Hacker News “Who is Hiring?” top-level comments over time(blog.joewoods.dev) |
Hacker News “Who is Hiring?” top-level comments over time(blog.joewoods.dev) |
There's also free tiers on many CDNs like Fastly/Cloudflare. Github Pages is also free.
https://www.digitalocean.com/community/tutorials/how-to-depl...
Looks like the free one has only 1GB outbound transfer which wouldn't be enough for a single hug, but the $5/month one has 40GB which might be enough for a hug with text only content.
But most problems like that can be solved with caching no matter which tech you're using.
Where’s the free lunch in that line of thinking? which cases are a droplet better in?
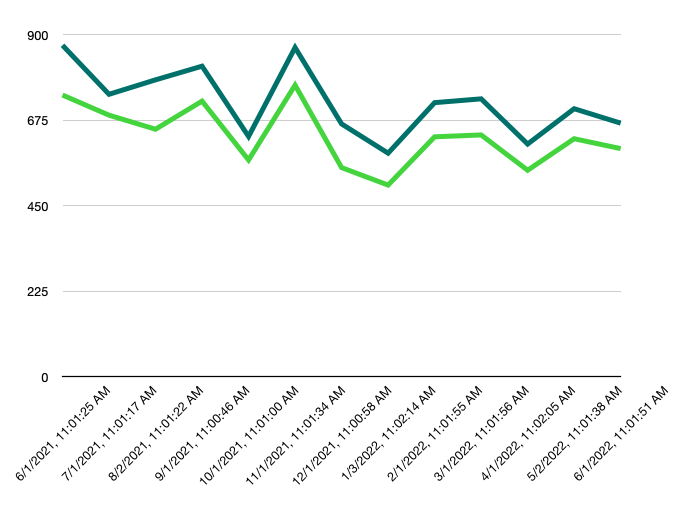
I was thinking about this same problem for a couple of days. Another question I have is: do we have a higher number of top-level comments on a given number of months or not?
That about correlates to my impression that this is not the recession.
Here's a query for a rough reproduction of what's asked in the title:
WITH whoishiring_threads AS (
SELECT id FROM `bigquery-public-data.hacker_news.full`
WHERE `by` = "whoishiring"
AND REGEXP_CONTAINS(title, "Ask HN: Who is hiring?")
)
SELECT FORMAT_TIMESTAMP("%Y-%m", `timestamp`) as year_month,
COUNT(*) as num_toplevel_posts
FROM `bigquery-public-data.hacker_news.full`
WHERE parent IN (SELECT id FROM whoishiring_threads)
GROUP BY 1
ORDER BY 1
Still a bit of room to clean up the query, though, and there are some differences from the chart in the post.
I was wondering if you could detect the slow rise of a new technology and profit from it. Either by retraining or more directly, in the case of crypto, by trading on that info. I put together something, focused on a couple of crypto technologies and as luck would have it, it's still online !
[0] https://datum.alwaysdata.net/static/data-hnjob-trends/index....
Looks like you have June 2021 as the all time high as well. Doesn't look like June 2022 is going to get even close, which makes sense based on current freezes/layoffs.
But really if I knew finance I’d be interested to see - since who’s hiring is posted the first day of the month, using month over month/etc post volume to inform trades.
Thank you for writing this.
But my website seems to have disappeared, so I'll have to update the post later!
The tide has turned for sure.
The anecdote of Tesla posting a bunch of jobs just before the 10% reduction was announced comes to mind. Lagging indicator stuff.
" If job ads were threads, each thread would be a generic referendum on the company. Worse, it would be the same referendum over and over.
Job ads are boring, so there wouldn't be anything to discuss other than how one feels about the company, and that's boring except to people who have strong feelings on the topic, and strong feelings on the internet tend to be negative, so the threads would fill up with negative generic comments.
I believe that the hivemind resents boring things, such as submissions where the only new information is "X is hiring", so it gets cranky and fills the vacuum with indignation, basically as the only way to amuse itself in the absence of anything interesting to discuss. It doesn't want to, it just doesn't know any better way to have fun in a vacuum. In practice, what this would look like in a job thread is "I applied in 2015 and never heard back", plus—if there has ever been a negative story X about the company—every variation of X, X, X, repeated increasingly snarkily.
Actually, it's worse. Building a business is a long hard slog. One needs to hire far more often than one has scintillating new information for the community to have fun discussing. Therefore, each successive job ad would be even more boring than the previous one, leading to monotonically increasing resentment. Repetition is the enemy of curiosity.
Launch posts don't suffer from this dynamic because by definition, the startup is new, so there's something new to discuss. "
HTH
Say by comparing with an employees official job site and the HN post role.
It's interesting to see March 2020 (the highest month of all time) and April 2020 (the lowest month since early 2016) back to back.
One thing that's interesting: this is a sneaky case where the line hides two missing months in 2015.
Good thing there aren’t any laws that regulate copyright or privacy, so datasets like this can be published without asking users for consent.
So while your idea is nice it wouldn't work because not every company lhas the same recruitment process, frontend or backend (visible to the candidate vs workable for the recruitment teams)
I did see this in one example in the “who’s hiring” thread here, but also in following the newsletter for a startup I applied to.
Two reasons I saw in my last job hunt:
1. The company is lowballing wages.
2. The hiring manager for the position does not want to hire or is not aligned with the startup team‘s decision that they should hire for the role.
You can get good at qualifying for these scenarios early, but if you don’t have experience looking for and actively screening these out, a list of repeat posts might save some people time.
At least it might add weight to a possible dismissal.
So, not sure this methodology identify quite what you're looking for.
I’m sure there are other reasons companies would post each month: churn, or always on the lookout for strong talent, etc.
Also not having to learn another tech for something you'd only have to set up once every year or few years.
User Content Transmitted Through the Site: With respect to the content or other materials you upload through the Site or share with other users or recipients (collectively, “User Content”), you represent and warrant that you own all right, title and interest in and to such User Content, including, without limitation, all copyrights and rights of publicity contained therein. By uploading any User Content you hereby grant and will grant Y Combinator and its affiliated companies a nonexclusive, worldwide, royalty free, fully paid up, transferable, sublicensable, perpetual, irrevocable license to copy, display, upload, perform, distribute, store, modify and otherwise use your User Content for any Y Combinator-related purpose in any form, medium or technology now known or later developed. However, please review the Applications Privacy Policy located at https://www.ycombinator.com/apply/privacy, for more information on how we treat information included in applications submitted to us.
is Google ( or Alphabet ) an affiliated company?
If you need some dynamism, w3 total cache is also a great choice.
If you're not an nginx hacker, there are some great examples around the internet. This page is pretty helpful: https://wordpress.org/support/article/nginx/
https://www.cloudflare.com/performance/ensure-application-av...
i actually migrated from Wordpress to Zola
Edit: Yes, even WordPress. Unless there are 50 plugins, an unoptimized theme, zero caching, and a resource constrained server.
P.S. OP's website uses Apache but the same issue of overly conservative limits still apply.
<strike>When each request is from a different person, you get essentially zero cache.</strike> Nope, server-side caching reduces back-end processing.
https://www.nginx.com/blog/overcoming-ephemeral-port-exhaust...
A common sense approach would be to say that if someone in Europe chooses to submit their details to an entity based outside of Europe then that's just their choice to waive their rights to their data.
Lawyers and legislators might make arguments and talk about analogous laws and situations but that simple doesn't convince a lot of people. Hence you will get downvotes for saying something so common is illegal.
(As a side-note it's interesting that you personally choose to submit your copyrighted comments to HN given your knowledge of how you're losing effective control of your information.)
yeah, you may wanna check your maps - youre a little too far from home.
The HN is pseudonymized, more anonymous than the kernel git.
So what's next? Prohibiting git clone on the kernel git? Because someone could do summary statistics there?
There's fastcgi caching in nginx, php opcode in php-fpm, and WP specific cave plugins like Super Cache. At least this was the case ~10 years ago.
Everything old is new again. Gotta tune it out.
{kind=link}
{kind=link}