A visual book recommender(nathanrooy.github.io) |
A visual book recommender(nathanrooy.github.io) |
https://static.nomic.ai/pubmed.html
running on their deepscatter visualization engine:
https://github.com/nomic-ai/deepscatter
that keeps things dynamic for rendering
Which is a map of all authors in the world sorted by overlap in readership. I found some of my favorite writers by browsing it.
I wonder which approach is better suited to find something that is spot on to my interests.
When I think of my favorite books, they usually are the most popular books of their authors.
Are there any counterexamples, where an author wrote a book that is more profound than their biggest hit but got overlooked for some reason?
That said, I do think book-level might be much more valuable. My first thought for this was Night in the Lonesome October by Roger Zelazny. I haven't read anything else by him yet because my brother informs me his other stuff is entirely different. Looking at Goodreads, I think that qualifies as far from his biggest hit. Is it "more profound?"? Doubtful, but seems likely that you shouldn't group it with his others. I want recommendations based on the book I like, not the author I mostly might-not.
A better example might be how Stephenie Meyer wrote the extremely popular Twilight books, and also The Host which is much less well-known, and better in many respects. Probably qualifies as more profound, too—it's told from the perspective of a parasitic alien. Picture the Yeerks from Animorphs if you read those.)
Weird though that for certain cases it spells English author names with Cyrillic alphabet. Like for instance when I center the graph on "Stanisław Lem", I can see names like George Orwell or Terry Pratchett spelled in Cyrillic. I wonder why.
Any reply is going to be somewhat subjective, but All Systems Red is not even in my top 5 books by Martha Wells...
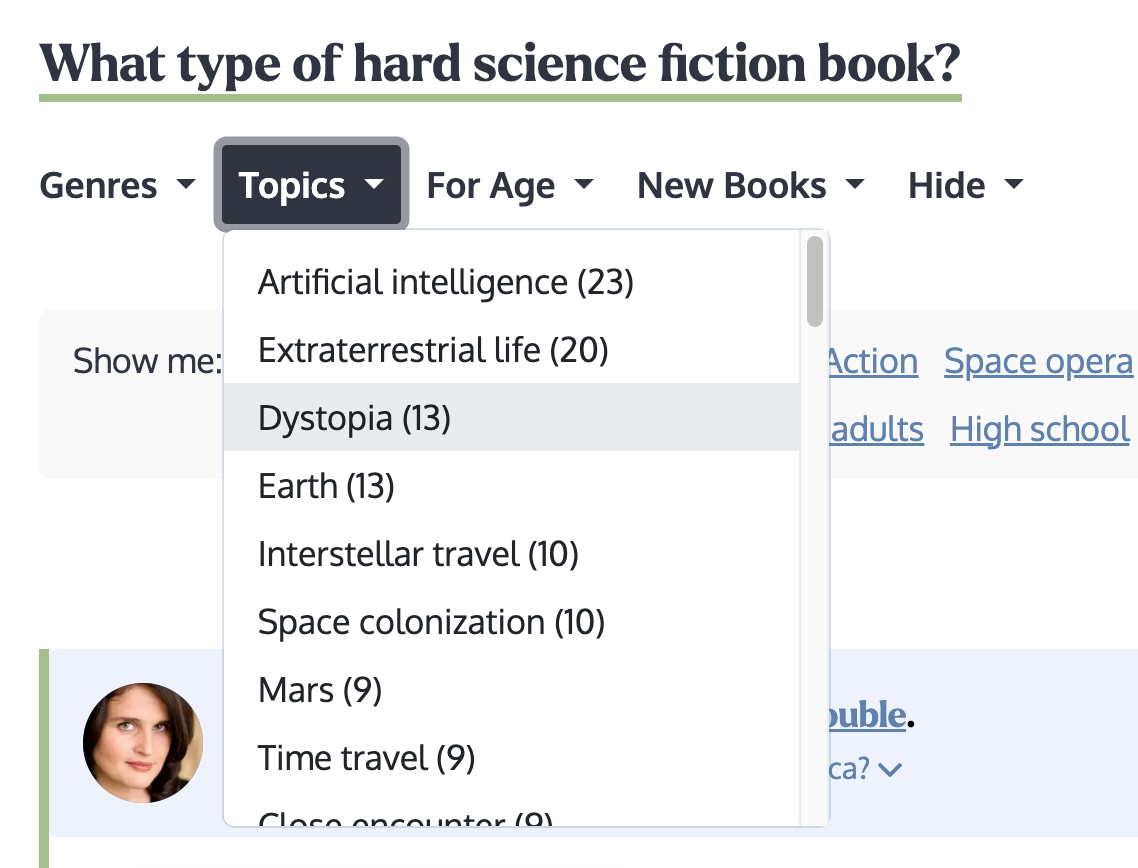
I am about a week away from launching genre pages, age pages, and filters for all those things. So on the hard-science-fiction page, you can filter to see books in a variety of fun ways and keep following your curiosity:
Image showing how it works: https://substackcdn.com/image/fetch/f_auto,q_auto:good,fl_pr...
Hit me up at ben@shepherd.com if you want to try the early preview, just tell me your fav genre and ill send you a link.
> 1. The King James Bible
Spot on! Bookmarked!
It feels like what Pinterest would be without the annoying bits.
It explains why I couldn't find anything like it.
Also very explanatory the fact the Tolkien's The Two Towers is right by its side, because I also love that book.
And now I'm already downloading the other "outliers" close to Pandora's Star.
Additional authors you might enjoy are Neal Asher, Iain M. Banks, Alistair Reynolds, and Jack McDevitt.
But nothing like the first book, although the two are actually a single book sold separately, at least for me.
I just read a neighbor of Pandora's Star in the graph (Coyote) and enjoyed it. Note quite like pandora, but fine.
https://camjohnson26.github.io/author-graph/science/
https://github.com/CamJohnson26/author-graph
Clearly needs a lot of data clean up but still was very helpful for discovering important scientists and their approximate relative impact
There's probably a graph theory phenomena that describes what I'm thinking.
Within our data books like lord of the rings and harry potter are nearly impossible to map for "books like" because they are connected to so many other things. I am working now to fine tune our model, but it has been an interesting challenge.
Basically just prune the top and bottom %1 of weighted edges to get an appropriate average. Would be my guess for a fix.
Not sure if that's a good idea. It shrinks the set of genuine readers and overweights the set of professional spammers.
Also it would be super cool if we could import out goodreads reading lists and see them on the cluster
Dropping you an email in a few hours :)
I was really hoping this would address "Visual Book" like in ふしぎの海のナディア, Fushigi no Umi no Nadia/The Secret of Blue Water. The LaserDiscs used to say "Visual Book" in every episode.
Great animated series (to me), a mix of 20,000 Leagues Under the Sea and the Illuminati.
Do NOT watch it with the english subs. Suffer with the Japanese, even if You don't speak it. You don't need the junk verbal translation, You will still get the main concepts. And Hanson's driving is so much more manaical in Japanese.
I also used more crude algorithms that sort by X, group elements in buckets, and within each, sort by Y. Then we get a grid of elements. The result is less high-quality than with iterative algorithms (and depends on if we sort by X or Y first), but it is hard to beat its simplicity.
I wish the accompanying article was longer. I can't fully grasp how it was done because I don't know enough about the concepts mentioned.
Reminds me a lot of some of the stuff I used to work on at Steam Labs: https://store.steampowered.com/labs
{kind=link}