When hiring developers, have the candidate read existing code(freakingrectangle.wordpress.com) |
When hiring developers, have the candidate read existing code(freakingrectangle.wordpress.com) |
Something like squid game will truely find the A players. I mean, we wouldn’t want a bad hire after all, and everyone lies on their CV.
(Obviously /s)
I feel it really gives you a good impression of the level of experience the candidate has with actual coding, and opens up for a lot of related discussion, such as security implications. Without, as the article mentions, the tediousness and artificiality of whiteboard coding (which I don't want to completely dismiss, however).
We're going to be working on a lot of code together, so it makes sense to have the interview about doing exactly that.
In seriousness, through a decade of experience in AI, I have found that most “famous” and “exotic” algorithms that software engineers love testing (e.g. OP’s references to sorting, tree searching, and recursion) come up exactly never in my day-to-day.
Please, limit testing to the actual data structures and algorithms that dominate 99% of the proposed work. If the proposed work is not in a field you are truly an expert at, then don’t be responsible for technically interviewing this person.
In my branch of AI, if I’m not getting solely evaluated on my ability to work with tensors, vectors, graphs, …, then I realize there is no AI group at this company (or it is inferior in its autonomy). There are so many extremely useful specializations in real-world moonshots, that would otherwise get bludgeoned upon any interview within a general purpose software engineering culture.
and this is your response? did you come up with extremely clever reduction in the shower and wait for the first post that's tangentially relevant (and in fact embodies the opposite of what you're attacking?)
Hmmmm, really?
I feel like the answer to those questions determines which is faster. One may say that you only compare (lines_read / time_reading) and (lines_written / time_writing) to find an answer, but if we remove all "time spent thinking" from both then it kind of feels like a meaningless comparison.
Disagree. Big corps have well established processes for this and deep pockets to pay lawyers out of in case of any wrongful termination claims against them
Make sure the candidate's personality is a good fit for the team, have them do a fair coding question, and then hire them quickly. Give them 3 months to become productive and if not, fire them quickly and give a 3 month severance package.
You can probably analyze the data and figure out which of the employees are good at spotting good candidates and lean on them to make the decisions, but overall fast-hire-fast-fire is the best for everyone, except for fake candidates.
This also gives you the opportunity to take chances on borderline candidates or candidates with less experience.
Edit: obviously interviewing is one of the issues you're facing, but far from the main one. Trust is hard :)
But everywhere has code that stinks. And it's hard to find people with the skills and experience to get rid if it. Before it can be gotten rid off, it must be understood.
In a sense it might be valuable to use the poor code in a reading screen. Firstly so we can agree it stinks, and the reasons why. And secondly, to find people with the attitude required to clean up messes that they didn't create (good scouts).
Even when the job is greenfield, or extending great code, I'd rather have engineers with the battle scars of doing tough maintenance.
The management has to be set up to allow for this. People have to be able to work towards something as a team; else we are all cleaning in different directions.
Often times it requires not only a lot of skill but also a lot of work.
I can do it but be prepared to pay me 2-3 times the normal wage.
For example, I hired a backend developer last month. She already had the job because she came highly recommended from a trusted friend of mine, but she didn't know that. Here's how the interview went down:
Me: I see on your resume that you've achieved Grand Master level in Microsoft Solitaire Collection.
Her: Yes.
Me: Well, we won't waste any more time then. Welcome to the team.
I still give my team the option to decline them if there's major red flags - but I have not had that happen.
Also, a reminder...an interview it is a 2 way street. Your 1 question interview doesn't give the candidate an opportunity to interview you or your team and the "Welcome to the team" is a little presumptuous...I assume it was left out for dramatic effect and I'm sure (I hope?) you allowed the interviewee time to ask questions.
This is my first time experiencing HN deja vu :)
If the criteria that you use for engineering hires has nearly 0 overlap with the criteria that you use for engineering promotions, then I'd assert that your company is suffering from some serious cognitive dissonance.
This article describes a hiring process that is probably a lot more useful than what I've typically witnessed at the FAANG's, provided the results can be quantified.
It must surely boil down to the profession aspect. Doctors and lawyers do a period of internship after and during the degree that perhaps mitigates the uncertainty around hiring. I doubt that doctors are asked to bring in a cadaver to operate on during an interview for a new position, or lawyers are asked to jump into court unprepared and defend someone as part of the hiring practice.
It sometimes seems that programming jobs need to be a calling. Ie: you spend 50 hours a week at job doing the thing but then are also asked to have a portfolio on the side that you presumably do in your spare time.
It could just be an American thing, though. Perhaps hiring is seen as very risky because sv salaries are so out of proportion to the standard across the rest of the working environment, in addition to there being very little quality control regarding professionalism in the industry that makes technical hiring such a minefield.
I'm currently looking for someone to join our own team, I'll be taking this adjusted priority in mind.
As I'm a pure C coder, my starter question was usually something like:
a). What does malloc(0) return ? b). Why does it do that ?
The real issue is that one approach does not work for all and there need to be uniqueness to every team so an avg candidate cannot just hack the interview process. This is the problem with the current system as well since everyone uses it and its become its own nemesis.
Over the years, I found some truly awful code, in our cash cow application.
So I turned those into the smallest representations of what was bad, and showed those to candidates.
I was trying to assess, "How much will I need to mentor this person, and how hard will that be?"
I may have given bad reviews to people who deserved better, but I honestly think I never once gave a good review to someone who deserved a bad one. A few times, the company went against my suggestions, and each time, the candidate wrote some terrible, buggy code that I later had to untangle and fix.
While reading and understanding code written by others is an important skill, I am not sure it would be totally fair in an interview. The candidate might not be familiar with the particular coding style. The code can be very easy to read or very cryptic. I can write easy to read code, cryptic code or anywhere in between.
So since reading code doesn't solely depend on the candidate 's skills, basing hiring decisions solely on it, might not be the best idea.
I would see no harm, though, if part of the interview consists in testing the comprehension of well written code.
Then I was asked a brain teaser that I bombed. And that was the end of the interview.
I said. I have 5 year old twins, I'd give it to them and have them sort it.
I don't think they will do this: the interviewing process at most places seems to emulate that of the industry leader, nowadays that's google, correct me if I am wrong.
> I can quickly train a person to have knowledge in some domain,
This part I have a little bit of trouble with. If you have a trivial domain, sure. In my experience domain knowledge takes a while to truly get your head wrapped around. But I expect that's why there's always other things that people do in an interview.
Though many companies don’t care if you’re familiar with the specific language they use, because they assume a decent developer can pick up a new language, and if someone weren’t familiar with that specific language it maybe could put them at a disadvantage. Or maybe that would actually be a good test of their skills??
"Why'd you design it that way?"
"Why'd you implement it that way?"
"What alternatives did you consider?"
Interviewers be so lazy in 2022 though. 'uh um do a fizzbuzz in ten seconds no your solution not match my first mental solution bye'
but then I realised it would tell me as an interviewee how good/bad the code is before I join.
If there are no comments, loads of "clever" optimisations lots of "syntactic sugar" it would be a good time to GTFO.
It's not. You'll find plenty of anecdotes outside the US. Even just outside SV is enough to put things into question, as salaries outside SV are way lower.
>Doctors and lawyers do a period of internship after and during the degree that perhaps mitigates the uncertainty around hiring.
Two problems with this.
For one, this is changing rapidly. Any institute of higher education is becoming a worker factory focusing on what the industry wants in candidates rapidly. Despite this, interviewers continue to complain about the most minor things which in reality are very easy to grasp for people with a degree and some projects.
For two, this problem still persists after having some years of experience under your belt. If an internship mitigates the need for other professions to go through this, surely having verifiable experience should do the same. But it doesn't, and it takes away a lot of time from people to build their own portfolio to get through interviews with too.
>It must surely boil down to the profession aspect.
I don't believe so. Hiring is plagued with perfectionism and idealism, looking for the perfect candidates and failing candidates over the most minor things. You could actually be the best candidate in the world, and you'll fail because you said something or did something in a way the interviewer preemptively labels as "unviable".
The problem is actually as you point out: hiring managers are pushing risks onto individuals in the name of "calling", and loads of developers are doing nothing to push back on it. Or worse, they are encouraging it. See also why the average junior requirements includes an entire IT department's worth of skills.
I once flunked a faang interview because the interviewer mispronounced (or used the correct pronunciation I was unfamiliar with) of "arp protocol"
I had no idea of what was being asked and was racking my brain for something I didn't think I had ever used to down every computer in the library of my high school 12 years before.
Imagine you just read a 4 byte value off the network, and it's part of a protocol that specifies how many more bytes there are to read. You might (in error, ahem... :-) pass that value to malloc(). So knowing what might happen if an attacker puts an unexpected value in there is something you need to think about.
If you don't know or can't guess because you don't know how malloc() works, then you're not the person I'm looking for.
I'm kind of at a loss about why it can return either of those two things, somebody want to take a shot at explaining it?
>
> I'm kind of at a loss about why it can return either of those two things, somebody want to take a shot at explaining it?
Any return from malloc, whether it succeeds or not, is a valid argument to `free()`. Hence, it can return NULL because `free(NULL)` is legal, and anything other than NULL has to be a unique pointer, because if it returns a duplicate then calling `free()` no the duplicate will crash.
Answers to this question taught me about the candidates taste and understanding of good API design :-).
Both NULL and "unique pointer" are correct answers, but all modern implementations only chose to return one of these. My follow-up question is "why ?" :-).
FYI. I introduced a (bad) security bug into Samba a long time ago by expecting the wrong return (i.e. the one the implementations never return :-).
Attitudes will change in the next decade when vulnerabilities in software and tech become more obvious, serious, and regulated. Right now we're all happy hogs feeding from the trough of few meaningful standards, but the time will come when we are blamed for human lives lost as a result of bad code, and it's no longer going to be funny that we get paid so much to write such shit. As well, doing whatever companies pay us to do will become more shameful. From much of what I read here on HN and what I've seen in my own experience, way too many software developers will do practically anything for money and prestige.
This is why the selfishness of only wanting to work with teams that write decent code is actually more beneficial for society than "fail fast, bruh". Already, the tech bruhs aren't revered so much as they were even a handful of years ago.
But TBH mission critical software has completely different set of checkboxes that are not so easy to fulfill.
Secondly, why should a C application developer know enough about the implementation details of malloc() to answer such an esoteric question? Malloc can not, by definition, be implemented in C, so it seems a bit out of scope.
However, IIRC the only malloc error is ENOMEM. It's unclear why malloc(0) would run into that. (If malloc(0) did run into an ENOMEM, then NULL would be required, but the result of malloc(0) need not tell you anything about subsequent calls to *alloc functions. However, there is a possible malloc guarantee to consider.)
There's some interaction with realloc() which may favor NULL or a non-null pointer to 0 bytes, but that's too much work to figure out now.
Suppose that malloc(0) returns a not-NULL value. Is malloc(0) == malloc(0) guaranteed to be false? (I think that it is, which is how ENOMEM can happen.)
So, the "right" answer is probably malloc(0) returns a unique pointer because then the error check is simpler - a NULL return value is always a true error, you don't have to look at size.
malloc() is a very old API. A more modern version would probably looks like:
err_code malloc(size_t size, void **returned_ptr);
The current malloc() overloads the return to say NULL == no memory available/internal malloc fail for some reason and as far as the standard goes, allowing NULL return if size==0.
So if you get NULL back from malloc, did it really mean no memory/malloc fail, or zero size passed in ?
glibc and all implementations distinguish the two by allocating a internal malloc heap header, but with internal size bookkeeping size of zero, returning a pointer to the byte after the internal malloc heap header.
The only valid things you can do with the returned pointer is test it for != NULL, or pass it to realloc() or free(). You can never dereference it.
Returning a valid pointer to NO DATA is what all modern implementations do when a size==0 is requested.
In an interview situation, discussions around all these points are very productive, telling me how the candidate thinks about API design and how to fix a bad old one, whether they know anything about malloc internals (which is essential as overwriting internal malloc header info is a common security attack), and how they deal with errors returned from code.
Remember, it was only my warmup question :-). Things get really interesting after that :-) :-).
While it would be good if malloc(0) always returned a pointer, you can't rely on malloc(0) returning NULL just for errors. There's not even a guarantee that malloc(0) does the same thing every time.
Note that "returning a pointer to the byte after the internal malloc header" means that malloc(0) == malloc(0), breaking the unique pointer guarantee unless malloc(0) actually causes an allocation.
However, allocating in malloc(0) means that while(1) malloc(0); can cause a segfault, which would be a surprising thing.
malloc(0) != malloc(0) because the internal malloc header is different for each allocation.
Asking for a malloc of size n, means internally the malloc library allocates n + h, where h is the internal malloc header size. So there is always an allocation being done for at least a size of h, just with an internal bookkeeping "size" field set to zero.
and yes, while(1) malloc(0); will eventually run out of memory, counter-intuitively :-).
uint8_t my_memory[4*1024*1024*1024];
Of course in reality there's probably a few "non-standard"[2] system calls in the path, mostly mmap.
[1] Not necessarily, you can place them at special places in your my_memory array by convention, e.g. at the start of the array.
[2] I assume that we're excluding standards on other layers like POSIX, otherwise it's trivial.
http://jemalloc.net/jemalloc.3.html
"Traditionally, allocators have used sbrk(2) to obtain memory, which is suboptimal for several reasons, including race conditions, increased fragmentation, and artificial limitations on maximum usable memory. If sbrk(2) is supported by the operating system, this allocator uses both mmap(2) and sbrk(2), in that order of preference; otherwise only mmap(2) is used."
Also, Google's tcmalloc uses mmap to get system memory:
https://github.com/google/tcmalloc/blob/master/docs/design.m...
"An allocation for k pages is satisfied by looking in the kth free list. If that free list is empty, we look in the next free list, and so forth. Eventually, we look in the last free list if necessary. If that fails, we fetch memory from the system mmap."
In fact I'd be surprised to see a modern malloc implementation that doesn't use mmap under the hood.
In the end this is still a language lawyer question. It's a technicality that should never be relevant. If it is you've already gone wrong several times. In other languages there might be an argument that it probably does something reasonable and any developer experienced with that language should be able to make an educated guess about what that would be even if they don't know. But you asked about C, a language infamous for having undefined behaviour in many such situations, so I don't think even that is a particularly compelling argument here.
Sure. So do many other protocols and file formats. But if you're using those values for memory allocation without checking them first then getting a 0 might be the least of your worries. Unchecked large values might be a DoS attack waiting to happen.
If you work with C code where security is a factor then surely you already know this so it still seems odd to put so much emphasis on your original question. You do you I guess. :-)
Source: worked at Google.
Yea. It would be that way.
I still haven't found a company larger than a few employees with a codebase that didn't make me want to leave.
I think that's leaning to interrogation, and less of interviewing.
Are they intentionally trying to scare devs away?! (Some of the code bases that I've seen have been pretty bad)
In terms of natural languages, if you can read and mostly understand a text in another language, let's say you score 8/10. At the same time it is completely reasonable to expect that you would not be able to write the same text, and if you had to, it would be at 5/10. Then if you had to do it in a speech, you would score a measly 3/10.
I'm not saying that focusing on reading and analyzing code is a bad idea, just be careful, and expect these differences in skill levels. Definitely a hundred times better than leetcode though.
Most job seekers are working for free when applying for jobs anyway and it seems like this would have the nice benefit of providing a free rotating labor force for the hiring companies. It might even allow them to do without a couple of paid positions long-term.
Imagine how interesting a job offer would be if they can prove you will get to do things you know well.
Then we talked about the things they did and why that was better.
Probably the best "coding exercise" I've ever done in terms of getting to understand how someone approaches a typical code base.
But sometimes candidates were very unsure about how to approach it, they found it hard to proceed without knowing exactly what "better" was.
I stopped using this, as I realised that my approach was unconsciously selecting for a certain type of person, one who resembled myself and it excluded people who could be amazing devs within clear parameters.
TL;DR interviewing is hard to get right, this reading idea is a good one.
a) outdated, because almost all work relevant to my subfield have been at my job for a some years now (and my experience has grown accordingly, since), or,
b) irrelevant, because by now my personal projects are mostly orthogonal to my job (e.g. stuff involving electrical engineering and digital signal processing), which I am absolutely not applying for.
Then we gave an exercise* to write some code. In my opinion a junior (but not noob) programmer should be able to do it: the code should loop through a file that is too large to keep in memory and collect some statistics -- e.g. look up numbers associated with keywords and compute the average (where the keyword list is the large file; the lookup table is like ten entries).
This candidate (like the last one) instead worked around the memory constraint and just split up the file using external software such that they could fit the whole thing in memory. Not combining the partial results later or anything, no, just compute answers based on this one slice. Then in the interview afterwards, they could not describe how this could have been done differently, also not with hints (I understand they're under pressure during the interview). The code also had other problems (e.g. opening and re-reading this lookup file inline in the main loop... which runs a billion times). Even though functional (if not always giving the correct result; mistakes happen), they had neither a concept of memory complexity nor computational complexity.
So that's just anecdotal, maybe it was an outlier. From my perspective, talking about projects and code isn't always the same as them being able to work on the problems you're hiring them for.
* Note this was not entirely my choice, even though with hindsight it was a good idea we should at least have compensated their time regardless of the outcome imo.
Here’s a real-life example. I asked a recent applicant (for a fullstack software job, where we were hoping to hire a novice-to-mid-level engineer):
Me: How would you improve a situation where a page is loading slowly and you suspect the problem is related to the database?
Applicant: Well, I’d start by checking the HTML, is it correctly done, and then the CSS, is there any redundancy? And then the Javascript, is it correctly written, is it minified? Can we speed that up at all? Check the timeline, the API calls, see what is slow.
Me: Okay, great, that’s a good start, but what else? If the problem is not on the frontend, then what?
Applicant: Uh, well, then, I guess I need to look at the backend database model code. Is my database model code concise? Am I fetching the data needed, without any excess?
Me: Okay, great, that’s a good start, but what else?
Applicant: Uh, what else? Well, uh, we really need to look at that database code. Is the model bloated? Can we slim it down?
Me: Yes, okay, you basically said that already, anything else?
Applicant: Uh, well … uh, you need to check the HTML and the CSS and the Javascript and then, uh … API calls … uh ... the model code, make sure that is cleaned up. That needs to be lean.
Me: Yes, okay, but you said all of that already, anything else?
Applicant: Uh … well … the model code … and uh …
Me: Have you ever worked directly with a database?
Applicant: Uh … not much?
Me: If you get unexpected results from your model code, do you know how to debug the query?
Applicant: Uh … I guess I could … not really.
Me: Have you ever looked at the “slow query” log?
Applicant: Uh … no?
Me: Do you know how to run EXPLAIN or ANALYSIS?
Applicant: Well … uh …. no.
Me: Have you ever written SQL by hand?
Applicant: Uh … no.
Me: Are you aware of any differences in dialect between the SQL of MySQL and the SQL of PostGres?
Applicant: Uh … no.
Basically, they were somewhere between a novice level and a mid-level engineer, so they knew the frontend reasonably well, but they didn’t know a thing about databases. Which was okay, because that was what we were looking for. We still hired them and they turned out to be great in some areas, and they were eager to learn about the things they didn't already know. But obviously, if I'd been hiring a senior-level engineer, and it turned out they knew nothing about databases, that would have been a problem. The crucial thing is that I kept asking the question, over and over again, until I had the full answer. In this case it was easy, but sometimes it can feel aggressive, asking the same question over and over, which can leave either you or them feeling uncomfortable. But you will never be any good at interviewing people until you learn how to tolerate uncomfortable moments. The goal is to find out if you want to hire someone, without wasting their time or yours. And asking questions like this, directly, and digging deep, is a much faster method than handing out homework assignments and then waiting a few days for them to complete it, then reviewing it yourself, then discussing it with them. And such direct, factual questions, as above, are at least as objective and as any “objective” test that you might invent.
I don't need "we need to loop here from 1 to 50", I need "we have to rate-limit this function to under 60 transactions per second due to hardware requirements", etc.
If you are putting "magic numbers" anywhere, COMMENT it as to what that number is, why you chose it, etc.
I'm 30 years into this game and I still come across code that takes way too long to reason about.
Doing it because you choose to. Because you like it. That's key.
Non-psychic candidates will struggle with this challenge, so you might find it produces some false negatives.
Since you already seem to know so much about debugging slow performing database queries on your particular RDBMS stack, though... what was your thinking in looking to bring on board someone else who duplicates that exact knowledge?
Oh, and it'll be a missing index. It's always a missing index.
"Are you aware of any differences in dialect between the SQL of MySQL and the SQL of PostGres?"
It's not like they lost points for the stuff they didn't know, I simply wanted to be sure I understood the limits of their knowledge. We hired this candidate and they turned out to be great. But I hired them knowing exactly how much they knew and how much they did know.
There's nothing aggressive about this approach unless you make it that way and finding out if people will start bullshitting or admitting the limits of their knowledge is a massive advantage to someone you might need to depend on.
"finding out if people will start bullshitting or admitting the limits of their knowledge is a massive advantage to someone you might need to depend on"
One of the best hires I ever made was a former K-12 teacher who had decided to change careers and become a software developer. She went to a bootcamp and then I hired just as she graduated from that bootcamp. When I interviewed her, I very much appreciated how clear she was about what she knew and what she did not know. She felt no need to bluff. And that foreshadowed what our communication was like once I hired her: very straightforward, with no lies or bluffing or indirections or deflections.
A trend I've noticed the past couple years is that people make the excuse of "code should be self-documenting" so they don't need to add comments. But then very helpful contextual hints that are not otherwise documented anywhere, like the one you provided, are completely non-existent and the original dev has left the team, it's been 2-3 or more years since the last time someone touched it, etc.
Code should be self-documenting, don't get me wrong. But that's more in the vein of showing (what), not telling (why/how). There still needs some be some method of telling.
some form of git history to go along with it
some single page architecture type of doc. No technical info, just like a README saying what this thing does and some 101, maybe a diagram.
The "doc as part of the code" for me is really just a easy way to generate a "reference" for function signatures and specific code interfacing. And if you start off that way the reference is at least always up to date, because it's caught in review (ideally).
As for updating the README that's just on the dev team to remember.
I will say my opinion changes a bit with huge polyglot mono repositories. In those cases you need great docs and organization.
Better yet, turn magic numbers into constant variables whose name becomes the comment. Of course, comments can also provide additional context :)
const ONE_HOUR_IN_MS = 3600000
const RESEND_DELAY = 3600000Also, good commenting skills take years to master.
As a newer developer, it’s nice to hear you say that. I often find that I spend more time deliberating over comment wording and variable names than I spend writing the code itself!
I've lost count of the number of times I've seen comments that were just wrong -- they applied to the code as it was written years ago, not today.
Write good code, and it should be obvious how it works. Use comments sparingly and only when things are not obvious. Update the comments when you change the code, and make sure your code review process doesn't let outdated comments slip by.
If you can't commit to the above policies, then don't comment your code at all.
This should be easy enough to verify during code review, no?
No need to interweave documentation and code, in most cases. Sometimes, when we fail to write good code, sure. But let's try to write good code!
Locality is the reason, and it's a good reason. Of course, I don't want to see paragraphs of explanation inline, but a one-line comment giving context for some choice that might be confusing is much better and faster to work with than a separate WHY doc.
What actually would happen is the next person comes along and changes the code and doesn’t update the external doc because it’s probably buried among 100 other pages on confluence and they don’t even know it exists
If the comment is in the code they will see it and update accordingly
* If they don't know how to debug SQL, I'd like to know that.
* Do they simply say they don't know, or do they try to bluff? Are they confident about what they don't know? Like I said in a different comment in this thread, one of my greatest hires ever was a former teacher who was very confident about what she didn't know -- she never felt any need to bluff.
Given two people of exactly equal skill, if one bluffs and the other is confident enough to say "I don't know", then I'll hire the one who says "I don't know." Because then when we are actually working together, I know they will be honest with me whenever they need help, they won't be trying to keep secrets from me.
Also, about this:
"triggering the candidate’s imposter syndrome"
Given two people of exactly equal skill, if one has imposter syndrome and another doesn't, I'll take the one who doesn't have the imposter syndrome. Or put differently, given two people of exactly equal technical skill, if one demonstrates a higher emotional intelligence, I'll hire that person.
as a more concrete example, as I get older I'm less interested in working on the computer off hours. I've noticed I don't even play video games as much as I used to. I actually started doing wood working a couple of years ago, and playing with 3d printers. It does go in fits and starts though - sometimes I get an itch to play with something just for fun...
That said, I do find this hard in interviews (when asked about past experience) and prefer to just be given a web application riddled with every type of bug and try to bingo them all in the time given to show that I understand them all. That one was my favorite interview. But that might just be a different style of interview for a different type of job.
The external doc is an explanation of what the value does, and what happens when that value is updated, not why it's set to a specific value.
I’ve put this into practice numerous times with positive effect, so my more relevant experience tells me this is a winning strategy, compared to in line docs, which are objectively worse in nearly every way.
It's not faster because you can just name the variable whatever it is the value represents, so by adding a second descriptor (the comment) you're introducing needless complexity.
It's not better because you really shouldn't be changing a value you don't understand the context around, which means reading much more than a one-line comment.
https://github.com/golang/go/blob/master/src/cmd/cgo/ast.go#...
belong in the source code, not a Why doc. No variable naming can give that context.
const RESEND_DELAY_MS = ONE_HOUR_IN_MS;
const RESEND_DELAY_MS = 1 * 60 * 60 * 1000; // one hour
const ONE_HOUR_IN_MS = 3600000
const RESEND_DELAY = ONE_HOUR_IN_MSconst RESEND_DELAY_MS = 3600000; // because TTL in Agora
const RESEND_DELAY_MS = 3600*1000; // because TTL in Agora
Easier to check for the right number of zeros
const ONE_HOUR = 3600000;
const RESEND_DELAY_MS = 2.5 * ONE_HOUR; // because TTL in Agora
IMO it makes it easier for successor to fiddle with.
But your more relevant experience tells you that’s wrong. I really don’t understand such aversion to a one or two line comment, but let’s just not work together in the future. ;)
You’ll be fairly lonely if you reject working with everyone who’s read Clean Code, and truly alone if you won’t work with anyone who understands something better than you.
And I think people who read Clean Code and aren’t dogmatic and condescending about trivial choices like this are pretty fine.
And I'm not dictating anything, or being dogmatic and condescending, but I guess it's easier to think I am if you're trying to have an Internet Argument Moment.
You literally dictated that explanatory code docs shouldn’t talk about rationale for constants. And your evidence for this is that apparently Clean Code says so.
> condescending
Well you can claim not to be condescending all you want but that’s how I interpreted your explanation that the only reason I disagree is that you “understand it better,” and I’d imagine that’s how most people would read it.
Far to often I’ve interviewed at places and been grilled by the interviewer only to find out when you start the quality isn’t great, what you where grilled on you won’t be working on “as that’s to hard” or “we don’t do that” despite being grilled on it and the level of skill not to great they just want senior people. It’s the bait and switch.
At least being taken through existing code you know what you are getting yourself in to. Also looking at the current open pull requests and closed pull requests to see the standard and speed of delivery. Bonus points for no PR’s and trunk driven development as that shows a very mature team.
My simpler interviews have often been with companies that have held a higher bar than the ones with tougher interviews. Those companies have often been sink or swim though and if you don’t make the grade you’ll be kicked out pretty quick. My last company had a reputation for new starts disappearing and not great that way, but the team was probably the strongest bunch of people I’ve ever worked with as only do good survived.
Ugh, pass. Trunk development is fine. Skipping PRs just brings back nightmares of SVN. Even if 90% of PRs are approved without comment, it's extremely helpful for everyone to have a second set of eyes on work before it is merged in.
It's also a way to give insight when onboarding new developers: if something is surprising, they can see why things came to be this way, not just accept the result at face value.
If you pair, there’s two sets of eyes, to commit both pairs have to sign a commit. You can also organise a demo/quick mob session before commit. Then there’s a level of trust in your teammates.
PR’s are great for open source projects as act as gatekeeper so not everyone can commit freely. If you need to gate keep your team members then I’d question the strength of your team.
The best teams I worked on who delivered working code fast, efficiently even when they are some of the most complex projects I worked on committed straight to trunk, had a very good build pipeline (super import) and worked closely together for review. The standards where extremely high yet the general feeling was it was less dogmatic, micromanaged or kept behind a gatekeeper.
The projects I’ve worked on with dogmatic pr’s generally failed to deliver anything in any amount of reasonable time. The prs where dogmatic as more junior teams get caught up in superficial things such as names, package structure, syntax preferences rather than what the pr actually does.
Creating a separate branch, pushing this to your public copy of the repository and then asking someone to pull from that branch into their master branch seems absurd to me, especially if it's just 1-2 commits, and the idea of reviewing code (which I think is extremely important at team scale) should not be conflated with the concept of pull requests.
Maybe the kernel of a good idea in the comment: A team that prioritizes reviews, such that PR's are not a significant hurdle, is indeed a sign of a mature team.
Sounds perfectly sensible, and not naive at all.
I'd much rather come into a situation where they were both already aware of, and entirely honest about the current shit-show status of the project -- than a situation where everyone thinks what they're doing is great and bleeding edge but when you actually take a good look at their assets, as it were... not only are they manifestly and visibly unwashed -- but no one seems to notice the stink.
Good candidate would instantly notice the team is being labeled as seniors but instead are a bunch of crappy devs with years of experience.
Code does not lie. If you are crap you gonna produce crap code.
Ive recently hit such a mine. Lies during interview. Gonna sit here through vacations and jump the ship. Was sold on working with experienced ppl with over 10y of experience. Turns out those ppl IMHO have less skill than me few years ago with only 2y experience. Legacy bugers that did not improve over the years.
That being said, pull requests / code reviews / merge commits are totally compatible with that. Gerrit, for example, does every commit as a mini-pull-request on top of a branchless HEAD, and when the review finishes, you merge to main/trunk and off to CD it goes.
If you're on a team that isn't currently having staffing issues, I don't think it's weird to want your next hire to be better than the median person on the team. "Raise the bar," etc. Asking harder leetcode questions seems like a bad way to achieve it, but I get the impulse. If the bar for member nine of the team is approximately "better than the bottom 4" then that 9th person in is likely to have at least one moment of "wait, how did you pass that interview?" at some point after they come on.
Riddles I've encountered while working as an engineer: 0
Happens to me too, I get tough interviews, and a good salary, but the work is exactly the same as the juniors "a guy on the scrum team". I don't even understand why they hire seniors, or have that title when it means nothing. I guess they expect them to be just faster versions of juniors.
No, they expect them to be:
- more independent
- able to bring past experience to bear on present problems
- make fewer mistakes
- be able to help others rise to the next level
- possibly make good team leads at a later stage
This is not what I would call a "strong" team. This is what I would call a developmentally stunted team. By that I mean they've reached competency as individuals, but they have limited ability to level up fellow developers. As such, they are not a producer of talent and rely on actual strong teams for their hiring pool. In my experience, these teams are best avoided if you actually care about growth.
I hope they weren't some gatekeepers you ran into... "don't use emacs and fish and the dvorak keyboard? you don't fit in here."
I'm not sure what Trunk Driven Development is, could you elaborate?
Btw trunk based in general can still have short lived branches and prs. That’s what most public projects on github are doing
Pretty striking difference.
Trunk driven does not mean mature team 100% of the time, but if you have a mature team trunk-driven is more efficient than PRs.
It only works if either everyone is senior, or it’s a project of 1-2 devs, or if people are pairing most of the time.
So far I've had really positive feedback from job candidates. A couple even described it as their favorite interview ever! I feel like it has worked well, given the people we have ended up hiring.
An example would have been nice though, as I'm not sure how to find a piece of code that does something standalone that is too large to grasp in 20 minutes yet make a reasonable prediction at the output. That combination seems kind of weird.
I wonder how well it would work to modify OP's idea and present a candidate with some code that has a bug in it (you reveal what the bug is to save time, they'll need to understand the code anyhow) and you ask them how they'd fix it. First broadly, like what approach, then actually write part of it.
To take my own advice and make the discussion more concrete, I should add an example. Random script from my github: https://github.com/lucb1e/randomdirectory/blob/master/random...
To prepare for the interview, one could add an argument like -h to show usage (in the same style as -v is currently implemented), then tell the candidate that the bug is that passing -vh executes neither -v nor -h (one would commonly expect it to execute both). Fixing this requires a 'structural' change to this little bit of code, but it's small enough to easily grasp and implement. The candidate might propose to loop over each character after a single hyphen to fix this, or they might propose to throw out this custom reinventing-the-wheel and use a proper arg parsing library. Either is fine, but they should be prepared to write the code (in any language, they can write just the changes in C, Python, JS, or whatever language they're comfortable with).
Has anyone tried such an interview coding question?
Have this subordinate and the candidate participate in a staring contest. This will show a couple of things about the candidate: A) How well they maintain eye contact (very important for communication) and B) How long it takes them to back down from a challenge; this taps into their primal instincts.
I would also sound a fire alarm, to see how they react to working under stress, and measure how much their pupils dilate.
But if someone does have it, it does get looked at, at least through me.
My interview is always the same:
1. Bring code you've written 2. Share your screen 3. Explain what it does and I will casually ask questions about it
You get so much information from this:
- How they think about code - If they think it could be better - Who they blame if the code isn't the best - Personality - Product dev glimpses - Comms - Sentiment
But I am also the type of developer that would do well at this (experienced and older). Young folks, right out of school, or with just a couple of years of experience, would not do as well.
I’m pretty convinced that one of the goals of LeetCode tests is as a “young-pass filter.” It controls for people close to college age, where those types of problems are common, as well as people that are willing to work very hard, learning exercises that appear pointless.
Not sure that many companies, these days, are actually interested in older, more experienced, developers.
Yeah I've also been using this approach for Fullstack Devd: A small page with a bit of CRUD + a small ticket description of what the page is supposed to do.
The code contains various bugs or questionable implementations, the interviewee is supposed to analyze the code and to either fix the issues right away or to write comments.
Nobody is expected to get everything right within the time slot, but I've found it to be a great test on how a candidate might perform in their day to day work.
This is true. Most of the time I'm only reading my own code, and over the years I've been motivated to code better by having to go through crap I wrote early on.
Nothing cured my imposter syndrome (self taught, no degree) like walking into a startup and seeing PhDs fail to follow just about everything I'd ever learned was best practice and was doing without thinking in my own projects.
My experience with many companies is they treat people as a 'resource' that needs to be managed rather than a human BEAN. Companies, in the process of funneling around these resources, forget that there is an individual cost to these resources. And if your first introduction to a company is being dehumanized and treated like your time doesn't matter: what are the chances that this company is a good place to work at? And that mans name. Albert Einstein.
If this were a heuristic of a good developer, it would let me (not a dev) in and who knows what the effects of that could be :).
If you wanted a job coding, and you can currently read code, i think you could do a passable job if you were working at it for 8 hours a day.
In this way, the interviewer is expanding their talent pool.
I'd rather hire-- as a coder-- someone that could read code but would fail an interview where they coded, than someone who could pass some trivial coding interview but couldn't read code.
Obviously, people need to do both, but the reading seems less likely to get a false positive/negative in an interview.
Heck, given two candidates one who cannot currently code but reads code fluently vs one who can code (and not just pass a coding interview) but cannot read code-- I'd still prefer the reader. It's the more important skill.
Average industrial programmer is going to write 8 lines of code per day. If you can correctly read a codebase, you can probably manage to write 8 working lines of code per day for it on average. Maybe you wouldn't be #1 one the team overnight, but a fluent reader is at least on track to be average even if they hardly write at all now.
This approach has given me excellent candidates every single time and also led to a lot of time saved otherwise wasted.
If I interview someone it's because I like their past experience and think they are a good fit and/or have growth potential. I just need to know if they're lying and if they fit the team personality wise.
What knowledge do I have to gain in having them do medium & hards besides that they can solve medium & hard exercises, which aren't really applicable day to day?
This is equivalent to fizzbuzz without fizzbuzz. But that's just my opinion and I do not work at a FAANG...
If you introduce subtle issues in your code, you're most likely just testing their familiarity with a framework or language nuance.
Big issues could work.
Perhaps just providing a take home codebase that's 80% of the way there, and asking them to take it to where they think the remaining 20% should be is a good middle ground.
Firstly, you can work with realistic code. It can use your real tech stack and there can be enough code with a realistic structure to see how a candidate finds their way around.
Secondly, you can make it open-ended. For junior candidates it might be best to stick to simple questions like what does this short function print and see if they can reason through some basic logic. But for more experienced candidates it can be a general code review.
Your example code can include anything from superficial mistakes like typos and unnecessary duplication to strategic problems like inflexible designs or inconsistent models. You can include obvious or subtle logic errors and performance problems appropriate to the level of the role.
Ask each candidate to talk you through what they're thinking about as they read the code and see what level they work on and how much they find in the time available. Are they methodical? Do they flag the trivial stuff but not get hung up on it? Do they spot the O(n^2) algorithm? Do they spot that algorithm but then start talking about worst case vs amortized performance and using a profiler to decide whether changing to a theoretically better but much more complicated algorithm would be justified?
In this kind of environment you can quickly tell if you have an awful or outstanding candidate. For the majority who fall in between you have an objective basis for comparing their performance. And all without any trick questions or LeetCode junk at all.
Sometimes when I'm trying to plan something which requires a lot of thinking I take a piece of paper, write bits of code, draw schematics of the flow, schematics of data structures. If I am planning the architecture of an application which isn't trivial, I like to go to the whiteboard and draw. Even if I have it in my mind, visualizing it helps me find improvements.
The problem is that the 'existing code' may well be of poor quality and that in order to understand it you first have to get into what it was supposed to be doing in the first place, and this isn't always obvious. So the writer had better take good care to make the code self explanatory or provide additional documentation to give sufficient context. In a way the underlying assumption is that the code is 'good'.
And that's where the real problem lies: lots of code isn't all that good and plenty of it is probably best described as 'single use', in other words: write only. Trying to read it or trying to make sense of it is more effort than writing it ever was. And given the fact that code is typically read many more times than that it is written it pays off to write it well, but hardly anybody really does. The pressure to deliver the next commercial feature is just too high.
And woe to the interviewee that points out the deficiencies in the code if the author of the code happens to be the interviewer, because people will be people, so this could easily turn into a minefield.
Questions to ask of the interviewer before 'reading' the code:
- who wrote it?
- is it functional?
- are you supposed to debug it or explain it?
- was it written for the express purpose of the interview or is it code from the company codebase that is representative of how they work there? (this alone might be reason to terminate the interview depending on how it looks :) ).
Intuitively I'd expect that not to make much difference since most mainstream languages are pretty similar, and the interview wasn't syntax oriented. But that's not what I experienced. Signal to noise ratio was there and definitely affected speed of processing the code.
(To answer my own question, for coding interview style algorithmic questions, it should be easy for the company to translate the questions to the applicant's preferred language before the interview. (if not then it's probably not a good interview question). Hopefully this company does that.)
Obviously if the company explicitly wants the candidate to be familiar with deep aspects of whatever language you use, then this doesn't matter. I can imagine hypothetical cases where this would hold, but I'd think it relatively rare.
Most of my code-based interviews have been this way, and when I've been the one interviewing, I say: "Use whatever language/tech you like."
But for first step a Psychotechnical test on the candidate, and to be fair, the team and manager.
They couldn't work out how I got hold of it. It wasn't open source and only distributed as a binary.
It got me the job. Risky strategy.
It was even more impressive because the person doing the interview wasn't super competent and yet they still managed to do a fairly comprehensive technical evaluation in ~2 hours.
One section was a debugging session where you had to get tests to pass. The code and tests were quite decent, which made it quite easy to show off. Every company should do this.
Too bad the Triplebyte promise (not having to do phone screens) was a joke and their business model wasn't good, but that part of Triplebyte had major promise.
I'm kinda jealous, I'd love to do code interviews again, but I haven't been a junior dev in ... /* checks notes / ... over three decades?!? cries in yaml*
List as many different ways as you can for how to figure out if a singly list is broken and has a loop
The project was:
- you have two files: listings.json and products.json
- listings.json lists ~20,000 Amazon listings for electronics with fields like title, brand and price
- products.json lists ~1,000 digital cameras, with fields like brand, family, model
- your job is to write a script that, for each entry in listings.json, emits the best match (or no match!) from products.json
Your solution could be as naive or as fancy as you wanted. The main point was to have something for the next stage.
We'd run your submission, and use that to show you some false positives and false negatives. Then we'd ask you to debug why each false positive or false negative happen, explain it to us, propose how you'd fix it, and identify any trade-offs in your proposed fix.
Eventually, we wanted to offer a non-take-home-project interview. We already had a bunch of existing solutions from employees, so we used those to run a stripped down version of the interview that just focused on the code reading/debugging/proposing fixes part.
I think both of these interview approaches were pretty effective at giving candidates a natural environment to demonstrate skills that they'd actually use on the job -- debugging, collaboration, predicting downstream implications of changes, etc.
That's amazing! I didn't know that our little project is used in interviews. Happy to hear that you liked working with the code base!
We were brainstorming what type of content would make fun and educational workshops for students. I proposed something along OPs lines. I called them "debugging minichallenges". The idea is to present students with a buggy implementation for a simple problem, and they need to find and fix the bugs. Just as OPs argues, the concept is that reading and understanding code is a fundamental skill.
I have the set of sample implementations in my Github, for example the one in Python [1]. This is our first time running this workshop so I can report how well it did after the event.
[1] https://github.com/angarg12/minichallenge-flood-fill-python
[1] https://github.com/angarg12/minichallenge-flood-fill-python/...
In my opinion, you should be free to look that up: that's what you'd do on the job as well. I also google it every time I need to use arg parsing in literally any language because I need it fairly infrequently, and frankly that's how this code came to be: too lazy to look it up again, too easy to write myself, and enjoying the writing of code. Any other solution would also be fine, this test would be about seeing if you can read and write code rather than if you come up with the (what the interviewers think) is the perfect solution.
> gives a chance for the candidate to ... put forward their best self.
How does that work? If it genuinely won't be evaluated, what's the point of getting their best self? How do you make sure things you learn in this don't affect your judgement later?
I like leading with that, and am a big fan of the initial "what's an interesting problem you had to solve?" question, but I made the unfortunate experience that even people with good war stories are sometimes very shaky in the basics of the particular subfield I'm interviewing for. To the point of deeming someone not a good match for our team, but encouraging them and internal recruiters to interview with other teams.
There is ultimately no full substitute for getting down to brass tacks and actually do some "sample work" together. Whiteboard coding is the usual (and, I guess, often poorly implemented) approach, but I've used reading existing code, with added intentional mistakes, to great success so far.
EDIT: Just read your new reply in a sibling thread that you're doing that anyway, and project and war stories are supplemental. It seems like we're in agreement, then!
As for avoiding unconscious bias, was that ever an option?
> [...] That said, I do find [it] hard in interviews [to talk] about past experience[s] and prefer to just be given a web application riddled with every type of bug and try to bingo them all in the time given to show that I understand them all. That one was my favorite interview.
Now I see johnqian suggesting to ask interviewees how to best see their skills, and it sounds great. If the interviewer doesn't have something like this on hand, we could still go into different types of bugs that they care about.
I've also had interviews that went terribly, particularly when no technical details were asked at all for a technical position (e.g. a manager just asking the standard questions where you need to give platitude answers, such as "why are you specifically excited to intern with Vodafone", methinks: "because I want that degree and you were the only option I could think of within 45 minutes commuting"... but one can't say that so I made something up.. he probed further on that... it went downhill from there), so being able to steer away from that sounds great.
But it might also be that I would feel unprepared for such a question and give a total non-answer, helping neither party.
Asking this in an email ahead of time might be better, though then the effect you're suggesting might be even stronger.
Edit: I'm not the downvoter, to be clear. I think you raise a good point even if I am not sure whether it would necessarily be that way.
I have a family and as such no free time for coding so I haven’t written any code I can legally show anyone else in more than a decade. But everyone who has employed me is more than happy with my work. Not to mention code is only half of why you would want to employ any developer.
Instead, I'm asked for senior-managers/directors as references... who were the reason why I left in the first place. I guess HR just wants to know I was actually employed there (tick box)
Not OP, but I follow a similar process when I have to do coding interviews. I work around the "no public code" problem easily: "great, then pick an open source library you use regularly and let's go through and look at some of the things you do with it, what you like about the API design, and some things you stumble over or wish were better".
I've had candidates go through everything from jQuery to D3 to Spring to just parts of the Java SDK.
Also, in my experience, the percentage of people who have _zero_ public code is small. Maybe 10%. Certainly not half.
It then becomes a take home assignment where you get to pick the topic.
Surely you wanted to protoype some tech but didn't have the opportunity at dayjob - so make that prototype and bring it to review.
Much higher interview value than take home assignment IMO, but you need to be competent as an interviewer to enter into a discussion on something you might not understand yourself.
And it's also higher value to the person applying because they get to protoype stuff they find interesting.
At the end of the day all your after is signal on how well they understand software. There are lots of ways of doing that
My good code are paid for and thus is owned by someone who is not me and can't be shared with a third party. The code that own is inherently bad as I want to create things as fast as possible without being bogged down by proper code writing etiquette.
IMHO It's still better than leet-coding questions because most developers don't need to use the skills gained from practicing leetcode when at work, whereas open source contributions and projects are valuable. Also, someone with no time outside work and family would struggle with both leetcode and having side projects.
You could clone an open source repo and use that if you're worried. The value isn't the code; it's the conversation.
"Bring your own code" is just meant to put the interviewee at ease because they are already prepared to talk about their own code.
By comparison, my github or personal code would be just a bunch of perl, rexx, sh/bash and python scripts written just to automate some work. I doubt anybody would think those should be cleanly written, highly maintainable, modularised, etc...
I was not wrong this time either.
If you didn't have an existing code, they suggested you built something from scratch and compensated you for the time spent.
I’ve done most of my interviewing in finance where:
1. The engineers are mostly really good
2. They almost never have side projects, and everything they have ever done is super secret and proprietary.
For this it makes sense to ask people to do a take-home, and then ask them questions about it when they come in.
I usually also ask them to add a simple feature to their code and just silently watch them code it. You learn a lot from watching how someone breaks down a simple problem, especially where they are expert (ie they are working in their own codebase).
I’m beginning to appreciate the value of cohorts as I age. I work in a ver successful triad, ages 51, 58, 61. We recently tried to integrate a young-30s in our group. It did not go well. They recently moved from our team and are working elsewhere with a group of people closer to same skill, aptitudes, and age. Both they and we are much happier this way. It’s a small sample set obviously. I value a diverse world where we tolerate and learn from each other. But years of working experience have made me wonder if we shouldn’t just let age/skill cohorts naturally work together.
On first glance, we really should not have worked well together. But the group clicked because it shared a value system (be it for writing clean code, good documentation, user experience, collaboration, etc.).
And it was two introverts and one extrovert, to boot!
Part of that is the company is insisting on going hybrid after the pandemic, so they filter out full remote candidates for long term positions.
To connect to the article, we have three questions in our interview that lasts an hour and a half - in one of which the candidate is given a small program with a bug and we see how they troubleshoot it - the idea is not to fix it, it's to see how they think.
I quickly learned, that if I saw a binary tree test, I might as well give up. Even if I did OK, the company was not going to give me a chance.
What I do have, is a ginormous portfolio, with dozens of repos full of ultra-high-Quality code, for shipping products, and over a decade of checkin history, along with hundreds of pages of documentation, and dozens of blog articles and postings; often directly discussing my design methods and development practice.
It has been my experience that this was dismissed, even when I curated and sent examples, directly relevant to the job.
For example, we gave you a tetris game, you had to change the code to make a snake game. Or change an Othello game to a "number sliding puzzle" game.
It was very interesting comparing people that really made an effort to use the game code vs candidates that just deleted most of the stuff to implement their logic.
That might require one to be familiar with those ahead of time. If that's what you're hiring for, that's perfect of course, but I personally haven't had much experience with design patterns outside of a few C# ones in school five years ago. Yet I see myself as a competent amateur programmer (and C# isn't even my strong suit), just not one that often works on large code bases. These patterns seem like something I'd learn in a matter of days on the job... but that would not show in an interview.
These are good skills to have when a dev is debugging as they could get tied up for a long time dealing with something as simple as a relative path issue.
I've been in that sort of position tbh, where a 200 line codebase has maybe 20-30 obviously wrong parts (creds in code, calls to 3rd party service in code w/o cacheing, maybe that could just be a service? why is this not in a queue, ...) and it's sort of weird that getting 11/14 and talking over pros and cons of the others can be considered a barely-pass.
Still, you're not wrong. Find a good enough, real-life enough example and it'd make for a great question.
What you won't be testing is higher level skills. It may be easy to hack into a known codebase, and even do it cleanly, you just have to mimic the surrounding code. Getting the big idea and making long term choices is another set of skills, not exclusive with being a cracker, but not something you can see in 10 lines of code.
The higher level skills can be somewhat tested by asking the candidate how it would build some module and the variation that some factors would bring in (like closer deadline, no third party service,...)
I think one way to iterate on this to weed out guys like me would be to ask process based questions that reveal the candidates experience and preferences:
“Brainstorm with us on how you would you make this messyFunction more performant given $these conditions”
“We are thinking of developing a feature that would call this function more often. Would you turn this into a micro service?”
“Looking at this db call, how do you see this scaling if we increase the number of x and y?”
“Is the following PR safe or sane?”
I bet it’s much more work than that. It’s maybe 2–3h for you, who has reviewed dozens of submissions, have designed the problem, and know what the actual solution is.
For the rest of us, it takes trial and error, implementing, polishing (because of course you want to show your absolute best code when being judged solely on your code) and it’s probably actually taking 2–4x as much time as you think it does. No applicant will ever tell you that because they don’t want to look bad.
Try and have people on your team do the challenge, you’ll see how much time it actually takes.
I personally pass on these. If it’s more complex than “implement array.flatten”, it’s going to take way too long and I decline to go further. If it starts with “implement a web app that…” or “an api that…” I don’t read any further and bail.
In reality though, the time spent by the guys varies. I always ask them how much time did they spend on the question after selection. The mileage varies from 30 mins to 4 days (because they had office work/weekend trips and attempted the question only when they were absolutely free). No, the hiring HR makes it specifically clear to not try to give a polished code during the initial call and only work 2-3 hours on it.
I see where you're coming from, lengthy problem solving questions are definitely not worth anybody's free time. I've seen problems that can take 1-2 weeks to solve. But for me 2-3 (or even going by your maths of 4x3... 12) hours... is definitely worth your free time... Because 1. that's the amount time you spent while giving your 4 other interview rounds in 4 other companies paying ¼th the salary. 2. Or for a similar company paying an equivalent salary that takes 4 rounds of interviews spread across 4 different days (counting your commute time as well).
Implement array.flatten can be Googled in under a minute. That beats the purpose of a test. I'd rather take a telephonic round and be over with it. The core idea behind my shift was to ensure candidates can't cheat. (And I hate video calls because a lot of them end up having connectivity issues during the interview, especially during the difficult questions).
> I don't read any further and bail. Yes. This. You're the kind of guy I don't want my time wasted with. There are a lot of intelligent candidates who'd have definitely aced a telephonic round (or even this written test for that matter) but bail out at the sight of "implement a...". In my experience, you're the kind of a guy suffering from Dunning-Kruger syndrome. The good work is there, but the headaches that such candidates cause on the other 90% of the times makes it not worth my time.
We can argue this to the world's end but in the end what matters is the demand and supply market forces. You can call my process a waste of your time. I'm sure you'll end up getting a better job the next day. And on the other side of this coin, even I'll end up getting a better candidate than you. In my experience, all the candidates that I've hired in this format have been marvelous, so I'm gonna stick to this.... At least until I keep getting great candidates.
You pay for that wasted time, yes?
Or may be since your time is so precious, we can just skip this written-test-hogwash altogether. Let's just do the traditional telephonic round, shall we? Ohh and by the bye, so long as we are on this topic, you'd pay me for the time I had to waste on you in case you turn out to be a garbage of a candidate, fair?
...Anyone know if Oculus has been bought yet?
Like not sure how many times I need to revers a linked list IRL. Never would be my guess.
I just stop the process if I get a Leet code link. Timed and IDE in the browser.
I still remember getting a c++ question that had the answer "press ctrl + z" to stop the process. 12 years of c++ not once did the embedded device have a keyboard.
People who have plenty of time to prepare, eg carefully study and think about that API before the interview, will tend to do better in the interviews.
Although they aren't necessarily better at coding.
Meaning, you're slightly favoring people with lots of spare time. Not saying that's a good or bad thing, just maybe something to be aware about.
Also, what open source project they happen to choose, will matter I would think. That's a bit like tossing a coin as part of the process
[1] And if they do, we probably end up pulling up the man page for them because we don't remember either. It's just not the relevant part of any coding interview, the reading or the writing kind.
I do. Even though my quick and dirty scripts are not always clean either, I still profit from the times when I take some more minutes to document what a certain script does and clean out at least the rough edges.
Otherwise it means rewriting the same thing again and again, which costs more time in the end. Or it means executing something you barely understand yourself anymore, which can be dangerous.
If you say you know tech X, manager wants to hire for tech X to solve a business need, and I'm asked to help interview, I may ask you questions about things I don't know or do myself because it's my professional responsibility to my employer and manager to help them hire a quality candidate. Maybe some people use the interview as a place to be jerks or show off but that's not always true. Personally I'd rather not be involved in the process at all.
I spent most of my time writing design documents, doing code reviews, and shepherding my relatively small changes through review. Something I could've banged out in a week would take months due to all the review and processes.
There's good odds that it's the 26836th build, the 4045th snapshot, and the second time they've broken the file format. (or the 2nd expansion, or both)
heh I like it. I'm going to put you as an intermediate skill level dev.
So these things break and need to be fixed. They also have to be setup by someone. You also need to know when something breaks, can I rule out that it's not a setup issue, a git merge that's broken a path, a user that's pushed a local dev config file accidentally.
In order to be effective, you need to have a feel and justification for the way things are. Getting someone to setup a project correctly should be a quick and easy way to do this.
For example, I've had candidates submit tech tests with code in the top level directory instead of having it in a src or some other sub folder. Which is obviously a red flag.
What does "very interesting" mean here? What does this particular comparison tell you? It's genuinely unclear to me which you prefer, why, and what signal you get beyond willingness to follow an instruction in a peculiar context.
We had candidates that were 'frustrated' because of the code. Some were frustrated that the code was low-quality, others that it used Canvas for drawing and they have never used canvas. Others about the way the logic was implemented originally.
The best candidates worked with what they had, and used the "tools" at their disposal: for example, use the code that draws a circle in the canvas already, dont try to reinvent it. At the end of the 3 hours, we talked about their experience doing the project and they had good feedback.
The bad candidates just deleted most of the code and added their own logic. My thought process is that, I could imagine them on their first day of in the team: the code startups have is never "the best one". I dont want someone who wants to throw the baby with the bathwater, but someone who can improve what we have.
A detail is that the challenge lasted 3 hours. Of those 3 hours , 1.5 hours wage candidate was "pair programming" with some developers (segments of 30 min spaced to give the candidate time to work alone). And during the pair programming , the devs were instructed to help him, give them hints and ask "revealing" questions.
I agree, also sounds like an unusually well defined role with a clear way of having impact. I would also take this job any day over another job that would bait and switch me into some rewrite death march.
Bring in a spit and polish crew and build towards an evergreen codebase.
But yeah, when you think about -- a sufficiently fecal-encrusted, lost-cause codebase is almost indistinguishable from an actual greenfield opportunity.
The PR and original branch show dead-ends that should not be required reading to understand things.
That way, I can treat the series of merge commits to trunk as the simple, linear overview of history, but when I'm bug-hunting I get small, clear commits to search through with git bisect.
It also means I get more useful blame output, as instead of huge hunks of a file being all from one giant bomb commit, I can see the process and evolution that the whole change went through as the original author pieced it together. That can be really helpful when dealing with obscure bugs or understanding systems with little documentation, by helping you get back more of the original author's thought process and seeing how their mental model evolved as they built the feature.
For example:
When I want to see tests or documentation or config related to a change, I'll find the commit and look for other lines changed at the same time.
When I make automated changes to the code, like reformats, auto-corrections by a linter, or IDE refactors, I create a separate commit to separate mechanical changes from those that require more human scrutiny.
I understand not wanting to do a ton of weekend projects and having other hobbies, but it's wild to me to think that being able to do these sorts of things but never doing it happens.
It's sort of like a car mechanic who doesn't fix/tweak his own car.
Since analogies compare dissimilar things with at least one similarity, I think you lost the one similarity and undermined the point you thought you were making
What does a programmer seeing a bug have to do with this conversation? What exactly are you imagining? I’m imagining how silly it would be for me to run a custom version of a chrome extension that wont get any updates just because I didnt like how a feature was implemented, I’m guessing you are imagining something else?
> What exactly are you imagining?
Build some small tool to automate a task that you have in your daily life
Write a program based around one of your hobbies that caters to something niche so there's no good tools for it already
Anything of this sort, I guess.
I do a lot of open-source work but it's selfish -- I submit those PR's because they are things I wanted/needed and it would be silly for me to have a fork and try to keep it up to date with master.
Maybe it's different for other people but I constantly run into bugs/missing features in tools I use for both job and personal stuff. If I didn't do this there would be so much I'd have to hack around or flat-out wouldn't be able to do.
And do you ask payment for the gas spent while driving to come attend the interview.
And do you ask compensation for your intelligent views presented during the interview when they asked you a technical problem related to their real life scenario and your answer ended up solving that saving them millions.
And if I save them millions within the time box of an interview, they'll probably hire me anyway.
But I can invoice my time even though I'm not invoicing every detail of it.
You’re clearly leading toward the former, but I could just as easily make an argument for the latter.
In my experience, people with edifying jobs (usually because the problems are harder), are less likely to need to scratch the same itch outside of work.
I think requiring side projects not only shrinks the candidate pool, but also leads to adverse selection.
Of course, there's not enough data to make a foolproof conclusion but I'd say that so far for me, having side projects that a dev can show is a clear indicator that they are an interesting candidate.
And when counting side projects, I count tools developers make to make their life easier and in my experience even great developers with edifying jobs will have situations where they create some small tools to help make their life easier.
Everyone has a finite amount of time, they have other shit to do. The vast majority people irl just code for work. Are they bad programmers? Of course not.
I would say for the average employer paying an average salary, demanding you to showcase a portfolio of hobby project is plain obnoxious. The interviewer can hope the interviewee does some hobby projects and lives and breathes coding but demanding it as a baseline assessment for an interview is absurd.
For the average programmer when they have absolutely have nothing else to do maybe they will work on their sideprojects which even takes a backseat because they have to keep learning new crap every other week to make sure they are up to date.
So you’re expecting people to work more than 40 hours a week?
Even better, would you ask a chemical engineer for their spare time projects? How would that even come about?
> Would you ask a chemical engineer to bring a recipe for a proprietary drug synthesis
Nobody is asking for anyone to bring complete codebases, either. Not to mention that, in chemical engineering, if something is proprietary enough, there are patents. Those come with credits.
I get the feeling that programming is the only industry paranoid enough to treat the most utterly mundane work as if it was bomb codes, averse to recognition enough to not credit people and disorganised/rushed enough so that 99% of companies are unable to let workers share their findings with others in the field.
If you can pick up on the patterns of an unfamiliar language and/or codebase and make your code look like it fits in, you're probably good at both reading and writing code, and working with a team.
I can't speak for the parent commenter, but by "patterns" I am referring to multiple layers:
Detail -- Indentation, spacing, line length, naming convention, placement of braces and parentheses.
Flow -- pacing, grouping of blocks of code, levels of nesting, when and where to break up functions into spaced blocks or helper methods.
Architecture -- class boundaries, interfaces, cross-file organization.
There are higher layers but I haven't named them yet in mind and they aren't as well tested by this kind of interview.
In some ways it is unfortunate that services like GitHub and GitLab have become so dominant in the industry. If you're just working with plain git there is no assumption that squashing is some kind of binary decision the way the UIs of the online VCS services tend to present it. It's normal to do an interactive rebase and squash some commits to clean things up before sharing your code, yet keep logically separate changes in their own distinct commits, and you can have a much nicer commit history if you do than with either the no-squash or squash-everything extremes. Of course you can still do that with something like GitHub or GitLab as well but I think perhaps a lot of less experienced developers have never learned how or even why they might want to.
1) Getting a job that pays well isn't that easy in most fields
2) Getting a job as a software dev in FAANG or somewhere else desirable to many devs is plain difficult; you are competing against dozens and sometimes hundreds of candidates, some of whom are pretty good. There is no real "dev shortage" for these companies, if anything there's a huge inflation of devs who are qualified and want to work for them.
3) The tech interview process sucks and almost everyone acknowledges this and hates it; just 2 days ago I was asked a riddle about how to measure 45 minutes when burning ropes that take 60 minutes to burn. That was freaking half the interview, the other half was a difficult array question. Looking at the solution now there's no way I could come up with it even on a good day. And the company was a run of the mill company most people haven't even heard of, not exactly a FAANG. I was interviewing for a team with a pretty esoteric tech stack which I am super qualified for - but alas I get stressed when confronted with boys scouts riddles in a high pressure situation - so I must not be worthy of the job.
What I'm saying is - I think we all suffer in this together, it might be a bit better for recent grads but not by much. In the next downturn you will have dozens of people who know you well and will recommend you and help you get a job - a recent grad has nothing and will be the first to be let go since most of them can't really produce much yet. I'd take being 50 something with 2 decade worth of experience and connections than being a recent grad now.
It's an industry, where people make pretty sick money, for little experience. In fact, younger folks often make better salaries than older folks.
I worked for over 35 years, and never made as much as many kids right out of school, make, at FAANG (or is it now "MAANG"?) companies.
I was able to save and invest enough money, though, so that, when I was given the cold shoulder, at 55, I was able to take my toys and go home. That is a very, very rare privilege, and I am grateful. I feel as if I dodged a bullet. Many of the companies I looked at, made it clear, that, even if they did me the huge favor of offering me a job at a vastly substandard salary, they would treat me like garbage.
When the bubble bursts (and that may be coming. The horrid quality of so much of today's software is a real chicken coming home to roost), we will have huge armies of terrible programmers, desperate for work, and making it difficult to filter out the good ones.
Have you tried reaching out to people on your network who worked with you in the past? I think this together with your experience is a very strong asset. Reach out, tell them you want work, you might be pleasantly surprised that your age isn't much of an obstacle.
Open Source code plagiarism is a major problem and doing random forks/clone of popular repos to up your github cred is a thing and in my opinion it is unethical. Even if the interviewee tells you it is an open source project you will have a hard time distinguishing their code and the code from the original repo.
I think the interviewer should show their own production code and ask the interviewee what they think and what suggestion they have to offer. If you are not comfortable showing your own production code ask the interviewee to explore an open source codebase.
The "Show me what you got" approach puts way too much unjust pressure on a candidate and might force them to chose unethical means just to impress you. Then again if you want be impressed and if it is working so far for you, ignore my whole argument.
The conversation can just as well be around a library, product or system that isn't authored or contributed to, by the interviewee.
'What architecture is used here, and what are the down and upsides in this implementation'. 'What would you do different'. 'Which part do you admire, and what don't you like'. Etc.
Also why would I voluntarily talk about codebases authored by anyone other than me while having in-depth knowledge about it? Nobody looks under the hood of things that interests them, let alone be critical of it’s design.
Talking about product and system design is something that is vastly different than stand-alone codebase. If you as an interviewer are interested about something you have the capacity of directing the conversation flow toward that. Ask them introductory questions about a product/system, gauge their interest in it then ask their opinion about it.
Probably because you said “Bring code you've written”
Bizarre.
So trunk driven development means no PRs, until you decide you want to use PRs?
Short-lived branches like that site's describing just sounds like a team that's adopted git pretty well, but not formalized usage into gitflow or similar...
Feature flags can be used to gate features until they are ready, but all code is committed to trunk and is deployed to prod mostly continuously.
People look at the PR (which shows the diff) and approve it if they are happy, or request changes. If there are no conflicts, you can merge with a single button. Otherwise you need to resolve conflicts somehow. I normally just rebase the branch off updated master and force push.
> Creating a separate branch, pushing this to your public copy of the repository and then asking someone to pull from that branch into their master branch seems absurd to me.
That's how it works for open source projects because people do not have permissions to make branches in the main repo, so they must fork and have the changes in a different repo. I've never seen this done at a company, I presume everyone here is talking about creating branches in the main repo and requesting review before merging the branch to master.
Regardless of whether someone is pushing to a branch in the upstream repo or pushing to a branch in a fork, the workflow is the same either way. At worst, it just means adding a remote if you want to check out someone's code locally.
Either way, if you read the thread, the folks are arguing that giving someone the power to block code getting into the mainline is bad. Judging by what you described, where someone has to approve before it can be merged, we both agree to disagree with them. We are just arguing the semantics of how that is implemented.
Either way, just so you know, this kind of attitude and that you think it's a-ok to use such a convoluted process for what is effectively the same thing would 100% mean me not hiring you. That may not mean much on some random forum on the net, but you will encounter it a lot as the industry is definitely not aligned to this odd flow you described.
git commit
# ...
git commit # or two
git push HEAD:refs/for/master
Now they're immediately available for review. That looks something like this (this is not from my workplace, but the Go team's Gerrit instance): https://go-review.googlesource.com/c/go/+/361916
> Either way, just so you know, this kind of attitude and that you think it's a-ok to use such a convoluted process for what is effectively the same thing would 100% mean me not hiring you.
That's fine. There are plenty of companies that manage to hire based on competence, experience and references so I'm not exactly aching to get hired at a place that would deny me for having used Gerrit.
It requires a lot more effort and back and forth than you are describing and its disingenuous. I’m glad you’ve had a good experience with it though.
Writing an automation tool often has nothing to do with the experience and acumen required for a job, it could be a mouse motion recording to a bash script. It requires pure happenstance or contrived altruism to do it in a worse language for the task just to say “see look what I did” for a future employer
I think this requires more empathy, not in an “emotional intelligence” sense just in the concept of putting yourself in other people’s shoes and imagining what they encounter instead thinking what you encounter is normal
Not necessarily. If the HR is short-sighted, and that happens a lot for a lot of even famous companies, they'll say you have already saved the million and that your salary expectation is not worth it. Trust me, shit like this happens.
Theoretically yes (and they'll sure as hell contest that claim). But I've never seen anybody EVER do that except _very rarely_ for positions in Legal.
Do you honestly believe this?
Many people do this. I do this. It's the best way to learn¹. There are repeating Ask-HN threads requesting for "high quality Open Source Software to learn from" for example.
¹Edit: on second thought: probably not the "best" way. Not for me, anyway. Just a good way.
No thanks.
It really was just easier for me to throw in the towel. Like I said, I'm quite fortunate to be in the position that I'm in.
But it isn't work, if you enjoy what you do, and that's where I'm at. I never want to be in a position again, where my work is ignored and/or disrespected. I love to work, and take great pride in the Craft. That is treated as a "quaint anachronism," these days, so I guess I'm on my own.
Also, if they don't work there anymore, they should've deleted all the code (if they had it) and surrendered/cleared up all the laptops.
But I like your idea, anyway I give big kudos to candidates with their own pet projects.
It's that the interview process proposed by the G[...]P may force the candidate to do things that may be illegal to pass the interview. The candidate is of course responsible for their own choices, but the point is that as an interviewer, if you force your candidates to do this, you might short list those who have a tendency to violate contract terms.
This might work out for some, but I'd say it's a fair point to bring up.
I'm an employer right now in my small company. Don't see any reason to screw up my employees, on the contrary, I see it's much better to work in a friendly environment. There's no such "unimportant but necessary to the business" things.
What's your source?
"unimportant but necessary to the business"
What examples?
The win10 laptop is locked down tight, including removable drives disabled, DNS forced through corporate servers, SSH blocked outside network, etc. I wouldn't be surprised if all activity was somehow centrally logged for compliance too.
I had to request permission to whitelist my VPN account to access Github.com. Even with VPN disabled the laptop still uses corporate DNS.
The security policy is designed to prevent theft.
Of course there _are_ ways to circumvent these protections but you'd be in a world of legal trouble if caught.
• All commits SHOULD pass all CI tests
• Merge commits MUST pass all CI tests
The reason I don't require every commit to pass all tests is to maximize reviewability and logical consistency of commits.
For example, if a file needs to move, and then be modified slightly to function in its new location, I prefer to break that into two commits:
1. A verbatim move operation. This commit will fail CI but can be effortlessly reviewed.
2. Small modifications. This commit will pass CI, and its reviewability is proportional to its size.
In contrast, if you smush those two commits together, it can be hard to see where the meaningful changes occur in one giant diff. (Some tools may be smarter about showing a minimal diff for a move-and-modify commit under limited circumstances, but that doesn't always work.)
All of these constraints can be enforced programmatically, and if you're going to adopt them at all I think automating them is the way to do it.
Personally, whether I enforce this branching strategy varies from team to team and project to project.
Many projects I've been on had much, much bigger issues to deal with, so something second-order like this never gets to the top of the stack.
That said, it's an approach I like, and I think it yields benefits if you have a team that's bought into it.
The "right" answer is probably to refactor the test suite to be more performant, but that's never going to get approved given the amount of work that would take, and it would take me longer than I plan on being at the company to get it fixed in my spare time.
I do have it passing all tests before I try to merge if that counts?
To add to the above (everything is quite the same in my case): pasting medium chunks of data to external websites is restricted on the system level, same for uploading documents/images; emails to non-corporate addresses are scanned.
An asshole filter https://siderea.dreamwidth.org/1209794.html (maybe you've read already?)
There are, of course, ways, but some organisations make the overhead way too big to bother.
I personally know of a case where the 'core team' of a major payments processing system was running development being completely isolated from the internet due to security reasons. Need to check stackoverflow - sure - have a walk to the cabin where you have a dedicated machine connected to web for that. Oops, and no copy-paste, sorry.
I can't see how your approach can scale to hire tens or maybe hundreds of engineers.
Sounds like something that may somewhat work for you when you're the only one doing the hiring for your small team of buddies at a startup somewhere.
You're not even trying to tackle things like hiring for multiple roles, interview fairness, subconscious bias, technical diversity, feedback, or making the interview process accessible to a larger group of people that don't fit your cookie-cutter from the get go.
On a different note - I really hate the tone of your post. You come off as an arrogant person who's full of it and "has it all figured out". I'd easily pass on you just by reading these posts.
[1] and if these problems are unrelated (think Uber's human driver app vs self driving), then why are candidates passing through the same committee?
Mature products require competence in areas such as security, architecture, compliance, devops, research and much more. Hiring has to reflect that and account for it.
It's silly and immature to suggest a 90-minute chat about some crap your candidate will bring with them is somehow the answer here (and claiming that if they don't have anything to bring with them, then chances are that they're worthless anyways and you shouldn't waste your time on them). Especially without backing this up with any meaningful data (ie. attrition, number of people hired, actual impact on business, feedback received, etc).
> Sorry to be blunt, but chances are they aren't very good, and they are definitely not as good as they think they are.
I don’t know what to tell you.
It’s just so wrong it’s kinda wild how sure you are about this. At least half of the excellent colleagues I worked with in the past 10 years don’t fit your criteria. You’d be lucky to hire any of them.
We could dissect the entire thing but really, if that is how it works for you, fine. Just don't push it onto others as the absolute truth. If this stuff was really so great, empirical research would've hammered it home decades ago. But it doesn't, and continues to struggle finding any meaningful correlations between these "whacky fun strategies" and actual job performance.
1. Companies want to standardize their hiring when really they should be looking to customize it to each candidate.
2. Lots of companies want to spread the blame of a bad hire across a committee of 4 or 5 people, but I think if you looked you'll find many startups doing it this way. They stop when they grow to a large size. They do it because frankly hiring good engineers is no longer the top priority (it's typically quotas AKA butts in seats).
Again with the awkward appeal to authority.
Cut straight to it. Your post's title is "how to hire actually good engineers". So how many of those have you actually hired? How many of them stayed there 2 years into their roles? How do you know you've actually hired "good" engineers, and not just people you yourself thought were good enough at the time you interviewed and hired them? Have you actually followed up on your hires 3/6/12 months into their roles, to check that they're still as good as you thought they were?
By the way - "$1M+" sounds like a particularly low budget for "actually good engineers", ironically enough.
which was on top of a false dilemma to begin with
amazing
I get that the logical move is to get defensive, but just consider introspection
> Sorry to be blunt, but chances are they aren't very good, and they are definitely not as good as they think they are.
and there it is, one of the other subthreads is making fun of this kind of employer that swear by showing code
this is a false attribution bias where you decided not to notice that every evaluation technique the entire industry figured out will mostly by filled with people that cant code
your technique is simple no better
Is there a typo? The sentence doesn't make sense to me
The industry tries them all
Its the wrong conclusion on the efficacy of the technique
Posted this on behalf of the silent majority that likes the approach.
One cannot fill an abstract concept like a technique with things
Maybe you mean that every evaluation technique will detect that most of the job applicants aren't good at coding? And therefore, all evaluation techniques seem to work? (Although some techniques are a lot better than others)
If so, then, yes I agree. That's a good point
As one example, do you think cross-functional changes to the Linux kernel from even trusted contributors can just be merged without review and feedback from people across all affected subparts of the kernel, as long as they have been written through pair programming? That's a big open source example, but plenty of companies have plenty of projects for which that already applies as well.
> The prs where dogmatic as more junior teams get caught up in superficial things such as names, package structure, syntax preferences rather than what the pr actually does.
That is an easy trap to fall into (and wildly annoying), but it does not mean that PRs have no use outside of that.
Review also shouldn't be causing ego antagonisms. You're coworkers. You have to be able to work together. That's called having a job.
Every project I have worked on in a professional setting has had mandatory code review, with review acting as a gate. That's been required in order to maintain software quality despite the quality of engineers I've worked with.
All this means is that you and your team failed to learn anything from the PR process. If simple things like naming or syntax repeatedly come up then you have a style convention but the devs are ignoring it. The very obvious solution to that is to enforce the rules with a linter, and run the linter on a commit or push hook. If the linter fails then the dev can't open the PR until they fix the issues.
If you have process that's only for box checking and not something that's actually providing useful data the you're not using your time well enough. Removing the process is one solution, but it's not a very good one. Making the process useful is significantly better.
(Automating code quality stuff with linters is a no-brainer though.)
These two are not superficial, though. Naming things is one of the Hardest Things, and that and structure tell you if you're in the right spot trying to track down a bug or add a feature.
Every debugging session should not be an adventure.
As you write there is much more to it and one can only see through it after joining company.
For me trunk based development alone would be indicator that company is immature and does not even know they can have a process.
Thinking it always does or doesn't make sense just tells me you don't have experience working on diverse projects.
Like you totally disagree.
I described my experience and what I saw, well I did not do any scientific research on 1000s of companies. But I still think my experience has the same validity as your statement. So it can be both at the same time, there is so many companies small and big.
I'm sorry, what?
Review is a gate for everyone, and is a sign of basic project maturity. WebKit, Mozilla, Chrome, LLVM, Linux, etc are all review gated projects. No change is landed - can be landed - without review. If you're questioning the strength of those teams I cannot imagine what your team would need to have on it??
And pair programming? No thanks.
I think it you are doing actual code reviews, you are doing something wrong.
Smaller companies can pay much more (in expectation), and can simply poach the cream of the crop (who are invariably frustrated by useless process and corporate politics) from the big ones.
On top of that, most development processes are designed to minimize the blast radius of underperforming engineers, so your actual bar is "hire stronger engineers than the dregs from the giant shops".
Because in my experience, reviews and PRs certainly Ven damage latency, but overall throughput remains the same as it would be with subsequent follow-up fixes of these issues to the trunk.
Everyone is “gated” on a code review. The PR is one mechanism by which you can make code reviews easy. It says nothing about the strength of the team.
Yeah exactly, PR's are based on the fact that you have some person who is the owner that have complete power, and many other contributors who have zero power and whose contributions will mostly be rejected. You simply don't have that situation in a company, where everyone is an owner on equal terms, and all contributions are accepted, only some with slight modifications.
So you get these really weird situations where more junior, or less skilled, people can block PR's and demand changes from other more skilled and/or senior people. And if there's disagreement in a review: the resolution of that is completely unknown, and can often blow up to a really nasty conflicts.
I have so many terrible experiences with PR's where you get hostile nonconstructive comments on your work, on github, from a person that literally sits next to you. It's the creepiest thing ever.
PRs can be approved based on two people's opinion. There doesn't need to be a central gatekeeper.
> So you get these really weird situations where more junior, or less skilled, people can block PR's and demand changes from other more skilled and/or senior people.
Sometimes junior, or less skilled people, have something valuable to say. Especially if the code could be simpler.
In a stalemate, the PR could be sent to a third party. I've suggested this many times to avoid unnecessary conflict.
I don't think it is PRs that are the issue, rather your working environment.
Yeah and sometimes they are naive, dogmatic and overconfident, and on a crusade to change all the things! because they have read some blog post by uncle bob, and this tool is putting them in absolute power every time they do a review.
> In a stalemate, the PR could be sent to a third party. I've suggested this many times to avoid unnecessary conflict.
Ok and who might this lucky scapegoat be? I have a feeling it's not the manager for some reason..
> I don't think it is PRs that are the issue, rather your working environment.
The issue, which I'm trying to illustrate, is that the tool makes the working environment worse by introducing (hostile) dynamics between people that don't exist, which leads you into situations that you don't have resolutions for, situations that should not occur.
Using a tool that allows you to block other people's work causes unnecessary conflict in a team where people are supposed to be working together.
Edit: blocking contributions is a normal and natural thing in an open source workflow, and it is not normal and natural in a team inside a company.
IMO every developer should be an admin of the repo, but more importantly it’s not a gate, it’s a process that benefits communication. All the team can read and learn from small addings to the code base.
PR reviews should not equate to 100 comments either, complex discussions can (should imo) be worked out in a call discussing (dialog) best approach. Think of white boarding a problem with a fellow engineer friend.
Ofc, teams differ and some teams work better with other processes and other tools.
It's the tool itself and it's imposed workflow of blocking work and gaining absolute power in demanding changes, that causes the working environment to become toxic. Nobody would ever do that in a meeting "I'm blocking this work now until my demands have been met". That would be incredibly hostile, but with this tool it becomes normal.
Some might just push commits without knowing or caring about reviewing code, beyond fixing what fails in production. But others might just do "git flow" or whatever, doing thorough PRs, without knowing that the changes could be requested after being merged and without realizing the amount of time that is wasted on integrating code and re-testing.
In particular, I think that PRs come from an open source model, where you really have to gatekeep. But in a company, there is no problem in following up: the devs are salaried and you just need to put them to work on whatever is necessary.
I also don't like PR's/Unit Tests/other practices motivated in a way: "because that is what professionals/google/microsoft does".
Having engineers better than the competent engineers that are responsible for the dreaded process at the FAANGs, MS, etc is hard. The review policies of big projects tend to have been hard learned, and dismissing them because "they're useless process" is a poor choice.
I think you're conflating whether a process is useful for the organization with whether it is useful for the engineers implementing it. Since processes have to be uniform, you need to either figure out how to retain someone that's been at the company for a decade to continue to work maintenance jobs, or you need to figure out how to keep the fresh grads that will replace them from breaking the world.
The right choice for the organization is to keep production stable, and the bus factor high.
The right choice for the engineer is to demand massive comp increases (comparable to startup acquisition windfalls), and also the abilty to stop working maintenance.
A lot of the best engineers I've worked with used to be in a FAANG. Almost none of them would consider going back. They universally cite broken processes as the reason they left.
I'm getting downvoted because I'm criticising developers favorite tools that lets them pretend to be Linus Thorvalds for a moment.
But I'm okay with the conflict! There should be conflict at work! Ideas should be freely expressed and those ideas are going to meet contrary ones!
What wouldn't be healthy is a place where that conflict isn't resolved or doesn't lead to a better idea winning. Or where only the Lead "wins" because of their position.
There shouldn't be arguments, no one should yell or be hurt. For sure that's a bad place to work. But conflict about where to place a piece of code? Sure! Conflict about if we name it Foo or Bar? Why not?! That conflict is like the sharpening of Iron! It hurts _today_ but can strengthen and make _you_ better let alone the organization as a whole.
I dearly hope this is sarcasm. This is about the same level of absurdity as developers taking ages to pick project/file names. I'm not railing against a review's abilities to find bugs and make sure someone else understands. GP is right in pointing out how many fruitless review discussions exist over personal differences in what to call a function name because "I think X sounds better than Y", despite every party involved understanding the code and what it does.
If only linters could solve these trivialities.
Though the size and risk of a project do materially matter. If chrome ships a bug, that'll cause an impact on billions of people potentially, where as the typical software bug will impact a few hundred or dozens of people?
The way you get any project to be "actually good" is by adopting methods to ratchet quality. Early WebKit did not have the same strict rules it has today, and we suffered because of that. Introducing review + test for every change rule was introduced, and the frequency of regressions dropped dramatically.
PRs are a great way for the whole team to learn about how the organisation cuts code, and can reduce the number of errors, but of course with poor leadership they can be used for evil.
"Code reviews", in general, are a good thing for knowledge transfer. If they are done for nit picking and stylistic complaints, they are not terribly valuable.
I can imagine that you had fun mingling with the commoners for a day, now try it on all of your actual work, and with the whole C-level team gang up on you for each review.
> about how the organisation cuts code
You don't have any guidelines for how the organisation cuts code, and that's why you like the review process, because it covers up for that.
> I can imagine that you had fun mingling with the commoners for a day, now try it on all of your actual work, and with the whole C-level team gang up on you for each review.
You literally know nothing about me, my experiences or how I conduct my life, and rather than listen to people with a different experience to yours, you choose borderline abuse.
This is the comments section of HN. Take a break and get some perspective.
Maybe your work experience is mostly in a high stress, prototype-heavy environment where it's more important to launch something than it is to have a maintainable, incrementally improving codebase? I worked at a consultancy like that and it was very different from "big product" long term work.
As for the social dynamics, it sounds like your workplace culture just blows.
Only if some regulation requires sign offs from e.g.other depts. PRs are inevitable. In all other situations they are at best an inneficient workflow and at worst a Kafkaesque circus.
Peer programming, daily checkups, a rock solid CI, and, above all, trust in the professionalism of your team are some ingredients for high quality, high throughput software development.
This is not an opinion. It's a scientifically proven fact. As laid out in the book Accellarate.
The point was not that "review" is bad, or should be avoided. But that a Pull-Request is a poor way to do that review. Reviewing is crucial, IMO.
Absolutely agree, the collaboration should happen sooner in the process, and I would add that the team should probably also have made at least a high level proposed solution together before the work even started.
Fuck that dogpile of bullshit.
You've never seen a 1200 line diy function to parse XML have you?
Yeah but the tool itself is antagonistic, because it imposes a workflow of open source, a workflow that also is antagonistic with clear and absolute power. So using that tool suddenly brings that antagonism and power into a team which is supposed to be 100% collaborative, and it also only does it periodically and with random and different people in power. It's not hard to see how that becomes somewhat complicated.
If a team inside a company want to gather inspiration from the open source world, they should look at how the owner teams of open source projects work internally, not how they work together with outside contributors.
And, it's a very common "solution" in tech to just simply not have any feelings, but people have feeling and that you can't turn off, and that's a very important contributor to work satisfaction.
Is code review not collaborative in your experience? In every team I've been on/run we've split code review comments between suggestions/questions and actual "I will not let this go into prod if my name is attached to it" blockers. Code review has been 99% the first set of comments and only rarely do I see anyone actually block reviews over things like style and what not that have been mentioned here.
I can't even imagine those topics getting into code review as a blocker as if we have actually strongly held opinions on mechanical issues like that, they are integrated into the various linters used so you don't even need human eyes to catch the issue.
I've had patch review as back and forth comments in email, in bugzilla, in myriad other bug databases.
If you can't send out an email with your patch as an attachment, and get feedback, then we have a problem, and the problem is not the adversarial nature of review.
I've found PR's become important approximately when feature momentum starts to drop.
shudders
Your very premise is wrong. At any sufficiently large company, you are unlikely to be sitting in the same room as every collaborator and stakeholder, or even proxies for them.
As a simple example, the team I currently work on (on one project of several) is 10 people across 8 US cities in all four US mainland timezones, and the stakeholders and collaborators are across Australia, Asia, Europe and the Americas. A good majority of what I do is pair programmed, yet the pull request workflow is essential to letting _others_ know what is happening and why, and to allow them to have asynchronous input into the process.
You might argue it would be better for the team to be in a room somewhere. Maybe so, but the people this project demands live where they live and could not even agree a common location for that room to be if they wanted to. And it still wouldn’t help the other projects…
The goal in review is to try to catch any oversights or errors in the code you wrote. The code you wrote may have been the result of of discussions with your coworkers, but the code still gets reviewed, even if by people you discussed the implementation with. That review will occasionally find things you missed, and then you can cycle, and re-review.
By definition, the review can only happen at the end of change development.
The only thing PR's lack in that regard is that if the reviewer accepts it then it gets added automatically, while ideally you should re review things after the reviewer has accepted it. That way they wont accidentally accept prototype changes.
The tool does not stop you from working in the way you suggest. Maybe it's not what the engineers who wrote it originally envisioned, but it's both simple and easy to work in the way you suggest.
Yeah good luck with that, nobody can completely separate criticism of their work from criticism of themselves. You are making your job as the team leader way to easy for yourself, "I only hire robots, that's how I solve all these pesky people issues".
The guy who couldn't take feedback (person A) had code merged in that wasn't properly tested. Person B said, "hey A. I could use some help. We wrote some tests around $feature that were missing and the tests show the feature doesn't work. We see $unexpected results. Wanna make sure we agree on how this should work."
Person A: no, it works, I tested it.
B: could you help us identify the flaw in the tests then - they seem rock solid.
A: no, my code works.
B: ... ok, can you join us and talk through it?
A: no, it works.
A was removed from the team after management came in and A continued to not acknowledge his code could be wrong.
This was aberrational. We, as an org and as a team, constantly strove to keep the focus on the quality of the code. And, yes, his code was borked.
Yeah I really hate those pesky automated linters running in standardised environments telling me I’ve screwed something up.
(/sarcasm, hopefully clearly!)
It's the bare minimum of professionalism.
If you are unable to separate feedback on your work, from attacks on your person, you are lacking some fairly fundamental skills needed for professional engineering.
Or for any job role at all?
My suggestion is more along the lines of: use a pairing session for review so that you can bring your empathy as well as your technical expertise, and make it a step in the process just like any other steps (testing, PO approval) etc, and just trust people to do it.
I don't think there's any reason to use a tool from open source, to make code review enforced and with passive aggressive online communication and "blocking". Just seems to make work more painful, and less efficient as well actually.
And yes, someone that lost is pretty rare, but I'd say lower-grade versions of non-transparency and making their work hard to follow is pretty typical (and frustrating).
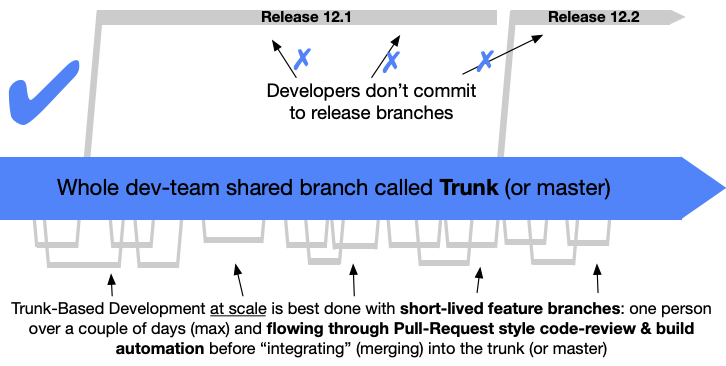{kind=link}