales for production loads but my experience was so positive I'll probably go back for future projects.
AWS allows you to store gigantic amounts of data, thus lowering the bar dramatically for the kinds of things that we will keep.
This invariably creates a different kind of problem when those thresholds are met.
In this case, you have 'so much data you don't know what to do with it'.
Akin to having 'really cheap warehouse storage space' that just gets filled up.
"It's now complexity and scale makes it unusable for newer devs. I'"
No - the 'complexity' bit is a bit of a problem, but not the scale.
The 'complexity bit' can be overcome if you stick to some very basic things like running Ec2 instances and very basic security configs. Beyond that, yes it's hard. But the 'equivalent' of having your own infra would be simply to have a bunch of Ec2 instances on AWS and 'that's it' - and that's essentially achievable without much fuss. That's always an option to small companies, i.e. 'just fun some instances' and don't touch anything else.
I started using S3 early in my career and didn't see this problem. I always thought in data retention during design phase.
My opinion is that lazy, careless or under time pressure developers will not, and then will get bitten. But it would happen to any tool. Maybe a different problem, but they'll always get bitten hard ...
But I learned a whole lot of new things from this article that I didn't understand from reading the AWS documentation, let alone think I had to even concern myself with some of these issues. Spotty warnings about transitional request charges?
Anyway, kudos to you for always thinking about (and i hope actualizing) retention during policies the design phase. However, while I certainly think devs bare some of this responsibility, I'm sure they're usual met with all of the usual excuses and kicking the can down the road line of reasoning from PM/PO/etc that lead to these kinds of nightmares in the beginning... Then again, it will probably be another developer or system admins' nightmare when it becomes an issue.
Even as an experience engineer, I still struggle setting the retention policy at the beginning of a new design... I'd love to hear any advice you have about how manage this incredibly important aspect?
I mean, at some point, if you're (say) using some insane amount of storage, you're going to pay for that.
I would agree that getting alerting right for billing-relevant events at whatever you're currently operating at should be a lot easier than it is. And I agree that there is a lot of room to baby-proof some of the less obvious mistakes that people frequently make, to better expose the consequences of some changes, etc.
But the flip side is that infra has always been expensive, and vendors have always been more than happy to sell you far more than you need along with the next new shiny whatever.
To the extent that these are becoming implicit decisions made by developers rather than periodic budgeted refresh events built by infra architects, developers need to take responsibility for understanding the implications of what they're doing.
An example might be something like a Kubernetes-only cloud driven entirely by Git-ops. Not TFVC, or CVS, or Docker Swarm, or some hybrid of a proprietary cloud and K8s. Literally just a Git repo that materialises Helm charts onto fully managed K8s clusters. That's it.
If you try to do anything similar in, say, Azure, you'll discover that:
Their DevOps pipelines are managed by a completely separate product group and doesn't natively integrate into the platform.
You now have K8s labels and Azure tags.
You now have K8s logging and Azure logging.
You now have K8s namespaces and Azure resource groups.
You now have K8s IAM and Azure IAM.
You now have K8s storage and Azure disks.
Just that kind of duplication of concepts alone can take this one system's complexity to a level where it's impossible for a pure software development team to use without having a dedicated DevOps person!
Azure App Service or AWS Elastic Beanstalk are similarly overly complex, having to bend over backwards to support scenarios like "private network integration". Yeah, that's what developers want to do, carve up subnets and faff around with routing rules! /s
For example, if you deploy a pre-compiled web app to App Service, it'll... compile it again. For compatibility with a framework you aren't using! You need a poorly documented environment variable flag to work around this. There's like a dozen more like this and clocking up so fast.
Developers just want a platform they can push code to and have it run with high availability and disaster recovery provided as-if turning on a tap.
I believe, AWS' usage-based billing make for long-tail surprises because its users are designing systems exactly as one would expect them to. For example, S3 is never meant for a bazillion small objects which Kinesis Firehose makes it easy to deliver to it. In such cases, dismal retrieval performance aside [0], the cost to list/delete dominate abnormally.
We spin up a AWS Batch job every day to coalesce all S3 files ingested that day into large zlib'd parquets (kind of reverse VACCUM as in postgres / MERGE as in elasticsearch). This setup is painful. I guess the lesson here is, one needs to architect for both billing and scale, right from the get go.
> S3 is never meant for a bazillion small objects which Kinesis Firehose makes it easy to deliver to it
Are you saying Firehose increases the likelihood of creating the "small file problem"?
If so, isn't this exactly what Firehose tries to prevent? Sure, you can set all the thresholds low and unnecessarily generate lots of small files, but you can tune those thresholds to maximize record/file size and attain a reasonable latency. If there's a daily batch job to make this data useful, then who cares about latency?
Also, why would you run a daily batch job to coalesce all these files into parquet files instead of letting Firehose just do that for you. It can also do a certain amount of partitioning if it's required.
The cloud abstracts SO MUCH complexity from the user. The fact that people are then gleefully taking these "simple" services and overloading them with way too much data, and way too much complexity on top is not a failure of the underlying primitives, but a success.
Without these cloud primitives, the people footgunning themselves with massive bills would just not have a working solution AT ALL.
Sometimes guard rails are a good thing, and the AWS philosophy has very firmly been against guard rails, especially related to spending. The issue has come up here again and again that AWS refuses to add cost limits, even though they are capable of it. Azure copied this limitation. I don't mean that they didn't implement cost limits. They did! The Visual Studio subscriber accounts have cost limits. I mean that they refused to allow anyone to use this feature in PayG accounts.
Let me give you a practical example: If I host a blog on some piece of tin with a wire coming out of it, my $/month is not just predictable, but constant. There's a cap on the outbound bandwidth, and a cap on compute spending. If my blog goes viral, it'll slow down to molasses, but my bank account will remain unmolested. If a DDoS hits it, it'll go down... and then come back up when the script kiddie get bored and move on.
Hosting something like this on even the most efficient cloud-native architecture possible, such as a static site on an S3 bucket or Azure Storage Account is wildly dangerous. There is literally nothing I can do to stop the haemorrhaging if the site goes popular.
Oh... set up some triggers or something... you're about to say, right? The billing portal has a multi-day delay on it! You can bleed $10K per hour and not have a clue that this is going on.
And even if you know... then what? There's no "off" button! Seriously, try looking for "stop" buttons on anything that's not a VM in the public cloud. S3 buckets and Storage Accounts certainly don't have anything like that. At best, you could implement a firewall rule or something, but each and every service has a unique and special way of implementing a "stop bleeding!" button.
I don't have time for this, and I can't wear the risk.
This is why the cloud -- as it is right now -- is just too dangerous for most people. The abstractions it provides aren't just leaky, the hole has razor-sharp edges that has cut the hands of many people that think that it works just like on-prem but simpler.
Actually, I disagree with one statement: "AWS was built for a specific purpose and demographic of user". AWS wasn't built for anyone. It was built for everyone, and is thus even reasonably productive for no one. AWS's entire product development methodology is "customer asks for this, build it"; there's no high level design, very few opinions, five different services can be deployed to do the same thing, it's absolute madness and getting worse every year. Azure's methodology is "copy whatever AWS is doing" (source: engineers inside Azure), so they inherit the same issues, which makes sense for Microsoft because they've always been an organization gone mad.
If there's one guiding light for Big Cloud, its: they're built to be sold to people who buy cloud resources. I don't even feel this is entirely accurate, given that this demographic of purchaser should at least, if nothing else, be considerate of the cost, and there's zero chance of Big Cloud winning that comparison without deceit, but if there was a demographic that's who it'd be.
> I'd argue, we need a completely new experience for the next generation.
Fortunately, the world is not all Big Cloud. The work Cloudflare is doing between Workers & Pages represents a really cool and productive application environment. Netlify is another. Products like Supabase do a cool job of vendoring open source tech with traditional SaaS ease-of-use, with fair billing. DigitalOcean is also becoming big in the "easy cloud" space, between Apps, their hosted databases, etc. Heroku still exists (though I feel they've done a very poor job of innovating recently, especially in the cost department).
The challenge really isn't in the lack of next-gen PaaS-like platforms; its in countering the hypnosis puked out by Big Cloud Sales in that they're the only "secure" "reliable" "whatever" option. This hypnosis has infected tons of otherwise very smart leaders. You ask these people "lets say we are at four nines now; how much are you willing to pay, per month, to reach five nines? and remember Jim, four-nines is one hour of downtime a year." No one can answer that. No one.
End point being: anyone who thinks Big Cloud will reign supreme forever hasn't studied history. Enterprise contracts make it impossible for them to clean the cobwebs from their closets. They will eventually become the next Oracle or IBM, and the cycle repeats. It's not an argument to always run your own infra or whatever; but it is an argument to lean on and support open source.
I guess this, but it's funny to see it confirmed.
I got suspicious when I realised Azure has many of the same bugs and limitations as AWS despite being supposedly completely different / independent.
AFAIK there is server-side paging implemented in the List* API operations that the Console UI should be using so that the number of objects in a bucket should not significantly impact the webpage performance.
But who knows what design flaws lurk beneath the console.
Curious to know what you find.
Does it happen only on opening heavy buckets? or the entire S3 console? Different Browser / incognito / different machine ...dont make a difference?
I worked somewhere that a person decided using Twitter Firehose was a good idea for S3. Keyed by tweet per file.
Ended up figuring out a way to get them in batches and condense. Ended up costing about $800 per hour to fix coupled with lifecycle changes they mentioned.
You have a versioned bucket with a lot of delete markers in it. Make sure you've got a lifecycle policy to clean them up.
You don't peer into a bucket with a billion objects and ask for a complete listing, or accounting of bytes. There are tools and APIs for that.
That's what I do with my thousands of buckets and billions of files (dashboards).
Disclosure, co-founder here, we're building one of those CLIs. We started as an internal project at D2iQ (my co-founder Lukas commented further up), with tooling to collect an inventory of AWS resources and be able to search it easily.
A fictitious example which is close to reality:
In parallel, you write a million objects each to:
tomato/red/...
tomato/green/...
tomatoes/colors/...
tomato/r
tomato/g
tomatoes
tomatoes/colors/...
bananas/...
t
b
--
The delimiter is just a wildcard option. The system is just a key value store, essentially. Specifying a delimiter tells the system to transform delimiters at the end of a list query like
my/path/
my/path/[^/]+/?I find the S3 documentation and API to be really confusing about this. For example, when listing objects, you get to specify a "prefix". But this seems to be not directly related to the automatically-determined prefix length based on your access patterns. And [1] says things like "There are no limits to the number of prefixes in a bucket.", which makes no sense to me given that the prefix length is something that S3 decides under the hood for you. Like, how do you even know how many prefixes your bucket has?
[1] https://docs.aws.amazon.com/AmazonS3/latest/userguide/optimi...
makes sense
> The system realizes your new access pattern and determines new prefixes and moves data around to accommodate what it thinks your needs are.
What does "determines new prefixes" mean? Obviously AWS isn't going to come up with new prefixes and change object names.
So does AWS maintain prefix-surrogates (prefix sub-string(0,?) references) and those are what actually gets shuffled around to handle the new unbalanced workload? Sort of like resharding?
Moreover, since it's really prefix-surrogates being used, the recommendation of randomizing prefixes can be replace with randomizing prefix-surrogates and delegated to AWS, removing the prior responsibility from the customer. Hence the 2018 announcement https://aws.amazon.com/about-aws/whats-new/2018/07/amazon-s3...
The object name is the entire label, and every character is equally significant for storage. When listing objects, a prefix filters the list. That’s all. However, S3 also uses substrings to partition the bucket for scale. Since they’re anchored at the start, they’re also called prefixes.
In my view, it’s best to think of S3’s object indexing as a radix tree.
This article, as if you couldn’t guess from the content, is written from a position of scant knowledge of S3, not surprising it misrepresents the details.
What's the delimiter parameter for then?
https://docs.aws.amazon.com/AmazonS3/latest/API/API_ListObje...
You don't need to mess with prefixing all your files. They auto level the cluster for you [1].
[1] https://cloud.google.com/storage/docs/request-rate#redistrib...
https://aws.amazon.com/about-aws/whats-new/2018/07/amazon-s3...
The problem becomes unusual burst load - usually from infrequent analytics jobs. The indexing cant respond fast enough.
> 3,500 PUT/COPY/POST/DELETE requests per second per prefix
> 5,500 GET/HEAD requests per second per prefix
Most of those APIs don't even take a delimiter. So for these limits, does the prefix get inferred based on whatever delimiter you've used for previous list requests? What if you've used multiple delimiters in the past?
Basically what I'm trying to determine is whether these limits actually mean something concrete (that I can use for capacity planning etc.), or whether their behavior depends on heuristics that S3 uses under the hood.
I'm fine with S3 optimizing things under the hood based on access my patterns, but not if it means I can't reason about these limits as an outsider.
The filesystem is hierarchical, but the delete operation still needs to visit all the leaves.
https://awscli.amazonaws.com/v2/documentation/api/latest/ref...
Another option are LVM or btrfs subvolumes which can be discarded without recursive traversal.
Google for this problem. There are surprisingly many creative ideas, many which also surprisingly are a lot better than the built in rm command.
1. Try parallelization of your calls. Deleting 20 objects in parallel should take the same time as deleting 1.
2. Try to run deletion from an AWS machine in the same region as the S3 bucket (yes buckets are regional, only their names are global). Within-datacenter latency should be lower than between your machine and datacenter.
1) The performance per partition increased
2) The way AWS created partitions changed
When I was at Mozilla, one thing I worked on was Firefox's crash reporting system. It's S3 storage backend wrote raw crash data with the key in the format `{prefix}/v2/{name_of_thing}/{entropy}/{date}/{id}`. If I remember correctly, we considered this a limitation since the entropy was so far down in the key. However, when we talked to AWS Support they told us their was no longer a need to have the entropy early on; effectively S3 would "figure it out" and partition as needed.
EDIT: https://news.ycombinator.com/item?id=30373375 is a good related comment.
Firehose makes it easy to do so (when the thresholds are too low, as you point out). That is, it'd happily chug along and do what you ask of it to. Sometimes, these problems only manifest in the long run (kind of like a frog in boiling water).
> Also, why would you run a daily batch job to coalesce all these files into parquet files instead of letting Firehose just do that for you.
Firehose recommends that the output be at least 64M to 128M for parquet files... we don't have anywhere near that much amount of data to yeet out of Firehose, especially because data is partitioned per-user (and a single user doesn't generate anywhere near that much data, and so we're left with the current setup). And so: It was either to let Firehose batch the data up in larger parquets (and run the partitioning job offline), or employ its partitioning magic online (and run the merge job offline, on-demand). We chose the latter for cost efficiency given our workloads.
If a given process generates $1 in revenue over a year, and it takes pennies for AWS services, that's a good sign your design is not going to break the company's pockets down the road.
In some cases, it's not easy to narrow the unit economics so much, which adds uncertainty to your premises, and there might be market fluctuations that change the unit economics in the future. I try to anticipate which areas are most likely to change and think of a trade-off in terms of short term speed and flexibility to change later, if needed. Almost always they're a trade off.
I disagree. Using AWS in a frictionless way has made the difference between not deploying applications and deploying them. In one example, I used S3 and EC2 to deploy an app used by several thousand users at work - the deployment was completely scripted and tested before the old app was taken down. It eliminated errors in deploying, increased frequency of denying (which enabled faster security patches), reduced down time from 6 hours to zero, enabled new features for our users (due to scripted testing). Everyone won - and I got a promotion :)
So for instance "/foo/bar.txt" and "/foo//bar.txt" are different files in S3, even though they'd be the same file in a filesystem.
This gets pretty fun if you want to mirror a S3 structure on-disk, because the above suddenly causes a collision.
S3 simply looks at the common string prefixes in your object names and uses that to internally shard objects, so you can achieve a multiple of those request limits.
aaa122348
aaa484585
bbb484858
bbb474827
Would have same performance as:
aaa/122348
aaa/484585
bbb/484858
bbb/474827
From: https://docs.aws.amazon.com/AmazonS3/latest/userguide/lifecy...
For the purposes of this article, you can probably have more intuitive, sensible lifecycle policies across multiple buckets than you can trying to set policies on specific paths within a single bucket. Something like "ShortLifeBucket" and "LongLifeBucket" would allow you to have items with similar prefixes (something like a "{bucket}/anApplication/file1.csv" in each bucket) that then have different lifecycle policies
Got any recommended literature?
When I worked in Azure, I accidentally created some internal resources in a personal account. I didn’t have the ability to delete them after I left; the only way to do so was to cancel the credit card and let the grace period expire.
Read more about the differences in drives here: https://blog.storagecraft.com/consumer-vs-enterprise-hard-dr...
Full bucket list, then two text prefix, then an (empty) folder list
sokoloff@ Downloads % aws s3 ls s3://foo-asdf
PRE bar-folder/
PRE baz-folder/
2022-02-17 09:25:38 0 bar-file-1.txt
2022-02-17 09:25:42 0 bar-file-2.txt
2022-02-17 09:25:57 0 baz-file-1.txt
2022-02-17 09:25:49 0 baz-file-2.txt
sokoloff@ Downloads % aws s3 ls s3://foo-asdf/ba
PRE bar-folder/
PRE baz-folder/
2022-02-17 09:25:38 0 bar-file-1.txt
2022-02-17 09:25:42 0 bar-file-2.txt
2022-02-17 09:25:57 0 baz-file-1.txt
2022-02-17 09:25:49 0 baz-file-2.txt
sokoloff@ Downloads % aws s3 ls s3://foo-asdf/bar
PRE bar-folder/
2022-02-17 09:25:38 0 bar-file-1.txt
2022-02-17 09:25:42 0 bar-file-2.txt
sokoloff@ Downloads % aws s3 ls s3://foo-asdf/bar-folder
PRE bar-folder/Here is some AWS documentation on it:
https://docs.aws.amazon.com/AmazonS3/latest/userguide/optimi...
> For example, your application can achieve at least 3,500 PUT/COPY/POST/DELETE or 5,500 GET/HEAD requests per second per prefix in a bucket. There are no limits to the number of prefixes in a bucket. You can increase your read or write performance by using parallelization. For example, if you create 10 prefixes in an Amazon S3 bucket to parallelize reads, you could scale your read performance to 55,000 read requests per second.
Related to your question, even if we just stick to `/` because it seems safer, does that mean that "foo/bar/baz/1/" and "foo/bar/baz/2/" are two prefixes for the point of these request speed limits? Or does the "prefix" stop at the first "/" and files with these keypaths are both in the same "prefix" "foo/"?
Note there was (according to docs) a change a couple years ago that I think some people haven't caught on to:
> For example, previously Amazon S3 performance guidelines recommended randomizing prefix naming with hashed characters to optimize performance for frequent data retrievals. You no longer have to randomize prefix naming for performance, and can use sequential date-based naming for your prefixes.
The ListObjects api will omit all objects that share a prefix that ends in the delimiter, and instead put said prefix into the CommonPrefix element, which would be reflected as PRE lines. (So with a delimiter of '/', it basically hides objects in "subfolders", but lists any subfolders that match your partial text in the CommonPrefix element).
By default `aws s3 ls` will not show any objects within a CommonPrefix but simply shows a PRE line for them. The cli does not let you specify a delimiter, it always uses '/'. To actually list all objects you need to use `--recursive`.
The output there would suggest that bucket really did have object names that began with `bar-folder/`, and that last line did not list them out because you did not include the trailing slash. Without the trailing slash it was just listing objects and CommonPrefixes that match the string you specified after the last delimiter in your url. Since only that one common prefix matched, only it was printed.
If the docs are misrepresenting the details, who can blame the author of the post?
The OP does not read the docs, makes bad assumptions repeatedly throughout, and then reaps the consequences.
There’s WAF with rate based limiting to prevent script kiddies for randomly hitting your URLs for files to download and run up your egress prices. Waf costs $5/month plus a flat fee per extra rule.
For DDOS protection there’s Shield which is built into cloudfront and should be enough for most people but if you need more control they have Shield Advanced.
The “Stop Button” for s3 is an application layer responsibility, imho though S3 Should make clean up easier.
This kind of "blame the user" thinking is why I avoid the cloud for my own use, and can't recommend it for most customers unless they have a specific reason.
If you want to spend the absolute bare minimum price,you get the bare minimum service.
Not sure how this is blame the user. If you are setting up a bare metal server for a client and they don't ask you for (say) DDOS protection, will you still set up a DDOS protection protocol for them? I would think not since most people would try to match what a client asks for and maybe throw in some freebies.
If after that, they get hit by DDOS, the onus is on them to have told you to plan ahead for it and knowing this is not "blame the user'.
This is exactly what AWS is also offering - a basic setup and extra bells and whistles to protect yourself from possible issues based on your threat model.
Maybe I'm missing something in your response.
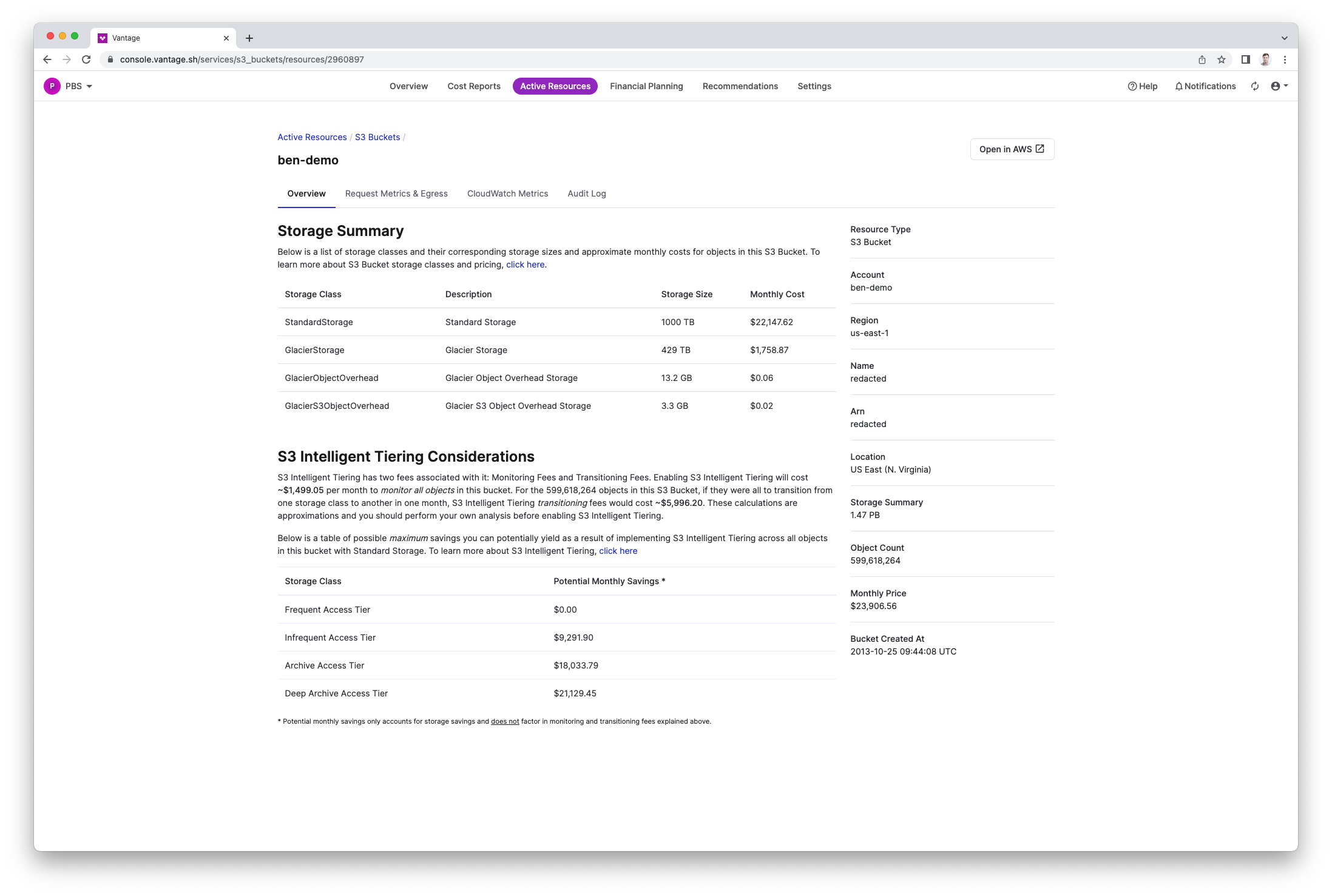
Vantage automates everything you just mentioned to allow you to make quicker decisions. Here's a screenshot of what we do on a S3 Bucket basis: https://s3.amazonaws.com/assets.vantage.sh/www/s3_example.pn...
We'll profile storage classes and the number of objects, tell you the exact cost of turning on things like intelligent tiering and how much that will cost with specific potential savings. This is all done out of the box, automatically - and we profile List/Describe APIs to always discover newly created S3 Buckets.
From speaking with hundreds of customers, I can also assure you that at a certain scale, billing does not take an hour...there are entire teams built around this at larger companies.
From [0]:
> This S3 request rate performance increase removes any previous guidance to randomize object prefixes to achieve faster performance. That means you can now use logical or sequential naming patterns in S3 object naming without any performance implications. This improvement is now available in all AWS Regions. For more information, visit the Amazon S3 Developer Guide.
[0]: https://aws.amazon.com/about-aws/whats-new/2018/07/amazon-s3...
As a sysadmin, I hate that too.
For instance when they create a provisioning request, are you able to set an extremely low threshold? When they say that won't do, the cost increases and their able to see/understand and start to care about the actual lifecycles of what they're creating?
Surely there is a way to project and monitor the cost of their resources over time, and deliver them an invoice on a regular basis? In other words something like a cost attribution model? That way when the bills start to increase dramatically overtime, pinpointing the heavy hitters becomes trivial, and when they come knocking on your door to "do something about it" you can just say "go talk to Bob".
I don't mean to sound like I'm trivializing the problem (honestly I can relate as I've gone through it myself), but I'd love to hear how anyone else has dealt with this issue effectively.
i am a dev that has to deal with these regulations in my day to day. it is a pain, it is not freeing in any sense, and it makes my models worse.
granted, i think there are good reasons for it, but it does not make my life easier for sure.
So maybe that's why we're not good at it yet.
When you have to box things up over and over you find that the physical and mental energy around keeping it aren’t adding up. I wonder if migrating from cloud to cloud would simulate this experience.
Is my understanding correct?
1. an outage, which in reality is just an inconvenience, not the end of the world, unlike what most IT people seem to think.
2. a bill that can bankrupt you, which may as well be the end of the world for many people or small businesses. It can be literally "game over".
A bare metal box doesn't need protection from the 2nd risk. Its costs are fixed, irrespective of the amount of traffic attempting to hit it. A 100 Mbps link can't put out more than 100 Mbps, so even if you're charged by the terabyte of egress, there's a cost ceiling integrated into the hardware itself.
The cloud generally has no such limits, or much, much higher ones than is typically desirable.
Okay, here's another random example your WAF will not protect you from: cloud-hosted DNS.
The bare metal scenario is a box sitting on the end of a 1 Gbps Ethernet link. If attacked by some crazy UDP DNS flood attack, it could probably saturate that pipe and send out... 1 Gbps. On a fixed-cost-link plan this costs $0.00 additional money. You might have an outage, or merely a brown-out, but you won't see a cent added to your next bill.
On Azure's DNS Zones service, there's no "1 Gbps" pipe to rate limit them. They have infrastructure deployed globally, typically with 100 Gbps links. In practice, the DNS server probably only gets about 10 Gbps per region, but there's many regions. At 100 bytes per packet, you could be looking at a billion requests per second billed to your account, at an eyewatering $200/s or $720K/hour. Ouch!
Now, Azure will probably forgive that bill because it's clearly an attack.
But what if it isn't clearly an attack? Application Insights by design puts the Instrumentation Key into client-side JavaScript. It charges $3/GB on ingress! It's trivial to charge someone thousands or tens of thousands of dollars before they notice, and then they'd have a hard time convincing support that the traffic wasn't legitimate.
I can send a terabyte out for cents, each of which would cost some poor fool $3,000.
Good luck plugging every such hole, monitoring every alert (there's literally tens of thousands of metrics to alert on), and keeping up with every spike in billing that's a day late reporting on costs that can ramp up to thousands of dollars per minute.
I agree that the downside of scaling is the risk of running up huge bills. But the safety net to prevent the run-up is literally a monthly flat fee - $5+ $1/WAF rule. Also, you don't have to monitor every alert - just the common ones. If I had to build a comparable alerting system on bare metal, I'd go crazy.
To me, the flexibility of the cloud is worth the trade off.
> WAF will not protect you from...UDP..
Don't think WAF is the tool to protect against UDP layer attacks. Shield (which is available standard) already handles this.
To be clear, I have not had to deal with DDOS attacks. We once had to deal with was someone repeatedly downloading a 1mb gif from our website which led to big egress fees. WAF's rate based rules but an end to that nonsense.
(We're a long-time Cloudability customer; no other connection/conflict of interest here.)
You should keep a minimal set of logs necessary for audit, logs for errors which are actually errors, and logs for things which happen unexpectedly.
What people do keep are logs for everything which happens, almost all of which is never a surprise.
One needs to go through logs periodically and purge the logging code for every kind of message which doesn’t spark joy, I mean seem like it would ever be useful to know.
How are "crypto-shredding" actions propagated to the access patterns/layer?
I assume that there is an encrypted partition/cluster/shard key (in addition to similarly encrypted rows/fields) that is invalidated during the shredding causing any predicate matching on these ids to evaluate to false.
---
Now that I've typed this out, i realize that by electing to encrypt individual fields, all and any predicate matching will evaluate to false and has nothing to do with partitioning, sharding, or clustering...
I guess it would also be pretty awesome since you could invalidated entire sets of data by "shredding" grouping ids that are being used as partition/cluster/shard keys.
Now I realize that this implies that you shouldn't encrypt each and every fields of related data the same way (grouping ids), otherwise you're potentially going to end up with unique keys/ids for common attributes across sets of data... potentially rendering clustering/sharding/partition useless (cardinality too great).
While "defragging" or "rebalancing" this increasingly "sparse", old data would be expensive, surely there has to come a point where the storage costs start to exceed that of interaction costs for specific subsets of your prefixes. For instance, partitions that consist entirely of data that has had all of its respective encryption keys shredded.
---
Illuminating comment that has set my mind into overdrive... Fascinating stuff!
We did a similar thing except replacing the values with a UUID and storing the pair in a lookup table somewhere. Delete that row and none of the rest of the data is able to be tied back to a human being.
Bonus, most people didn't need that data, and it was no longer given out to everyone who grabbed the entire dataset.
{kind=link}