A litanny of "gotchas", where someone attempts to best the OP. What about x, y and z? It can't possibly scale. Twitter is so much more than this, etc.
The OP isn't making the assertion that Twitter should replace their current system with a single large machine.
The whole thread paints a picture of HN like it is full of a bunch of half-educated, uncreative negative brats.
To the people that encourage a fun discussion, thank you! Great things are not built by people who only see how something cannot possibly work.
I love that Tristan put out this post and made it so detailed with plenty of assumptions to cover. I also like to hear about possible issues and assumptions which the crowd calls out. Even naysayers can be helpful.
I want both, but I don't want to crowd to go to far and kill the desire to produce this kind of content.
The comments that I think aren't contributing much are ones that mention features that I didn't cover but make no attempt to argue that they're actually hard to implement efficiently, or that assert that because I didn't implement something it isn't feasible to make as fast as I calculate, without arguing what would actually stop me from implementing something that efficient. Or ones who repeat that this isn't practical, which I say at length in the post.
I think it's easy to have both. It's all about the tone of the responses.
For example, instead of "your assumptions are wrong, this would collapse because X" or "this is dumb because real Twitter does Y which yours doesn't handle," I think responses could be framed as:
"Wow, neat thought experiment! If I were to approach this same problem, I might make an allowance of more than 280 bytes of storage per tweet to allow for additional metadata that is probably needed to make everything work together; I wonder if that can be accommodated with an even beefier big computer?"
Or "What a great writeup of building a simplified Twitter! After the features you've accounted for, the next most important feature of Twitter for me personally is Y. What kinds of things would we have to do to stretch your idea to handle that? [or, I bet with the addition of X we could make that happen in this setup too!]"
I think many criticisms could be turned into constructive positive additions to the original article versus attacks against the idea of the article.
I find it much more appealing to just make the whole thing run on one fast machine. When you suggest this tend to people say "but scaling!", without understanding how much capacity there is in vertical.
The thing most appealing about single server configs is the simplicity. The more simple a system easy, likely the more reliable and easy to understand.
The software thing most people are building these days can easily run lock stock and barrel on one machine.
I wrote a prototype for an in-memory message queue in Rust and ran it on the fastest EC2 instance I could and it was able to process nearly 8 million messages a second.
You could be forgiven for believing the only way to write software is is a giant kablooie of containers, microservices, cloud functions and kubernetes, because that's what the cloud vendors want you to do, and it's also because it seems to be the primary approach discussed. Every layer of such stuff add complexity, development, devops, maintenance, support, deployment, testing and (un)reliability. Single server systems can be dramatically mnore simple because you can trim is as close as possible down to just the code and the storage.
Meanwhile the company I just left was spending more than this for dozens of kubernetes clusters on AWS before signing a single customer. Sometimes I wonder what I'm still doing in this industry.
Yup.
Cloud is 21st century Nickel & Diming.
Sure it sounds cheap, everything is priced in small sounding cents per unit.
But then it very quickly becomes a compounding vicious circle ... a dozen different cloud tools, each charged at cents per unit, those units often being measured in increments of hours....next thing you know is your cloud bill has as many zeros on the end of it as the number of cloud services you are using. ;-)
And that's before we start talking about the data egress costs.
With colo you can start off with two 1/4 rack spaces at two different sites for resilience. You can get quite a lot of bang for your buck in a 1/4 rack with today's kit.
I suppose there's a chance AI will get to the point where we can feed it a ruby/python/js/whatever code base and it can emit the functionally equivalent machine code as a single binary (even a microservices mess).
There's some big problems with this approach today, namely, it's not always right, and it may sometimes be half right (miss edge cases).
But think of where this AI technology is headed -- it stands to reason it will eventually work pretty much perfect.
And then I think we'll see another very strong trend -- large AI models replacing other forms of software. Why write a compiler when GPT3 can compile C to asm? Why write an interpreter when GPT3 can "compile" python to C?
The AI model is hilariously less-efficient than traditional software, but it will be far far cheaper and faster to create than the traditional equivalent.
What other types of software will be replaced by AI models?
The stuff that actually is CPU-bound often ends up being written in an appropriate language, or uses C extensions (e.g. ML and data science libraries for Python).
This post is perfect world thinking. We don't live in a perfect world.
However, the stateless workload can still operate in a read-only manner if the stateful component failed.
I run an email forwarding service[1], and one of challenge is how can I ensure the email forwarding still work even if my primary database failed.
And I come up with a design that the app boot up, and load entire routing data from my postgres into its memory data structure, and persisted to local storage. So if postgres datbase failed, as long as I have an instance of those app(which I can run as many as I can), the system continue to work for existing customer.
The app use listen/notify to load new data from postgres into its memory.
Not exactly the same concept as the artcile, but the idea is that we try to design the system in a way where it can operate fully on a single machine. Another cool thing is that it easiser to test this, instead of loading data from Postgres, it can load from config files, so essentially the core biz logic is isolated into a single machine.
---
Unsolicited story time:
Prior to my joining the company Hostway had transitioned from handling all email in a dispersed fashion across shared hosting Linux boxes with sendmail et al, to a centralized "cluster" having disparate horizontally-scaled slices of edge-SMTP servers, delivery servers, POP3 servers, IMAP servers, and spam scanners. That seemed to be their scaling plan anyways.
In the middle of this cluster sat a refrigerator sized EMC fileserver for storing the Maildirs. I forget the exact model, but it was quite expensive and exotic for the time, especially for an otherwise run of the mill commodity-PC based hosting company. It was a big shiny expensive black box, and everyone involved seemed to assume it would Just Work and they could keep adding more edge-SMTP/POP/IMAP or delivery servers if those respective services became resource constrained.
At some point a pile of additional customers were migrated into this cluster, through an acquisition if memory serves, and things started getting slow/unstable. So they go add more machines to the cluster, and the situation just gets worse.
Eventually it got to where every Monday was known as Monday Morning Mail Madness, because all weekend nobody would read their mail. Then come Monday, there's this big accumulation of new unread messages that now needs to be downloaded and either archived or deleted.
The more servers they added the more NFS clients they added, and this just increased the ops/sec experienced at the EMC. Instead of improving things they were basically DDoSing their overpriced NFS server by trying to shove more iops down its throat at once.
Furthermore, by executing delivery and POP3+IMAP services on separate machines, they were preventing any sharing of buffer caches across these embarrassingly cache-friendly when colocated services. When the delivery servers wrote emails through to the EMC, the emails were also hanging around locally in RAM, and these machines had several gigabytes of RAM - only to never be read from. Then when customers would check their mail, the POP3/IMAP servers always needed to hit the EMC to access new messages, data that was probably sitting uselessly in a delivery server's RAM somewhere.
None of this was under my team's purview at the time, but when the castle is burning down every Monday, it becomes an all hands on deck situation.
When I ran the rough numbers of what was actually being performed in terms of the amount of real data being delivered and retrieved, it was a trivial amount for a moderately beefy PC to handle at the time.
So it seemed like the obvious thing to do was simply colocate the primary services accessing the EMC so they could actually profit from the buffer cache, and shut off most of the cluster. At the time this was POP3 and delivery (smtpd), luckily IMAP hadn't taken off yet.
The main barrier to doing this all with one machine was the amount of RAM required, because all the services were built upon classical UNIX style multi-process implementations (courier-pop and courier-smtp IIRC). So in essence the main reason most of this cluster existed was just to have enough RAM for running multiprocess POP and SMTP sessions.
What followed was a kamikaze-style developed-in-production conversion of courier-pop and courier-smtp to use pthreads instead of processes by yours truly. After a week or so of sleepless nights we had all the cluster's POP3 and delivery running on a single box with a hot spare. Within a month or so IIRC we had powered down most of the cluster, leaving just spam scanning and edge-SMTP stuff for horizontal scaling, since those didn't touch the EMC. Eventually even the EMC was powered down, in favor of drbd+nfs on more commodity linux boxes w/coraid.
According to my old notes it was a Dell 2850 w/8GB RAM we ended up with for the POP3+delivery server and identical hot spare, replacing racks of comparable machines just having less RAM. >300,000 email accounts.
https://patents.google.com/patent/US20120136905A1/en (licensed under Innovators Patent Agreement, https://github.com/twitter/innovators-patent-agreement)
I could have definitely served all the chronological timeline requests on a normal server with lower latency that the 1.1 home timeline API. There are a bunch of numbers in the calculations that he is doing that are off but not by an order of magnitude. The big issue is that since I left back then Twitter has added ML ads, ML timeline and other features that make current Twitter much harder to fit on a machine than 2013 Twitter.
The second is, it's interesting to understand social media industry wide infra cost per user. If you look at FB, Snap, etc. they are within all within an order of magnitude in cost per DAU (DAU / Cost of revenue) of each other. This can be verified via 10-ks which show Twitter at $1.4B vs. SNAP 1.7B Cost of Revenue. The major difference between the platforms is revenue per user, with FB being the notable exception.
Also would you summarize the patent/architecture? The link is a bit opaque/hard to read.
Note: Cost of Revenue does also include TAC and revenue sharing (IIRC) and not just Infra costs but in theory they would also be at similar levels.
eg. SNAPs 10-k https://d18rn0p25nwr6d.cloudfront.net/CIK-0001564408/da8288a...
Sure its expensive, and you have to deal with IBM, who are either domain experts or mouth breathers. Sure it'll cost you $2m but!
the opex of running a team of 20 engineers is pretty huge. Especially as most of the hard bits of redundant multi-machine scaling are solved for you by the mainframe. Redundancy comes for free(well not free, because you are paying for it in hardware/software)
Plus, IBM redbooks are the golden standard of documentation. Just look at this: https://www.redbooks.ibm.com/redbooks/pdfs/sg248254.pdf its the redbook for GPFS (scalable multi-machine filesystem, think ZFS but with a bunch more hooks.)
Once you've read that, you'll know enough to look after a cluster of storage.
Through intense digging I found a researcher who left a notebook public including tweet counts from many years of Twitter’s 10% sampled “Decahose” API and discovered the surprising fact that tweet rate today is around the same as or lower than 2013! Tweet rate peaked in 2014 and then declined before reaching new peaks in the pandemic. Elon recently tweeted the same 500M/day number which matches the Decahose notebook and 2013 blog post, so this seems to be true! Twitter’s active users grew the whole time so I think this reflects a shift from a “posting about your life to your friends” platform to an algorithmic content-consumption platform.
So, the number of writes has been the same for a good long while.
But sure, go ahead and take this as evidence that 10 people could build Twitter as I'm sure that's what will happen to this post. If that's true, why haven't they already done so? It should only take a couple weeks and one beefy machine, right?
SEAN: So if I asked you about art you’d probably give me the skinny on every art book ever written. Michelangelo? You know a lot about him. Life’s work, political aspirations, him and the pope, sexual orientation, the whole works, right? But I bet you can’t tell me what it smells like in the Sistine Chapel. You’ve never actually stood there and looked up at that beautiful ceiling. Seen that.
I think Twitter does (or at some point did) use a combination of the first and second approach. The vast majority of tweets used the first approach, but tweets from accounts with a certain threshold of followers used the second approach.
I know it's not the core premise of the article, but this is very interesting.
I believe that 90% of tweets per day are retweets, which supports the author's conclusion that Twitter is largely about reading and amplifying others.
That would leave 50 million "original" tweets per day, which you should probably separate as main tweets and reply tweets. Then there's bots and hardcore tweeters tweeting many times per day, and you'll end up with a very sobering number of actual unique tweeters writing original tweets.
I'd say that number would be somewhere in the single digit millions of people. Most of these tweets get zero engagement. It's easy to verify this yourself. Just open up a bunch of rando profiles in a thread and you'll notice a pattern. A symmetrical amount of followers and following typically in the range of 20-200. Individual tweets get no likes, no retweets, no replies, nothing. Literally tweeting into the void.
If you'd take away the zero engagement tweets, you'll arrive at what Twitter really is. A cultural network. Not a social network. Not a network of participation. A network of cultural influencers consisting of journalists, politicians, celebrities, companies and a few witty ones that got lucky. That's all it is: some tens of thousands of people tweeting and the rest leeching and responding to it.
You could argue that is true for every social network, but I just think it's nowhere this extreme. Twitter is also the only "social" network that failed to (exponentially) grow in a period that you might as well consider the golden age of social networks. A spectacular failure.
Musk bought garbage for top dollar. The interesting dynamic is that many Twitter top dogs have an inflated status that cannot be replicated elsewhere. They're kind of stuck. They achieved their status with hot take dunks on others, but that tactic doesn't really work on any other social network.
That was some time ago, though.
9 web servers to serve the entire network. I wish more developers were aware of just how performant modern (non-cloud) hardware is.
The ultimate extension of this "run it all on one machine" meme would be to run the bots on the single machine along with the service.
Not so, serving an ad to a bot gains you no revenue, because ad networks charge for clicks, not impressions. If a significant percentage of your ad clicks are from bots, you're running a defective advertising platform and won't have customers for long regardless.
Just a small nitpick: most ad networks optimize for price of impression, so at the end of the day they charge for impressions (just not always directly).
If your ad has low click rate and average price then it just won't be shown, because it's more profitable for an ad network to show ad with better click rate or with better price (i.e. with better price for impression) .
I learned this the hard way when I was running a medium-sized MapReduce job in grad school that was over 100x faster when run as a local direct computation with some numerical optimizations.
Most then suggest scale that would make the service run comfortable from a not-too powerful machine, and then go to design data-center spanning distributed service.
Over the last couple of months I've seen comments that summarise Twitter as a read-only service that doesn't have any real time posting requirements and similarly other comments that treat it as a write-only service with no real time read / fast search requirements.
Without _all_ the blocks even the simple surface level Twitter will have complexity people miss.
https://lenovopress.lenovo.com/assets/images/LP1195/Mellanox...
Betteridge antiexamples are always welcome. I once tried to joke that Mr. Betteridge had "retired" and promptly got corrected about his employment status (https://news.ycombinator.com/item?id=10393754).
It's very simple to make a PoC on a very powerful machine, make it ready from production serving hunderd of millions of users is completely different.
Nobody should be looking at this and thinking that it’s realistic to actually serve a functional website at this scale on a single machine with actual real world requirements.
Several ways of doing this without relying on k8s
> observability
This doesn't require k8s neither and it's more on your app. Systemd can restart systems by itself
> how do you update that stack without bringing down everything
That's probably where redundancy helps the most. I wouldn't run a big service without it (but again it found be at server level)
I'll say that this is a good point, especially because if you don't use containers or a similar solution (even things like shipping VM images, for all I care), you'll end up with environment drift, unless your application is a statically compiled executable with no system dependencies, like a JDK/.NET/Python/Ruby runtime or worse yet, an application server like Tomcat, all of which can have different versions. Worse yet, if you need to install packages on the system, for which you haven't pinned specific versions (e.g. needing something that's installed through apt/yum, rather than package.json or Gemfile, or requirements.txt and so on).
That said, even when you don't use containers, you can still benefit from some pretty nice suggestions that will help make the software you develop easier to manage and run: https://12factor.net/
I'd also suggest that you have a single mechanism for managing everything that you need to run, so if it's not containers and an orchestrator of some sort, at least write systemd services or an equivalent for every process or group of processes that should be running.
Disclaimer: I still think that containers are a good idea, just because of how much of a dumpsterfire managing different OSes, their packages, language runtimes, application dependencies, application executables, port mappings, application resource limits, configuration, logging and other aspects is. Kubernetes, perhaps a bit less so, although when it works, it gets the job done... passably. Then again, Docker Swarm to me felt better for smaller deployments (a better fit for what you want to do vs the resources you have), whereas Nomad was also pretty nice, even if HCL sadly doesn't use the Docker Compose specification.
Containers are a good common denominator because you essentially start with the OS, and then there's a file that automates installing further dependencies and building the artifact, which typically includes the important parts of the runtime environment.
- They're stupidly popular, so it basically nullifies the setup steps.
- Once setup, they by combinding both OS layers and App, they solve more of the problem and are therefore slightly more reliable.
- They're self-documenting as long as you understand bash, docker, and don't do weird shit like build an undocumented intermediary layer.
Together they largely solve the "works on my PC" problem.
In my experience this ended up with more complicated.
Those systems are typically developed by people who already left and are undocumented, and they become extremely difficult to figure out the config (packages, etc files... oh, where even the service files are located?) and almost impossible to reproduce.
It might be okay to leave it there, but when we need to modify or troubleshoot the system a nightmare begins...
Maybe I was just unlucky, but at least k8s configs are more organized and simpler than dealing with a whole custom configured Linux system.
We have python service which consumes gigabytes of RAM for quite simple task. I'm sure that I'd rewrite it with Rust to consume tens of megabytes of RAM at most. Probably even less.
But I don't have time for that, there are more important things to consider and gigabytes is not that bad. Especially when you have some hardware elasticity with cloud resources.
I think that if you can develop world-scale twitter which could run on a single computer, that's a great skill. But it's a rare skill. It's safer to develop world-scale twitter which will run on Kubernetes and will not require rare developer skills.
Indeed.
Lots of examples out there, one being Let's Encrypt[1] who run off one MySQL server (with a few read replicas but only one write).
[1] https://letsencrypt.org/2021/01/21/next-gen-database-servers...
If anything, Kubernetes allows you to save cost by going with a scalable number of small, inexpensive, fully utilized machines, vs one large, expensive, underused one.
Like kafka.
My impression is that it is the serialisation that comes with each service-to-service communication that is really expensive.
What if your unique machine crash?
I think you mean vertical, right?
https://k3s.io/ makes it really easy to set up, too.
The only thing bad about single server kubernetes is that it'll eat like 1-2 GB of RAM by itself. When you whole server could be 256 MB, that's a lot of wasted RAM.
As soon as you start accounting for redundancy you have to fan out anyway.
Until very recently, while money was still very cheap, the time overhead it would take to manage this just was not worth the cost savings.
Even with the market falling out from under VC, I think it still is a good tradeoff for many shops.
In one afternoon (at most), I could have written a script to deploy our demo with docker compose over ssh. Sure, docker compose won't scale forever, but their runway didn't last forever either.
You can get up to $100k and it's a big reason many startups go in that direction.
Also $20k is nothing when you factor in developer time etc.
Totally out of topic here, but could be he just wants the ability to amplify his own ideas. Also, why measure Twitter value (arbitrarily?) by number of unique tweets, rather than by read tweets?
Can you educate us on how to have a resilient app with no-downtime updates at the server level.
Because if you're doing this via software then it's no different to Kubernetes.
Yeah, k8s might be the easiest way of doing this today if you want only 1 physical server
Sounds like you already have quite a number of different containers already.
But it's a pretty objective notation that manually scaled single machines don't scale as well as automation.
If you're just doing a simple application, Sentry really is the way to go, while Datadog and ELK are agent-based and more intended for complex setups and big enterprises (especially in their pricing structure/infra costs).
It is an example. It shows you how you can run a service that issues a few hundred million SSL certs a year off relatively few pieces of hardware, i.e. no need to go drinking the cloud Kool aid.
There will never be a "perfect" example. The overall point here is demonstrating that the first answer to everything doesn't have to include the word "cloud".
> The database alone has multiple machines.
As I said, and the blog says ... there is only one writer. The other nodes are smaller read replicas.
Which again shows you don't need to go with the cloud buzzword-filled database services.
"100 million certs a year" is only like ~3 certs a second. Maybe twice in peak. That's not much. And you're doing same error, focusing on one core feature and ignoring everything around it
And what happens if that writer goes down. Then the service just stops.
> buzzword-filled
I love how your buzzwords e.g. read replicas are okay but everyone else's are bad.
It's not. Utilization is a key metric in capacity planning of large scalable apps.
Capacity is based upon max utilization. A scaled web app is does not have constant utilization. The parent I was responding to suggested running on one large/face instance. Ok... if you're capacity planning, are you planning for peak rps or min rps? Obviously peak. Peak times are always a fraction of your total server uptime. This means one big/fast server would be underutilized most of the time.
How do you expect to dynamically vertically scale in cloud to fit demand while using a single server? Re-provision another server (either smaller or larger), redeploy all apps to the server, and then route traffic? Great, you're doing kubernetes job by hand.
Having a system in place that handles most of this gracefully (like kubernetes) is one way of having such a plan, there are others. Which one works best is dependent on your app, cost of downtime, your team that's tasked with bringing everything back up in the middle if the night, etc.
People who leave details like this out when they say "kubernetes is complicated" just haven't seen the complexities of operating a service well.
> the complexities of operating a service well.
Keep in mind that in a lot of business applications, downtime isn't the end of the world and might be an accepted and priced-in "cost" of doing business. Operating it as you consider "well" would just cost them more with no benefit.
You can also rent a whole server. There's not much difference in time in managing a VM in a cloud or a whole server you rent from someone. Depending on the vendor, maybe some more setup time, since low end hosts don't usually have great setup workflows, so maybe you need to fiddle with the ipmi console once or twice to get it started, but if you go with a higher tier provider, you can fully automate everything if that floats your boat. It's just bare metal rather than a VM, and typically much lower cost for sustained usage (if you're really scaling up signfigantly and down throughout the day, cloud costs can work out less, although some vendors offer bare metal by the hour, too)
"The components that we included in the tax classification are: protocol buffer management, remote procedure calls (RPCs), hashing, compression, memory allocation and data movement."
https://static.googleusercontent.com/media/research.google.c...
However, I think the author critically under-guesses the sizes of things (even just for storage) by a reasonably substantial amount. e.g.: Quote tweets do not go against the size limit of the tweet field at Twitter. Likely they are embedding a tweet reference in some manner or other in place of the text of the quoted tweet itself but regardless a tweet takes up more than 280 unicode characters.
Also, nowhere in the article are hashtags mentioned. For a system like this to work you need some indexing of hashtags so you aren't doing a full scan of the entire tweet text of every tweet anytime someone decides to search for #YOLO. The system as proposed is missing a highly critical feature of the platform it purports to emulate. I have no insider knowledge but I suspect that index is maybe the second largest thing on disk on the entire platform, apart from the tweets themselves.
Hashtags are a search feature and basically need the same posting lists as for search, but if you only support hashtags the posting lists are smaller. I already have an estimate saying probably search wouldn't fit. But I think hashtag-only search might fit, mainly because my impression is people doing hashtag searches are a small fraction of traffic nowadays so the main cost is disk, not sure though.
I did run the post by 5 ex-Twitter engineers and none of them said any of my estimates were super wrong, mainly just brought up additional features and things I didn't discuss (which I edited into the post before publishing). Still possible that they just didn't divulge or didn't know some number they knew that I estimated very wrong.
Another poster dug into some implementation details that I'm not going to go into. I think you could shoehorn it into an extremely large server alongside the rest of your project but then you're looking at processing overhead and capacity management around the indexes themselves starting to become a more substantial part of processing power. Consider that for each tweet you need to break out what hashtags are in it, create records, update indexes, and many times there's several hashtags in a given tweet.
When I last ran analytics on the firehose data (ca. 2015/16) I saw something like 20% of all tweets had 3 or more hashtags. I only remember this fact because I built a demo around doing that kind of analytics. That may have changed over time obviously, however without that kind of information we don't have a good guesstimate even of what storage and index management there looks like. I'd be curious if the former Twitter engineers you polled worked on the data storage side of things. Coming at it from the other end of things, I've met more than a few application engineers who genuinely have no clue how much work a DBA (or equivalent) does to get things stored and indexed well and responsively.
While some of those writes may well be acceptable to lose, letting you write to caches, effectively you need to assume there are more analytics events triggering writes to something than there are tweet views.
What I mean is, Twitter seems to be processing data based on whatever it is in the tweet and doesn't maintain some grand coherent database.
So I changed my Twitter handle and opened a new account with my original Twitter handle and to my surprise, I was receiving notifications of engagement with tweets my old account sent previously.
I also heard that a method for spamming Twitter trending topics is to send tweets and delete them quickly.
My impression is that Twitter is big on real time processing. They definitely don't search the entire database for #YOLO tweets, instead they seem to be searching the almost-live stuff and some archived stuff(probably ranked and saved as noteworthy tweets or something).
While true, and not to take away from the parent comment, I've noticed that the size of things is often partially the result of scaling out horizontally. Most companies I've worked at end up with a lot of duplicate records as each subsystem might want a copy or to cache a copy.
It's often fine to start without a fully decoupled system (net present value of the time and money needed to scale out might be far too high), but you need to know whether or not it's likely to come and what to look for so you can start preparing in time.
When interviewing developers I always ask them what is the largest public web site they ever worked on and then probe about performance issues they encountered and how they resolved them in order gague how far along they are in their skill development.
I would never plan to run a production service on a single server just because coordinating changes in the active dataset among two or more production servers often changes your design significantly, and you want to plan for that because the consumer grade hardware we all use has a nasty habit of not working after power cycles (which still tends to be the most strain a system goes through, even in a world of SSD storage).
Adding images, videos, other large attachments, rich search, and all the advertising and billing and analytics stuff would blow this out of the water, but... maybe not by as much as people think...? I would not be surprised if a very performance-engineered version of Twitter could run on a few dozen racks full of beefy machines like this with HPC-grade super-fast fabric interconnects.
I have a strong sense that most large scale systems are way less efficient than what's possible. They trade development ease, modularity, and velocity for performance by using a lot of microservices, flabby but easy and flexible protocols (e.g. JSON over HTTP), slow dynamic languages, and layers of abstraction that could be integrated a lot more tightly.
Of course that may be a rational trade-off if velocity, flexibility, and labor costs and logistics matter more than hardware, power, or data center floor space costs.
I didn't get the impression that this would duplicate the entire functionality of Twitter, just what amounts to the MVP functionality. If you are only talking about the MVP it's at least somewhat plausible with a lot of careful engineering and highly efficient data manipulation.
Yes, this would be big enough to need specifically factoring into a real implementation design. But it would not be big enough to invalidate the proposed idea so I understand leaving it off, at least initially, to simplify the thought experiment.
Similarly to support a message responding to, or quoting, a single other you only need one or two NULLable ID references, 16 bytes per message, which will likely be dwarfed by the message text in the average case. Given it likely makes sense to use something like SQL Server's compression options for data like this the average load imposed will be much smaller than 16 bytes/message.
We are fiddling, fairly insignificantly, measurable but to massively, with constants a & b in O(a+bN) here, so the storage problem is still essentially of order O(N) [where N is total length of the stored messages].
I'd probably go as far to say that the indexes _generally_ at twitter could be larger than the tweets
The data structures for the @BeefWellington timeline of tweets and the one for the #BeefWellington timeline of tweets could look roughly the same.
I really wonder how much of a challenge this is and how much it occupies, not even talking about disk, but continuing the theoretical exercise in the linked URL, you can get 1U size servers with 2TB of RAM these days.
Text search, hashtag index, some structured data for popular tweets, etc...
In order to deliver search results I would not be surprised if tweets are duplicated/denormalized, for quick search/lookup.
I want to add another concept that may impact, considerably, the storage, which is "threads". I'm not sure what is the percentage of threads/tweets but what I consider an important factor is that threads do not have a maximum number of characters.
> There’s a bunch of other basic features of Twitter like user timelines, DMs, likes and replies to a tweet, which I’m not investigating because I’m guessing they won’t be the bottlenecks.
Each of these can, in fact, become their own bottlenecks. Likes in particular are tricky because they change the nature of the tweet struct (at least in the manner OP has implemented it) from WORM to write-many, read-many, and once you do that, locking (even with futexes or fast atomics) becomes the constraining performance factor. Even with atomic increment instructions and a multi-threaded process model, many concurrent requests for the same piece of mutable data will begin to resemble serial accesses - and while your threads are waiting for their turn to increment the like counter by 1, traffic is piling up behind them in your network queues, which causes your throughput to plummet and your latency to skyrocket.
OP also overly focuses on throughput in his benchmarks, IMO. I'd be interested to see the p50/p99 latency of the requests graphed against throughput - as you approach the throughput limit of an RPC system, average and tail latency begin to increase sharply. Clients are going to have timeout thresholds, and if you can't serve the vast majority of traffic in under that threshold consistently (while accounting for the traffic patterns of viral tweets I mentioned above) then you're going to create your own thundering herd - except you won't have other machines to offload the traffic to.
You add another feature and it requires a little bit more RAM, and another feature that needs a little bit more, and.. eventually it doesn't all fit.
Now you have to go distributed.
And your entire system architecture and all your development approaches are built around the assumptions of locality and cache line optimization and all of a sudden none of that matters any more.
Or you accept that there's a hard ceiling on what your system will ever be able to do.
This is like building a video game that pushes a specific generation of console hardware to its limit - fantastic! You got it to do realtime shadows and 100 simultaneous NPCs on screen! But when the level designer asks if they can have water in one level you have to say 'no', there's no room to add screenspace reflections, the console can't handle that as well. And that's just a compromise you have to make, and ship the game with the best set of features you can cram into that specific hardware.
You certainly could build server applications that way. But it feels like there's something fundamental to how service businesses operate that pushes away from that kind of hyperoptimized model.
Back in the 486 days you wouldn't be keeping, in RAM, data about every single human on earth (let's take "every single human on earth" as the maximum number of humans we'll offer our services to with on our hypothetical server). Nowadays keeping in RAM, say, the GPS coordinates of every single human on earth (if we had a mean to fetch the data) is doable. On my desktop. In RAM.
I still don't know what the implications are.
But I can keep the coordinates of every single humans on earth in my desktop's RAM.
Let that sink in.
P.S: no need to nitpick if it's actually doable on my desktop today. That's not the point. If it's not doable today, it'll be doable tomorrow.
>It is amusing to consider how much of the world you could serve something like Twitter to from a single beefy server if it really was just shuffling tweet sized buffers to network offload cards. Smart clients instead of web pages could make a very large difference. [1]
Very interesting to see the idea worked out in more detail.
[1] https://twitter.com/id_aa_carmack/status/1350672098029694998
Except that's not what it is doing at all.
It assembles all the Tweets internally, applies an ML model to produce a finalised response to the user.
I strongly doubt that entire datacenters need to be used if and only if Twitter obsessively optimized for hardware usage efficiency over everything else. In reality they don't and make some pretty big compromises to actually get stuff built. Hardware is cheap, people are not.
There are storage size issues (like how big is their long tail; quite large I'd imagine), but its a fun thing to think about.
HTTP with connection: keep-open can serve 100k req/sec. But that's for one client being served repeatedly over 1 connection. And this is the inflated number that's published in webserver benchmark tests.
For more practical down to earth test, you need to measure performance w/o keep-alive. Request per second will drop to 12k / sec then.
And that's for HTTP without encryption or ssl handshake. Use HTTPS and watch it fall down to only 400 req / sec under load test [ without connection: keep-alive ].
That's what I observer.
Why do we want to apply ML at the cost of a significant fleet cost increase? Because it can make the overall system consistently perform against external changes via generalization, thus the system can evolve more cheaply. Why do we want to implement a complex logging layer although it doesn't bring direct gains on system performance? Because you need to inspect the system to understand its behavior and find out where it needs to change. The list can go on and I can give you hundreds of reasons why we need all these apparently unnecessary complexities and overheads can be important for systems' longevity.
I don't deny the existence of accidental complexities (probably Twitter can become 2~3x simpler and cheaper given sufficient eng resource and time), but in many cases you probably won't be able to confidently say if some overheads are accidental or essential since system engineering is essentially a highly predictive/speculative activity. To make this happen, you gotta have a precise understanding of how the system "currently works" to make a good bet rather than re-imagination of the system with your own wish list of how the system "should work". There's a certain value on the latter option, but it's usually more constructive to build an alternative rather than complaining about the existing system. This post is great since the author actually tried to build something to prove its possibility, this knowledge could turn out to be valuable for other Twitter alternatives later on.
You can even run Linux on them now. The specs he cites would actually be fairly small for a mainframe, which can reach up to 40TB of memory.
I'm not saying this is a good idea, but it seems better than what the OP proposes.
No, it doesn’t. It’s a fun exercise in approaching Twitter as an academic exercise. It ignores all of the real-world functionality that makes it a business rather than a toy.
A lot of complicated businesses are easy to prototype out if you discard all requirements other than the core feature. In the real world, more engineering work often goes to ancillary features that you never see as an end user.
This is not apples to apples but Whatsapp is a product that entirely ran on 16 servers at the time of acquisition (1.5 billion users). It really begs the question why Twitter uses so much compute if there are companies that have operated significantly more efficiently. Twitter was unprofitable during acquisition and spent around half their revenue on compute, maybe some of these features were not really necessary (but were just burning money)?
I see a lot of comments here assuming that this proves something about Twitter being inefficient. Before you jump to conclusions, take a look at the author’s code: https://github.com/trishume/twitterperf
Notably absent are things like serving HTTP, not to even mention HTTPS. This was a fun exercise in algorithms, I/O, and benchmarking. It wasn’t actually imitating anything that resembles actual Twitter or even a usable website.
I'm now somewhat confident I could implement this if I tried, but it would take many years, the prototype and math is to check whether there's anything that would stop me if I tried and be a fun blog post about what systems are capable of.
I've worked on a team building a system to handle millions of messages per second per machine, and spending weeks doing math and building performance prototypes like this is exactly what we did before we built it for real.
Of course. I was commenting here to counter all of the comments declaring that this proves Twitter doesn’t need all of their servers, etc.
It’s a fun article, but the comments here interpreting it as proving something about Twitter engineers being bad are kind of depressing.
There was an article just yesterday about how Jane Street had developed an internal exchange way faster than any actual exchange by building it from the ground up, thinking about how the hardware works and how agents can interact with it.
Modern software like Slack or Twitter are just reinventing what IRC or BBS did in the past, and those were much leaner, more reliable and snappier than their modern counterparts, even if they didn't run at the same scale.
It wouldn't be surprising at all that you could build something equivalent to Twitter on just one beefy machine, maybe two for redundancy.
> Once you understand your computer has 16 cores running at 3GHz and yet doesn't boot up in .2 nanoseconds you understand everything they have taken from you.
With their infinite VC money at their disposal, and with their programmers having 100 GHz machines with thousands of cores, 128 TB of RAM and FTL internet connections, tech companies don't really have any incentive to actually reduce bloat.
Edit: it's still quite sad. I feel like we had languages with a way better future, and more promising programming architectures, back in the 80s.
The blog post kind of gets a very cut-down version of Twitter running on a single machine. Actual Twitter absolutely would not work.
https://gist.github.com/jboner/2841832
Essentially IO is expensive except within a datacenter but even in a data center, you can do a lot of loop iterations in a hot loop in the time it takes to ask a server for something.
There is a whitepaper which talks about the raw throughput and performance of single core systems outperforming scalable systems. These should be required reading of those developing distributed systems.
http://www.frankmcsherry.org/assets/COST.pdf A summary: http://dsrg.pdos.csail.mit.edu/2016/06/26/scalability-cost/
How much RAM did your advertising network need? Becuase that is what makes twitter a business! How are you building your advertiser profiles? Where are you accounting for fast roll out of a Snapchat/Instagram/BeReal/Tiktok equivalent? Oh look, your 140 characters just turned into a few hundreds megs of video that you're going to transcode 16 different ways for Qos. Ruh Roh!
How are your 1,000 engineers going to push their code to production on one machine?
Almost always the answer to "do more work" or "buy more machines" is "buy more machines".
All I'm saying is I'd change it to "Toy twitter on one machine" not Production.
> How are your 1,000 engineers going to push their code to production on one machine?
That might actually be the reason why Twitter barely keeps afloat. 1k engineers for a product that's already built and hasn't fundamentally changed nor evolved in years makes me wonder what business value those engineers actually provide.
If you have a 1 KB piece of data that you need to send to a customer, ideally that should require less than 1 KB of actual NIC traffic thanks to HTTP compression.
If processing that 1 KB takes more than 1 KB of total NIC traffic within and out of your data centre, the you have some level of amplification.
Now, for writes, this is often unavoidable because redundancy is pretty much mandatory for availability. Whenever there's a transaction, an amplification factor of 2-3x is assumed for replication, mirroring, or whatever.
For reads, good indexing and data structures within a few large boxes (like in the article) can reduce the amplification to just 2-3x as well. The request will likely need to go through a load balancer of some sort, which amplifies it, but that's it.
So if you need to process, say, 10 Gbps of egress traffic, you need a total of something like 30 Gbps at least, but 50 Gbps for availability and handling of peaks.
What happens in places like Twitter is that they go crazy with the microservices. Every service, every load balancer, every firewall, proxy, envoy, NAT, firewall, and gateway adds to the multiplication factor. Typical Kubernetes or similar setups will have a minimum NIC data amplification of 10x on top of the 2-3x required for replication.
Now multiply that by the crazy inefficient JSON-based protocols, the GraphQL, an the other insanity layered on to "modern" development practices.
This is how you end up serving 10 Gbps of egress traffic with terabits of internal communications. This is how Twitter apparently "needs" 24 million vCPUs to host text chat.
Oh, sorry... text chat with the occasional postage-stamp-sized, potato quality static JPG image.
Feel free to continue using that (historically-correct) answer in interviews. :P
Edit: Still a nice writeup!
They are knowledgeable to a certain level but they simply aren't great engineers who almost always are humble, cautious, thoughtful and respectful of the intentions behind what other engineers build.
Anyone who thinks they can jump in and replace any tech stack without an extensive deep dive of the business requirements, design decisions, cost constraints, resource limitations etc that drove the choices deserves the pain and unemployment that inevitably follows.
Isn't this exactly what modern key value stores like RocksDB, LMDB etc are built for?
Like last time, and the time before that, and the time before that, and the time before that.
I understand the frustration with flavor of the week "best practices" and the constant churn of frameworks and ideas, but software engineering as a practice IS moving forward. The difficulty is separating the good ideas (CI/CD, for example) from the trends (TDD all the things all the time) ahead of time.
> I did all my calculations for this project using Calca (which is great although buggy, laggy and unmaintained. I might switch to Soulver) and I’ll be including all calculations as snippets from my calculation notebook.
I've always wanted an {open source, stable, unit-aware} version of something like this which could be run locally or in the browser (with persistence on a server). I have yet to find one. This would be a massive help to anyone who does systems design.
So IMO it's perfectly possible to run Java applications without containers. You would need to think about network ports, about resource limits, but those are not hard things.
And tomcat even provides zero-downtime upgrades, although it's not that easy to set up, but when it works, it does work.
After I've got some experience with Kubernetes, I'd reach for it always because it's very simple and easy to use. But that requires to go through some learning curve, for sure.
The best and unbeatable thing about containers is that there're plenty of ready ones. I have no idea how would I install postgres without apt. I guess I could download binaries (where?), put them somewhere, read docs, craft config file with data dir pointing to anotherwere and so on. That should be doable but that's time. I can docker run it in seconds and that's saved time. Another example is ingress-nginx + cert-manager. It would take hours if not days from me to craft set of scripts and configs to replicate thing which is available almost out of the box in k8s, well tested and just works.
I've seen something similar in projects previously, it never worked all that well.
While the idea of shipping one archive with everything is pretty good, people don't want to include the full JDK and Tomcat installs with each software delivery, unlike with containers, where you get some benefit out of layer re-use when they haven't changed, while having the confidence that what you tested is what you'll ship. Shipping 100 app versions with the same JDK + Tomcat version will mean reused layers instead of 100 copies in the archives. And if you don't ship everything together, but merely suggest that release X should run on JDK version Y, the possibility of someone not following those instructions at least once approaches 100% with every next release.
Furthermore, Tomcat typically will need custom configuration for the app server, as well as configuration for the actual apps. This means that you'd need to store the configuration in a bunch of separate files and then apply (copy) it on top of the newly delivered version. But you can't really do that directly, so you'd need to use something like Meld to compare whether the newly shipped default configuration doesn't include something that your old custom configuration doesn't (e.g. something new in web.xml or server.xml). The same applies to something like cacerts within your JDK install, if you haven't bothered to set up custom files separately.
Worse yet, if people aren't really disciplined about all of this, you'll end up with configuration drift over time - where your dev environment will have configuration A, your test environment will have configuration B (which will sort of be like A), and staging or prod will have something else. You'll be able to ignore some of those differences until everything will go horribly wrong one day, or maybe you'll get degraded performance but without a clear reason for it.
> So IMO it's perfectly possible to run Java applications without containers. You would need to think about network ports, about resource limits, but those are not hard things.
This is only viable/easy/not brittle when you have self-contained .jar files, which admittedly are pretty nice! Though if shipping JDK with each delivery isn't in the cards (for example, because of the space considerations), that's not safe either - I've seen performance degrade 10x because of a JDK patch release was different between two environments, all because of JDK being managed through the system packages.
Resource limits are generally doable, though Xms and Xmx lie to you, you'd need systemd slices or an equivalent for hard resource limits, which I haven't seen anyone seriously bother with, although they're at a risk of the entire server/VM becoming unresponsive should their process go rogue for whatever reason (e.g. CPU at 100%, which is arguably worse than OOM because of bad memory limits).
Ports are okay when you are actually in control of the software and nothing is hardcoded. Then again, another aspect is being able to run multiple versions of software at the same time (e.g. different MySQL/MariaDB releases for different services/projects on the same node), which most nix distributions are pretty bad at.
> And tomcat even provides zero-downtime upgrades, although it's not that easy to set up, but when it works, it does work.
I've seen this attempted, but it never worked properly - the codebases might not have been good, but those redeployments and integrating with Tomcat always lead to either memory leaks or odd cases of the app server breaking. That's why personally I actually enjoy the approach of killing the entire thing alongside the app and doing a restart (especially good with embedded Tomcat/Jetty/Undertow), using health checks for routing traffic instead.
I think doing these things at the app server level is generally just asking for headaches, though the idea of being able to do so is nice. Then again, I don't see servers like Payara (like GlassFish) in use anymore, so I guess Spring Boot with embedded Tomcat largely won, in combination with other tools.
> After I've got some experience with Kubernetes, I'd reach for it always because it's very simple and easy to use. But that requires to go through some learning curve, for sure.
I wouldn't claim that Kubernetes is simple if you need to run your own clusters, though projects like K3s, K0s and MicroK8s are admittedly pretty close.
> The best and unbeatable thing about containers is that there're plenty of ready ones. I have no idea how would I install postgres without apt. I guess I could download binaries (where?), put them somewhere, read docs, craft config file with data dir pointing to anotherwere and so on. That should be doable but that's time. I can docker run it in seconds and that's saved time. Another example is ingress-nginx + cert-manager. It would take hours if not days from me to craft set of scripts and configs to replicate thing which is available almost out of the box in k8s, well tested and just works.
This is definitely a benefit!
Though for my personal needs, I build most (funnily enough, excluding databases, but that's mostly because I'm lazy) of my own containers from a common Ubuntu base. Because of layer reuse, I don't even need tricks like copying files directly, but can use the OS package manager (though clean up package cache afterwards) and pretty approachable configuration methods: https://blog.kronis.dev/articles/using-ubuntu-as-the-base-fo...
In addition, my ingress is just a containerized instance of Apache running on my nodes, with Docker Swarm instead of Kubernetes: https://blog.kronis.dev/tutorials/how-and-why-to-use-apache-... In my case, the distinction between the web server running inside of a container and outside of a container is minimal, with the exception that Docker takes care of service discovery for me, which is delightfully simple.
I won't say that the ingress abstraction in Kubernetes isn't nice, though you can occasionally run into configurations which aren't as easy as they should be: e.g. configuring Apache/Nginx/Caddy/Traefik certs which has numerous tutorials and examples online vs trying to feed your wildcard TLS cert into a Traefik ingress, with all of the configuration so that your K3s cluster would use it as the default certificate for the apps you want to expose. Not that other ingresses aren't great (e.g. Nginx), it's just that you're buying into additional complexity and I've personally have also had cases where removing and re-adding it hangs because of some resource cleanup in Kubernetes failing to complete.
I guess what I'm saying is that it's nice to use containers for whatever the strong parts are (for example, the bit about being able to run things easily), though ideally without ending up with an abstraction that might eventually become leaky (e.g. using lots of Helm charts that have lots of complexity hiding under the hood). Just this week I had CI deploys starting to randomly fail because some of the cluster's certificates had expired and kubectl connections wouldn't work. A restart of the cluster systemd services helped make everything rotate, but that's another thing to think about, which otherwise wouldn't be a concern.
You’d also have to quantify the improved user experience from seeing less spam v.s. inflated ad revenue for garbage views / content.
They were targeting 315 mDAUs for Q4 2023, but in the final earnings it was only 238 mDAUs. Actual MAU stats weren't public iirc but some random stats sites seemed to say 450m global MAUs, which likely includes people with no ad preferences or who only view NSFW content (which can't be shown next to (most?) ads).
https://www.forbes.com/sites/johnkoetsier/2022/11/14/twitter...
b) No one has said Twitter operates entire data centres.
c) You need more than just NICs and ML accelerators to built a Twitter timeline. You need to rank the content, determine appropriate ads and combine them together. You can't do that in your network card.
They do though. 3 in the US alone (https://www.datacenterdynamics.com/en/news/report-elon-musk-...).
Twitter operates a handful of datacenters because their scale is such that it makes sense.
Also, the big data storage isn't text, it's images and videos.
Whats app is not an applicable comparison because messages and videos are stored on the client device. Better to look at Pinterest and snap, which spend a lot on infra as well.
The issue is storage, ads, and ML to name a few. For example, from 2015:
“ Our Hadoop filesystems host over 300PB of data on tens of thousands of servers. We scale HDFS by federating multiple namespaces.”
You can also see their hardware usage broken down by service as put in their blog.
https://blog.twitter.com/engineering/en_us/topics/infrastruc...
https://blog.twitter.com/engineering/en_us/a/2015/hadoop-fil....
- 450m DAUs at the time of facebook acquisition [0]
- Twitter is not just DMs or Group Chat.
> It really begs the question why Twitter uses so much compute if there are companies that have operated significantly more efficiently.
A fair comparision might have been Instagram: While Systrom did run a relatively lean eng org, they never had to monetize and got acquired before they got any bigger than ~50m?
[0] https://www.sequoiacap.com/article/four-numbers-that-explain...
Twitter, while still not profitable (maybe it was in some recent quarters?) was much closer to it, having all the components necessary to form a reasonable ad business. For ads, analytics is critical, plus all the ad serving, plus it’s a totally different scale of compute being many to many rather than one to ~one.
> This is not apples to apples but Whatsapp
And yeah, whatsapp isn't even close to an apt comparison. It's a completely different business model with vastly different engineering requirements.
Is Twitter bloated? Perhaps, but it's probably driven by business reasons, not (just) because engineers just wanted to make a bunch of toys and promo projects (though this obviously always plays some role).
In terms of what Twitter uses compute on, I'd guess analytics (Twitter measures "everything" for ad serving - go explore ads.twitter.com and analytics.twitter.com) and non-chronological timeline mixing both takes orders of magnitude more resources than the basic functionality.
1. Lots of batch jobs. Sometimes it's unclear how much value they produce / whether they're still used.
2. Twitter probably made a mistake early on in taking a fanout-on-write approach to populate feeds. This is super expensive and necessitates a lot of additional infrastructure. There is a good video about it here: https://www.youtube.com/watch?v=WEgCjwyXvwc
WhatsApp is mostly a bent pipe connecting user devices & relying on device storage. If WhatsApp had to implement Twitter functionality and business model (with same Engineers and stack), they'd need a lot more servers too. I'd hazard the number of servers would be in the same order of magnitude
I don’t know enough about Twitter to assess their infrastructure, but I know that it easy to run lean until there’s a problem, and then you get trapped.
Erlang is particularly well-suited to building distributed systems because it was designed to handle failures at the process level rather than the hardware level. This means that if one part of a distributed system built with Erlang fails, the rest of the system can continue to operate without interruption.
This is critical for a messaging platform like WhatsApp, which needs to be able to handle millions of users sending messages simultaneously without experiencing any downtime. Additionally, Erlang's concurrency features allow it to support many thousands of simultaneous connections on a single machine, which is also important for a messaging platform that needs to be able to handle a large volume of traffic.
"I also didn’t try to investigate configuring an IBM mainframe, which stands a chance of being the one type of “machine” where you might be able to attach enough storage to fit historical images."
It seems theoretically possible it could accomodate the entirety of Twitter in 'one machine'.
There was a HPC cluster at Princeton when I worked there (which, looking at their website, has since been retired) that was assembled by SGI and outfitted with a customized Linux unikernel that presented itself as a single OS image, despite being comprised several disparate racks of individual 2-4u servers. You might be able to metaphorically duct-tape enough machines together with a similar technique to be able to run the author's pared-down scope within a single OS image.
With respect to the IBM z-series specifically - if the goal of the exercise is to save money on hardware costs, I'm imagining purchasing an IBM mainframe is in direct opposition to that goal. :) I'm not familiar enough with its capabilities to say one way or the other.
Because OP is a junior developer, he reads a lot of theory and blog posts, does a lot of research, but doesn't have much practical experience. Just look at his resume and what he wrote. As a result, most of what he write about is based on what he have read about senior developers doing in the companies he have worked for, perhaps he created some supporting software for core services but did not design or implemented the core, so he doesn't have firsthand experience. This is evident to anyone who has actually used DPDK (which is ridiculous proposal for Twitter like service in 2023 where you have XDP and io_uring, it's not HFT), designed and implemented high volume, low latency web services and knows where the bottleneck is in that kind of services from experience, theory will not give you that intuition and knowledge.
Vertical scaling was absolutely the way most big applications were built up until well into the 90s. Companies like Oracle were really built on the fact that getting performance and reliability out of a single highly-contested massive server is hard but important if that's the way you're going. Linux became dominant primarily because horizontal scaling won that argument and it won it pretty much exactly because of:
1)what you said - you hit a hard cap on how big you can make your main server at which point you are really screwed. Scalability pain points become a hard wall.
2) when I say "server" I mean "servers" of course because you'd need an H/A failover, at which point you've eaten the cost of replication, handling failover etc and you may as well distribute
3) cost. Because hardware cost vs capability is exponential, as your requirements become bigger you pretty rapidly hit a point where lots of commodity hardware becomes cheaper for a given performance point than few big servers
So there's a reason that distributed systems on commodity hardware became the dominant architectural paradigm. It's not the only way to do it, but it's a reasonable default for many use cases. For a very high-throughput system like twitter it seems a very obvious choice.
Clearly there are costs to distribution, so if you can get away with a simpler architecture then as always Occam's razor applies. Also if you can easily distribute later then it probably makes sense to leave that option open and explore it when you need it rather than overcomplicate too early.
I’m always reminded of how stackoverflow essentially runs off a single database server. If they can do it, most web properties can do it.
It's a similar phenomenon to the observation that tech "innovations" tend to recapitulate research that had its roots in the 50-60-70s.
"The industry" doesn't seem to put much stock in generational knowledge transfer.
Indeed, with the hyperoptimized version here, the moment you tip over into two machines each machine will need two copies of every tweet from anyone who has followers sharded to both machines, so the capacity of two machines is going to be far less than twice the capacity of one as a large proportion of tweets will cause writes on both shards. This inefficiency will now always be with you - the average number of writes per user per tweet will go up until your number of shards approaches average follower counts.
This is why it's common to model this with fan-out on write, because the moment you accept that there is a risk you'll tip over into a sharded model you need to account for that. If asked the question of such a design, it's worth pointing out that if you can guarantee it fits on one machine, and this is true for many more problems than people expect, then you can save a lot, but then I'd set out the more complex model and contrast it to the single-machine model.
You don't need to fan-out to every account even in such a distributed system, certainly. You can fan-out to every shard/instance, and keeping that cached in RAM would still allow you to be far more efficient than e.g. Mastodon (which does fan-out to every instance for the actual post data, but relies on a Postgres database)
That "fundamental" thing is the cultural expectation that SaaS offerings constantly grow in features, rather than in reliability or performance. As your example from the world of video games demonstrates, there is no industry-wide belief that things must be able to do ever-more, forever. It's really mostly SaaS and desktop software that has this weird and unreasonable culture around it. That's why your word processor can now send emails, and your email provider now does translations as well.
Data growth through user growth or just normal day-to-day usage is expected.
Of course they could fit a much larger dataset on one machine today.
(But I will note the article is also assuming a chronological timeline by default, but that of course hasn't been true for years - the ranking Twitter does now is far more complex)
Edit: Unless I missed something, the author never argued that Twitter should be hosted on one machine and therefore criticizing the “fun stunt” like this makes no sense to me
I did not looked into source code yet but I suppose that OP if not implemented already than there should ideas for implementation.
In addition: from my POV implementation of scaling for such service should be trivial: - sharding of data between instances by a criteria (e.g. regional) or by hash - configure network routing
I think it should work
It’s interesting to see how much can be done with a single machine, because most projects will never be this big.
Though there will still be other concerns like redundancy to deal with.
It's not sarcasm, I have twitter account but I never understood hype about twitter.
I see nothing in twitter from technical POW, closed twitter protocol looks very strange, they banned Trump, they were profitable in 2021, Elon Musk bought them for ~44 bln.
Maybe sellout of company with problems for such price is success.
From scanning every message of every person, it's going to expand to recognizing every face from every camera, and transcribing and analyzing every spoken word recorded.
It was a little more than ten years ago for me. I realized that a hard disk could store a database of every human alive, including basic information, links (family relations) and maybe a photo.
I still don't know what the implications are.
Maybe we don't want to know, but it's not really that difficult to think about.
Which is already largely true today with the advent of serverless. Most maintenance work can center around application logic rather than scaling physical machines/maintaining versioning.
It's clear that many modern applications would take an order of magnitude more people to run even just 20 years ago. That trend will only continue
That's getting to the point you could store 20 bytes per atom in a terabyte.
(The big bottleneck is that you need picosecond resolution simulation steps and to cover minutes to see a protein fold.)
I'm talking about a hypothetical HTTPS server that used optimized kernel-bypass networking. Here's a kernel-bypass HTTP server benchmarked doing 50k new connections per core second while re-using nginx code: https://github.com/F-Stack/f-stack. But I don't know of anyone who's done something similar with HTTPS support.
One thing which we noticed was that there was a considerable difference in performance characteristics based on how we parallelized the load testing tool (multiple threads, multiple processes, multiple kubernetes pods, pods forced to be distributed across nodes).
I think that when you run non-distrubuted load tests you benefit from bunch of cool things which happen with http2 and Linux (multiplexing, resource sharing etc) which might make applications seem much faster than they would be in the real world.
"Quant uses the warpcore zero-copy userspace UDP/IP stack, which in addition to running on on top of the standard Socket API has support for the netmap fast packet I/O framework, as well as the Particle and RIOT IoT stacks. Quant hence supports traditional POSIX platforms (Linux, MacOS, FreeBSD, etc.) as well as embedded systems."
I'm running about 2000 requests/s in one of my real-world production systems. All of the requests are without keep-alive and use TLS. They use about one core for TLS and HTTP processing.
Sure, you need to invest into it but those are things you can reuse for every app and feature you build.
And those are not the reason why those systems are so complex, those are just ways to keep complex systems running and manageable. In most they also do not stand in the way of making system better but help in it.
They need to exist because the architecture of system grew organically from smaller system over and over again and big restructurization was deemed not worth it. It's "just have a bunch more hardware and engineers" vs "we're not delivering features and we might not get rewrite right".
And every time you throw money at the problem the problem becomes a bigger problem and potential benefits from "getting it right" are also getting bigger. But nobody wants to be herald that tells management "we 're going to spend 6-12 months" for somethinkg that have few years of pay-off
I also bet that mainframes have software solutions to a lot of the multi-tenancy and fault tolerance challenges with running systems on one machine that I mention.
You would be surprised. First off, SSDs are denser than hard drives now if you're willing to spend $$$.
Second, "plug in" doesn't necessarily mean "in the chassis". You can expand storage with external disk arrays in all sorts of ways. Everything from external PCI-e cages to SAS disk arrays, fibre channel, NVMe-over-Ethernet, etc...
It's fairly easy to get several petabytes of fast storage directly managed by one box. The only limit is the total usable PCIe bandwidth of the CPUs, which for a current-gen EPYC 9004 series processors in a dual-socket configuration is something crazy like 512 GB/s. This vastly exceeds typical NIC speeds. You'd have to balance available bandwidth between multiple 400 Gbps NICs and disks to be able to saturate the system.
People really overestimate the data volume put out by a service like Twitter while simultaneously underestimating the bandwidth capability of a single server.
I think every big internet service uses user-space networking where required, so that part isn't new.
Netapp is at something > 300TB storage per node IIRC, but in any case it would make more sense to use some cloud service. AWS EFS and S3 don't have any (practically reachable) limit in size.
Some commodity machines use external SAS to connect to more disk boxes. IMHO, there's not a real reason to keep images and tweets on the same server if you're going to need an external disk box anyway. Rather than getting a 4u server with a lot of disks and a 4u additional disk box, you may as well get 4u servers with a lot of disks each, use one for tweets and the other for images. Anyway, images are fairly easy to scale horizontally, there's not much simplicity gained by having them all in one host, like there is for tweets.
Of course it's a proof-of-concept, it's not a drop-in replacement for Twitter.
It needs to assemble tweets internally, sort them with an ML model, add in relevant ads and present a single response to the user because end-user latency matters.
And each of these systems eg. ads has their own features, complexities, development lifecycle and scaling requirements. And of course deploying them continuously without downtime. That is how you end up with disparate services and a lot of them for redundancy reasons.
I know you think you’re smarter than everyone at Twitter. But those who really know what they are doing have a lot more respect for the engineers who built this insanity. There are always good intentions.
You ignored one possibility - that twitter engineers, or people managing them might be just incompetent and all of that might just be overly complex POS
There is that weird disgusting trend to assume just because company got big that means the tech choices were immaculate, and not everything else there is to successful companies.
You can make perfectly well doing company on totally mediocre product that hit the niche at right time
I think that this may make sense for some applications, but I also think that if you can utilize software abstractions to improve developer efficiency, it reduces risk in the long run.
[1] https://en.wikipedia.org/wiki/P4_(programming_language)
[2] https://www.intel.com/content/www/us/en/products/network-io/...
I agree with you specialists are expensive but even a team of software engineers runs into the multi million dollar territory.
Why not spend the same amount AND cut down resource use? Hyperscalers have shifted to custom hardware already.
[1] https://github.com/fiberhood/MorphleLogic/blob/main/README_M...
[1] Flexible Content-based Publish/Subscribe over Programmable Data Planes https://pure.rug.nl/ws/files/206093441/Flexible_Content_base...
$$$$$$ income on $$$ costs
$$$ income on $ costsRunning anything on a single server, however, is really a non starter for anything remotely serious. What do you do if you need to do an OS update? I suppose you could just never do those, like a former employer (1000+ day uptimes...)
You'd definitely need at least two servers. But I think you could surely just have simple master/slave replication and switch between them.
Source: https://foreignpolicy.com/2009/06/16/state-department-interv...
You absolutely would not. The cost of having developers put out extremely optimized code (due to the scaling limits) and cuddle that single server to never, ever fail easily eclipses the cost of a having a multiple servers by a few orders of magnitude.
EDIT: To the downvoters, I'd really love to see the calculation on how engineering time would be cheaper than buying a second server in any reasonable timeframe.
(You are right, servers are cheap compared to employee costs though.)
With a second OS partition, the server can alternate between the working copy and a copy that is updated in a VM. For a free service, customers cannot complain even if there is a reboot every day and the service is down for a couple of minutes.
Realistically, there would be a mirroring server to be prepared for hardware failures. One server can be restarted while the other is the main server.
Are you seriously suggesting that a service (the size of Twitter, no less) has an acceptable downtime of a few minutes a day?
> Realistically, there would be a mirroring server to be prepared for hardware failures. One server can be restarted while the other is the main server.
But for that mirroring, you need to replicate disk writes, databases, backups etc.. This additional load would easily bring the server to a point where a single server would no longer suffice, even an insanely spec'ed one.
Everyone has to be employed so it's better to keep adding more crap to products and make those products disposable in order to give people a job.
It’s like me running a web crawler on my phone and saying I can replace Google.
The hard part is in being able to translate a search query into a list of pages.
And that requires a level of sophistication that far exceeds a laptop.
I sometimes wonder how much value ML provides vs a proper sort function for anything but advertising.
Do you think that the most successful web companies in the world with arguably the best people i.e. Amazon, Facebook, Instagram, TikTok, LinkedIn, Pinterest, Youtube, Netflix, Snapchat etc. have no idea what they are doing. That the highly complex, expensive and latency impacting recommendation systems could be replaced by trivial sorting.
Or maybe they do work, do translate to increased usage and do significantly impact revenue.
Would it be better to live in a world where Twitter (for example) existed because it is a useful thing and not because it might make lots of money?
It's not just ads, it means the set of people you follow becomes extremely critical for your experience in a way that makes it far less engaging.
That may be good or bad for you as a user depending on what you want, but for Twitter having most people stick to the ML augmented timeline is essential to keep you hooked.
When you come back to build the new version of your game on the next gen console sure you can now add all those features but the processing pipelines are different now and the disk performance and memory to cache ratios have changed - getting your hyper optimized code to work in the new platform takes a ton of effort - so you either run it in some kind of emulation mode, sacrificing some of the performance for productivity, or you rewrite it.
Same happens with new generations of server hardware. Your clever hack to maximize NUMA locality of data to each core becomes a liability when the next hardware gen comes out and on-die caches are bigger. Decisions about what should use RAM get invalidated by faster SSDs.
Maybe you can build a service this way - hardware first. Pick a server platform for a couple of years; build to that capacity; ship; then start designing the next gen service to run on a new set of hardware?
To some extent this is how database or virtualization systems software is written. And if I’m not mistaken Twitter actually did develop their own database stack to optimally handle their particular data storage model, and I assume that was done pretty close to the metal.
*Some engineers may disagree
As a current undergrad, you can also look to your professors for this (especially those with industry experience before they went into teaching).
After graduation, this may mean working at a company _with_ those older engineers, as opposed to a 5-20 person startup with a homogeneous group of 20-somethings.
And the thing is that what was a bad idea in 2000 might now be an idea whose time has come, because the surrounding context has changed - be it browser technology or the size of machine memory or the capabilities of programming languages.
So, like, when I point out that kubernetes is just DCOM all over again I’m not actually dismissing kubernetes (just because we don’t use DCOM any more doesn’t mean it wasn’t a good choice then); less still suggesting that we should go back to using DCOM; I’m just saying ‘maybe there are some lessons we can learn from how people used DCOM back in the day about what cases kubernetes is suited for and what the pitfalls might be’. And, also, maybe raising the possibility that in a few years time we will look back at kubernetes as a bloated outdated approach and be glad to see the back of it - even though right now it might be a great technology to use.
But I’m not sure how a new junior dev can possibly pick up all that nuance from just listening to old farts like me talking about how this reminds us of how we used to do things back in the old days.
Forcing yourself to use barebones languages and environments is good too. Hacking on ancient machines or targeting embedded hardware is another good way to get a better intuition on the order of magnitude performance differences of various approaches.
Reading about promising tech of the past is also useful: prolog, Smalltalk, etc. Lots of inspiring and fruitful lessons to mine there.
https://blog.twitter.com/engineering/en_us/topics/infrastruc...
https://ankush-chavan.medium.com/twitter-data-storage-and-pr...
Nope. It's not Tweets that generate that data. It's the insane amount of (mostly unnecessary) noise that gets thrown into the mix: analytics, logs, metrics, you name it.
Every time you scroll Twitter sends multiple events to the server. That alone will generate a large chunk of those petabytes.
Many things can plausibly fit on a single machine irrespective of uptake (e.g. I worked on a system not long ago where even if we cornered the entire global market and the market expanded several magnitudes in size, our entire working set would still fit comfortable in memory).
But even when you need to scale, it absolutely can scale better if you're willing to not automatically resort to a standard database stack for everything for example.
In the particular case, your coworker would be stored by some identifier (like an SSN or similar) and their name would be stored as "aliases" and allow multiple names. I have two nicknames that I answer to, depending on when in my life you met me, and my family calls me by my proper name. Online, I go by several handles depending on whether I want the reader to be able to figure out my real name. I even used to work somewhere where I was called by this handle (withinboredom) more than my real name.
Not for someone that works in consulting, or at least it wasn't. I remember that I had Access access to the production database that stored all the customers, present and pass. They wouldn't give me a password to that, but apparently they thought it was safe to enter the password without me looking so I could try some queries and test my last fixes.
Not sure if it still works the same, but I did some dumb query, left the computer on and, next day morning, a temporal file was in my %TEMP% with a lot of data of millions of persons worldwide. Had I be so inclined, with an external hard disk I could have started my homegrown NSA project.
Now think of this: how many times have you heard that the data of millions of customers were on sale after a data breach? Do you doubt that, let's say, China has every single person in the West on file?
Our own governments have us legally or semi-legally (exchange) anyway.
Plus you can group together people in the same area and/or sort positions as integers and store only the deltas between them, so you can probably get down to 2-3 bytes per person.
And you can get dozens of models of smartphone with 16GB of RAM right now. So there might be a gap there but it's a very small gap. The phone of tomorrow will have the RAM.
Edit: Thinking about it more, with 2^33 people and 2^47 locations the average delta would be 2^14, and it's pretty easy to guarantee that fits into 2 bytes per person. And with a more accurate world population count you'd free up at least a gigabyte for your phone to actually operate with.
Judging by that, you need a negligible increase in the number of locations you can represent to handle everywhere stable and off the ground someone could be. Much less than one bit per person.
If you want to deal with people currently in airplanes then you could give them an extra couple bytes. It's less than a million people so it won't affect your total storage at all.
And in places you care (multi-floor buildings) you aren't getting GPS signal inside anyway...
I have a basic LAMP server running on a 4-core VM on a laptop. I just threw ApacheBench at it (not the fastest benchmarking tool, either -- it eats up 1 core all by itself), and it handles 1200 req/s TLS with no keepalive, and 3400 req/s with keepalive. This stuff scales linearly with core count, so I wouldn't be surprised to see much higher numbers in real servers.
Because both are ridiculously slow to the point where they would be completely unusable for a service such as Twitter whose current latency is based off everything largely being in memory.
And Twitter already evaluated using the cloud for their core services and it was cost-prohibitive compared to on-premise.
I don't have enough experience to say whether having the entirety of Twitter sit in one really big metal box would be perceived to be sufficiently advantageous or not.
It's outright comical. Above we have people thinking somehow amount of TLS connections single server can handle is a problem, in service where there would be hundreds of thousands lines of code to generate the content served over it, all while using numbers from what seems like 10+ years old server hardware
- spam detection: I agree this is a reasonably core feature and a good point. I think you could fit something here but you'd have to architect your entire spam detection approach around being able to fit, which is a pretty tricky constraint and probably would make it perform worse than a less constrained solution. Similar to ML timelines.
- ad relevance: Not a core feature if your costs are low enough. But see the ML estimates for how much throughput A100s have at dot producting ML embeddings.
- web previews: I'd do this by making it the client's responsibility. You'd lose trustworthiness though so users with hacked clients could make troll web previews, they can already do that for a site they control, but not a general site.
- blocks/mutes: Not a concern for the main timeline other than when using ML, when looking at replies will need to fetch blocks/mutes and filter. Whether this costs too much depends on how frequently people look at replies.
I'm fully aware that real Twitter has bajillions of features that I don't investigate, and you couldn't fit all of them on one machine. Many of them make up such a small fraction of load that you could still fit them. Others do indeed pose challenges, but ones similar to features I'd already discussed.
in a cluster, communication isn't real-time. packets drop, fetches fail, clocks skew, machines reboot.
IPC is a gray area. the remote process might die, its threads might be preempted, etc. RTOSes make IPC work more like a single machine, while regular OSes make IPC more like a network call.
so to me, the datacenter-as-mainframe idea falls apart because you need massive amounts of software infrastructure to treat a cluster like a mainframe. you have to use Paxos or Raft for serializing operations, you have to shard data and handle failures, etc. etc.
but it's definitely getting closer, thanks to lots of distributed systems engineering.
- vendor lock-in: anyone who has worked at a shop running Sun SPARC machines when they got purchased by Oracle can speak to the pain involved with negotiating software licenses or hardware support contracts with the Only Game In Town.
- the price/scarcity of mainframe talent: you're going to have to pry IBM z-series experts away from banks who are paying 50-100% over market rate, oftentimes in straight cash, to maintain systems that are propping up the United States economy in its entirety. Not to mention - my first job out of college >10 years ago had a mainframe, and I was incredulous that _anyone_ still had or needed one in the 21st century. Now I can appreciate the specific tradeoffs being made that caused the business to choose a mainframe, but attracting top-tier cost-effective junior dev talent out of college becomes several orders of magnitude more difficult once the word "mainframe" leaves your recruiters' lips.
- scalability: in the event that you ever decide to add features or functionality (or, say, increase your tweet character limit by an order of magnitude), you have now committed yourself to scaling your systems in units of mainframes costing millions per unit, as opposed to servers costing five figures per unit (not to mention, you probably need a dev environment that's airgapped from your prod environment, which means yet _another_ mainframe...)
- build vs. buy: using the same commodity x86_64/ARM hardware and Linux kernel that everyone else is using allows you to take advantage of all of the open-source datacenter software being built for that happy-path profile. The minute you stray from that path, the engineering-hour cost of everything you do has the potential to skyrocket, because you can't use anything off-the-shelf and need to recompile everything for z/Architecture. In fact, based on some cursory web searches, it doesn't appear that you can compile the Rust toolchain to even _run_ on z/OS as of today, so at minimum, OP would be committing to implementing that.
But at the end of the day, the constraining resource in every software organization I've encountered has been engineering hours, and by choosing a mainframe you're drastically limiting the potential number of engineering hours available to you in the employee market.
Whether or not removing several intermediary layers of abstraction, and the commensurate 100x (?) boost in efficiency, between users tweeting a hashtag and the actual electrons vibrating, is worth taking on the significant constraints you've enumerated.
Ethernet is fast, you might be able to get in range of DRAM access with an RDMA setup. cache coherency would require some kind of crazy locking, but maybe you could do it with FPGAs attached to the RDMA controllers that implement something like Raft?
it'd be kind of pointless and crash the second any machine in the cluster dies, but kind of a cool idea.
it'd be fun to see what Task Manager would make of it if you could get it to last long enough to boot Windows.
My joke fantasy startup is a cloud provider called one.computer where you just have a slider for the number of cores on your single instance, and it gives you a standard linux system that appears to have 10k cores. Most multithreaded software would absolutely trash the cache-coherency protocols and have poor performance, but it might be useful to easily turn embarrassingly parallel threaded map-reduces into multi-machine ones.
It's relatively easy to have it work slowly (reducing clocks to have a period higher than max latency), but becomes very hard to do at higher freqs.
Beowulf clusters can get you there to some extent, although you can always do better with specialized hardware and software (by then you're building a supercomputer...)
We have Zen4c 128 Core with DDR5 now. We might get a 256 Core Zen6c with PCI-E 6.0 and DDR6 by 2026.
I really like these exercise of trying to shrink the amount of server needed, especially those on Web usage. And the mention of Mainframe. Which dont get enough credit for. I did something similar with Netflix 800Gbps's post. [1] Where they could serve every single user with less than 50 Racks by the end of this decade.
[0] https://www.liqid.com/products/liqid-elements/liqid-48-port-...
https://www.supermicro.com/en/pressreleases/supermicro-unlea...
Is an infiniband switch connected to a bunch of machines that expose NVMe targets really that different from a SAS expander connected to a bunch of JBOD enclosures? Only difference is that the former can scale beyond 256 drives per controller and fill an entire data center. You're still doing all the compute on one machine so I think it still counts.
Personally I wouldn't run a critical service on only one server, but two servers? Definitely doable. I actually have a service running on two servers in different DCs 700 miles apart. Zero downtime in 9 years. :)
We kinda know the answer to this: Twitter was struggling with harm to its reputation for a long time because of regular Fail Whales. It absolutely was a huge problem for them at the time.
Who needs Twitter to be a service without any downtime?
Tweets alone generate petabytes of data a year.
https://ankush-chavan.medium.com/twitter-data-storage-and-pr...
Also, many people would disagree that stuff required to run a business is "mostly unnecessary".
This was all already derived (correctly) in the original post. Recapitulating:
500m tweets/day * (conservatively) 512B/tweet * 365 days/yr ~= 90 TiB/yr
Assuming compression and variable-length encoding of this long tail in colder storage, it's more likely <20 TiB/yr (<=115B/tweet on average)
Yes, this excludes analytics metadata, which as you suggest would not support Twitter's current ad products. But your core repeated claim about tweets alone is two orders of magnitude off.
I wonder if the "Petabytes" figure being claimed includes pictures/videos that can be attached to a Tweet. In that case, I could easily see "Petabytes/year" be accurate.
Actually a good example of how difficult the problem is. A very common attack is to switch a bit.ly link or something like that to a malicious destination. You would also DoS the hosts... as the Mastodon folks are discovering (https://www.jwz.org/blog/2022/11/mastodon-stampede/)
For blocks/mutes, you have to account for retweets and quotes, it's just not a fun problem.
Shipping the product is much more difficult that what's in your post. It's not realistic at all, but it is fun to think about.
"Our approach to blocking links" https://help.twitter.com/en/safety-and-security/phishing-spa...
"The Infrastructure Behind Twitter: Scale" https://blog.twitter.com/engineering/en_us/topics/infrastruc...
"Mux" https://twitter.github.io/finagle/guide/Protocols.html#mux
I do agree that some of this could be done better a decade later (like, using Rust for some things instead of Scala), but it was all considered. A single machine is a fun thing to think about, but not close to realistic. CPU time was not usually the concern in designing these systems.
---
"Federation" now apparently means "DDoS yourself." Every time I do a new blog post, within a second I have over a thousand simultaneous hits of that URL on my web server from unique IPs. Load goes over 100, and mariadb stops responding.
The server is basically unusable for 30 to 60 seconds until the stampede of Mastodons slows down.
Presumably each of those IPs is an instance, none of which share any caching infrastructure with each other, and this problem is going to scale with my number of followers (followers' instances).
This system is not a good system.
Update: Blocking the Mastodon user agent is a workaround for the DDoS. "(Mastodon|http\.rb)/". The side effect is that people on Mastodon who see links to my posts no longer get link previews, just the URL.
---
I personally find this absolutely hilarious. Is that blog hosted on a Raspberry Pi or something? "Over a thousand" requests per second shouldn't even show up on the utilization graphs on a modern server. The comments suggest that he's hitting the database for every request instead of caching GET responses, but even with such a weird config a normal machine should be able to do over 10k/second without breaking a sweat.
From what I remember "hard" limits are CPU/DRAM-memory initialization and speed of read from flash chip storing, and sources of lag include firmware from add-on cards just being slow (if RAID controller takes 30 seconds to return, and firmware is not running initialization in parallel, that's your extra boot time. Or stuff out of left field like "IPMI controller logs stuff via serial so if you print too much text it slows down". Most BIOSes do things painfully parallel too.
Here's one I ran into recently: if a range has only 1 of 3 replicas online then it will stop accepting traffic for that range until it has 3 replicas again.
(for the folks at home, "range" is a technical term for 512 bit slice of the data - CRDB replicates at the range level)
So, in some code I wrote, I had account for not only 1) the whole DB being unavailable but also 2) just one replica being unavailable (they're different failure modes that say different things about the health of the system).
It's a good behavior! Good for durability. But I had to do some work to deal with it, spend an hour coming up with a solution, etc. There are databases that work at Twitter scale but no there are no silver bullets among those that do. You need full time engineers to manage the complexity and keep it online, or else it could cost the company shitloads of money - I've seen websites of similar scale where a two-hour outage cost them $20 million.
In fact it’s often meant to distract from the lack of progress.
It’s not the lack of progress that is the concern, it’s the subterfuge.
Mastodon is written on Ruby on Rails. That should really answer all your questions about the problem but if you're unfamiliar Ruby is slow compared to any compiled language, Rails is slow compared to near-every framework on the planet and it isn't written that well either.
280 * 4 = 1120, not 560.
Side note, this is more pessimistic than it needs to be, if you're willing to transcode. The larger codepoints fit into 20-21 bits, and the smaller ones fit into 12-13 bits.
They wrote Finagle which is a very well written and highly regarded Scala micro-service framework that is used by other companies such as LinkedIn, Soundcloud etc. Likewise Pelikan is an excellent caching service.
We know that Scala is a proven, high-performance, type-safe language that is optimised for concurrency and stability. So it's not like their tech stack is written in Ruby and needs to be re-written in Rust or Go. It's already performant.
Any machine that can do that will be a similar spec to what you need for serving queries. Not as fast as google does it, but a good amount of them.
It's akin to saying the magic behind OpenGPT is the dataset.
The comparable goal to the article is to be a search engine, not to fight google for best results.
If it counted UTF-16 code units that would be dumb. It doesn't. The cutoff was deliberately set to keep the 140 character limit for CJK but increase it to 280 for the rest. And they did that based on observational data.
https://cdn.cms-twdigitalassets.com/content/dam/blog-twitter...
https://blog.twitter.com/en_us/topics/product/2017/Giving-yo...
George Hotz, is that you ?
Hotz was trying to make a car controller that had never been done before, by himself, and then he wanted to """improve""" search with no explanation of what that meant that I saw.
I think if he was tasked with taking twitter from no search to "has a search" he probably could have managed it. A team of five people definitely could have managed it.
{kind=link}
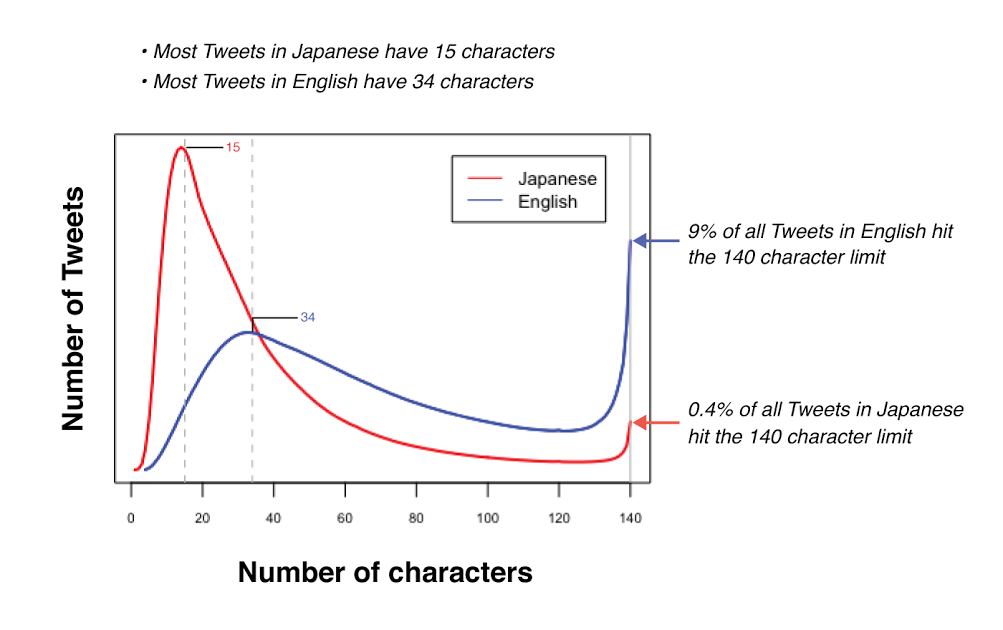{kind=link}