Intel definitely seems to be doing all the right things on software support.
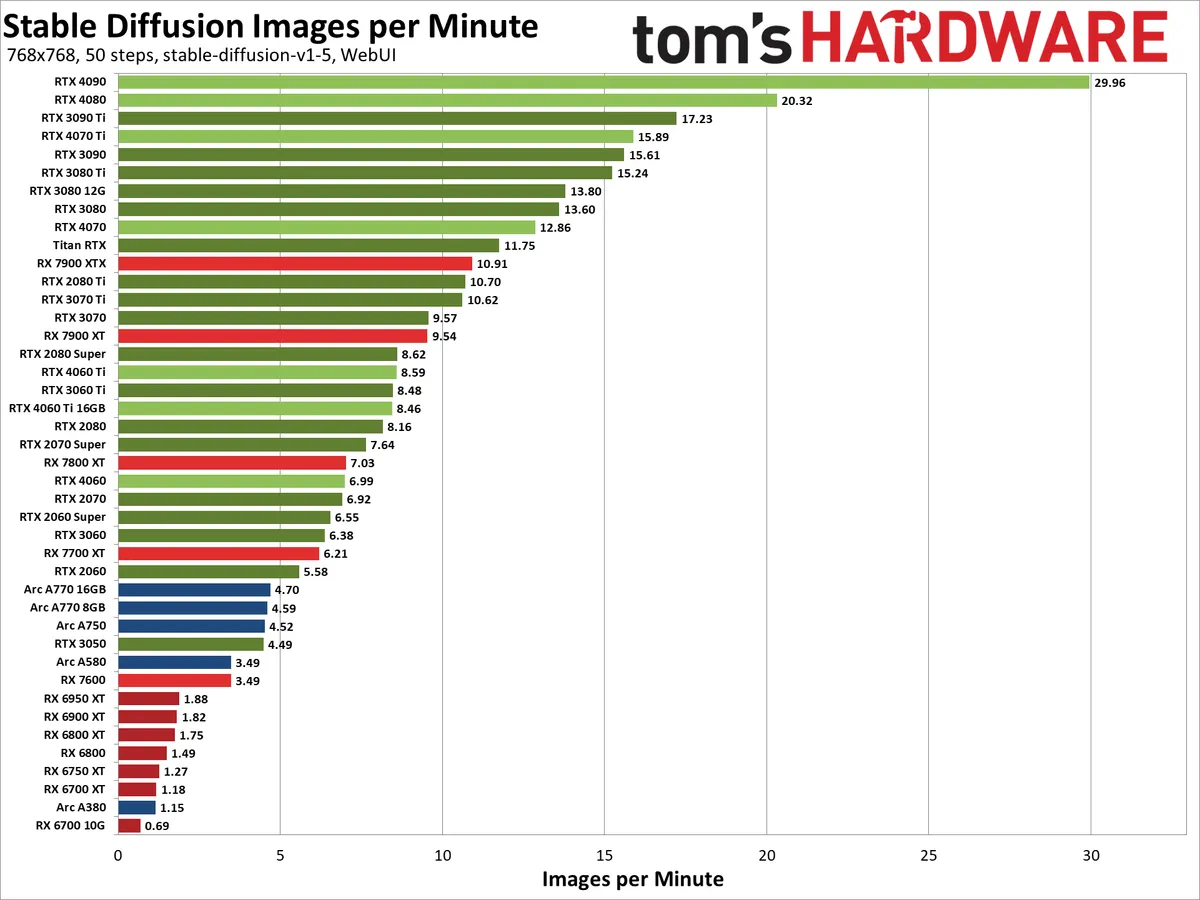
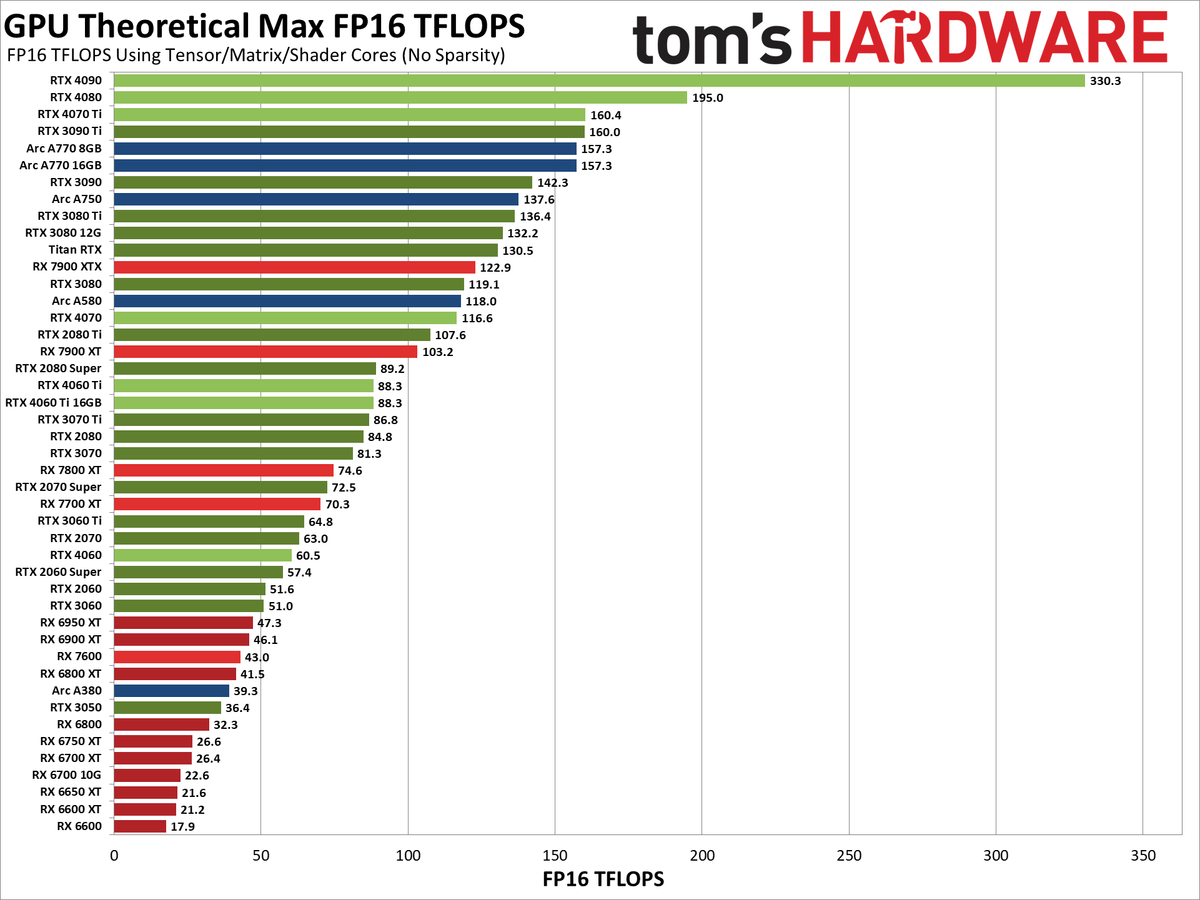
This is a huge problem because in theory the Arc A770 is faster! It's theoretical performance (TFLOPS) is more than twice as fast as an Nvidia 4060 (see: https://cdn.mos.cms.futurecdn.net/Q7WgNxqfgyjCJ5kk8apUQE-120... ). So why does it perform so poorly? Because everything AI-related has been developed and optimized to run on Nvidia's CUDA.
Mostly, this is a mindshare issue. If Intel offered a workstation GPU (i.e. not a ridiculously expensive "enterprise" monster) that developers could use that had something like 32GB or 64GB of VRAM it would sell! They'd sell zillions of them! In fact, I'd wager that they'd be so popular it'd be hard for consumers to even get their hands on one because it would sell out everywhere.
It doesn't even need to be the fastest card. It just needs to offer more VRAM than the competition. Right now, if you want to do things like training or video generation the lack of VRAM is a bigger bottleneck than the speed of the GPU. How does Intel not see this‽ They have the power to step up and take over a huge section of the market but instead they're just copying (poorly) what everyone else is doing.
Intel, screw everything else, just pack as much VRAM in those as you can. Build it and they will come.
It will be a niche product with poor sales.
Which I don't care too much about.
However, even 16->24GB is a big step, since a lot of the model are developed for 3090/4090-class hardware. 36GB would place it lose to the class of the fancy 40GB data center cards.
If Intel decided to push VRAM, it will definitely have a market. Critically, a lot of folks will also be incentivized to make software compatible, since it will be the cheapest way to run models.
I heard some Asrock motherboard BIOSes could set the VRAM up to 64GB on Ryzen5.
Doing some investigations with different AMD hardware atm.
The serious crypto and AI nuts are all using custom hardware. Crypto moved onto ASICs for anything power-efficient, and Nvidia's DGX systems aren't being cannibalized from the gaming market.
Seems like we just need consumer matrix math cards with literally no video out, and then a different set of requirements for those with a video out.
But then those pesky researchers and hackers figured out how to use the matmul hardware for non-gaming.
Right now, the best discriminator they have is that PC users are willing to put up with much smaller amounts of VRAM.
Can you elaborate on this? Intel's reputation for software support hasn't been stellar, what's changed?
You can pick them up in prebuilds from Dell and Supermicro: https://www.supermicro.com/en/accelerators/intel
Read more about them here: https://www.servethehome.com/intel-shows-gpu-max-1550-perfor...
- SYCL [1]
- Vulkan
- OpenCL
I don't own the hardware, but I imagine SYCL is more performant for ARC , because it's the one intel is pushing for their datacenter stuff
[1]: https://www.intel.com/content/www/us/en/developer/articles/t...
16GB RAM and performance around a 4060ti or so, but for 65% of the price
Ryzen5 has both CPU+GPU on one chip, the BIOS allows you set the amount of VRAM. They share the same RAM bank, you can set 16GB of VRAM and 16GB for the OS if you use a 32GB RAM bank.
The same thing would make a lot of sense here. Super-fast memory close, with overflow into classic DDR slots.
As a footnote, going parallel also helps. 8 sticks of RAM at 1/8 the bandwidth each is the same as one stick of RAM at 8x the bandwidth, if you don't multiplex onto the same traces.
Point of fact: GPUs don't even use all the PCI Express lanes they have available to them! Most GPUs (even top of the line ones like Nvidia's 4090) only use about 8 lanes of bandwidth. This is why some newer GPUs are being offered with M.2 slots so you can add an SSD (https://press.asus.com/news/asus-dual-geforce-rtx-4060-ti-ss... ).
The issue is that GPUs are massively parallel. A 4090 has 128 streaming multiprocessors, each executing 128 "threads" or "lanes" in parallel. If each "thread" works on a different part of memory that leaves you with 1kB of L1 cache per thread, and 4.5kB of L2 cache each. For each clock cycle you might be issuing thousands of request to your memory controller for cache misses and prefetching. That's why you want insanely fast RAM.
You can write CUDA code that directly accesses your host memory as a layer beyond that, but usually you want to transfer that data in bigger chunks. You probably could make a card that adds DDR4 slots as an additional level of hierarchy. It's the kind of weird stuff Intel might do (the Phi had some interesting memory layout ideas).
Nvidia's approach to software certainly deserves scrutiny, but their hardware lineup is so robust that I find it hard to complain. Jetson already exists for low-wattage solutions, and gaming cards can run Nvidia datacenter drivers on headless Linux without issue. The consumer compute cards are already here, you just aren't using them.
But capital doesn't want to invest in competition when it can instead invest in a chance at a moat that allows charging monopoly rents.
For all their hardware research hiccups in the last 10 years, they've been delivering on open source machine learning libraries.
It's apparently the same on driver improvements and gaming GPU features in the last year.
Right now, I have a nice NVidia card, but if things stay on track, I think it's very likely my next GPU might be Intel. Open-source, not to mention better value.
I want a consumer card that can do some number of tokens per second. I do not need a monster that can serve as the basis for a startup.
The hobbyist market needs something priced well under $1k to make it accessible.
If a model takes twice as long to run.... I'll live. Worst-case, it will be mildly annoying.
If I can't run a model, that's a critical failure.
There's a huge step up CPU->GPU which I need, but 3060 versus 4090 isn't a big deal at all. Indeed, the 24GB versus 16GB is a bigger difference than the number of CUDA cores.
512 GB.
It was slower than conventional DRAM.
But for AI models, Optane may have an advantage: it's bit-addressable.
I'm not aware of any memory controllers that exposed that single-bit granularity; Optane was fighting to create a niche for itself, between DRAM and NAND Flash: pretending to be both, when it was neither.
Bit-level operations, computational units in the same device as massive storage, is an architecture that has yet to be developed.
AI GPUs try to be such an architecture by plopping 16GB of HBM next to a sea of little dot-product engines.
That's an advantage over NAND but not over DRAM. Fundamentally, DRAM is also bit-addressable, but everybody uses DRAM parts with memory cells organized into a hierarchy of groupings for reasons that mostly apply to 3D XPoint memory.
While the 4090 can run models that use less than 24GB of memory at blistering speeds, models are going to continue to scale up and 24GB is fairly limiting. Because LLM inference can take advantage of splitting the layers among multiple GPUs, high memory GPUs that aren't super expensive are desirable.
To share a personal perspective, I have a desktop with a 3090 and an M1 Max Studio with 64GB of memory. I use the M1 for local LLMs because I can use up to 57~GB of memory, even though the output (in terms of tok/s) is much slower than ones I can fit on a 3090.
I would gladly buy a card that ran a touch slower but had massive Vram, especially if it was affordable, but I guess that puts me into that camp of enthusiasts you mentioned.
>24GB is fairly limiting
Can I take a moment to suggest that maybe we're very spoiled?
24GB of VRAM is more than most peoples' system RAM, and that is "fairly limiting"?
To think Bill once said 640KB would be enough.
The fact is large language models require a lot of VRAM, and the more interesting ones need more than 24GB to run.
The people who are able to afford systems with more than 24GB VRAM will go buy hardware that gives them that, and when GPU vendors release products with insufficient VRAM they limit their market.
I mean inequality is definitely increasing at a worrying rate these days, but let's keep the discussion on topic...
But selling to machine learning enthusiasts is not a bad place to be. A lot of these enthusiasts are going to go on to work at places that are deploying enterprise AI at scale. Right now, almost all of their experience is CUDA and they're likely to recommend hardware they're familiar with. By making consumer Intel GPUs attractive to ML enthusiasts, Intel would make their enterprise GPUs much more interesting for enterprise.
It doesnt need to be consumer grade, it doesnt need to be ultra high either.
It needs to be cheap enough for my department to expensive it via petty cash.
It doesn't even matter if that's your primary goal or not.
Frustrated AMD customers willing to put their money where their mouth is?
>4090
These are noob hardware. A6000 is my choice.
Which really only further emphesizes your point.
>CPU based is a waste of everyone's time/effort
>GPU based is 100% limited by VRAM, and is what you are realistically going to use.
It's not like they don't have a monopoly on pre-installed OSes.
If Intel sells a stackable kit with a lot of RAM and a reasonable interconnect a lot of corporate customers will buy. It doesn't even have to be that good, just half way between PCIe 5.0 and NVLink.
But it seems they are still too stuck in their old ways. I wouldn't count on them waking up. Nor AMD. It's sad.
i learned my RAM lesson when I bought my first real linux PC. it had 4MB of RAM, which was enough to run X, bash, xterm, and emacs. But once I ran all that and also wanted to compile with g++, it would start swapping, which in the days of slow hard drives, was death to productivity.
I spent $200 to double to 8MB, and then another $200 to double to 16MB, and then finally, $200 to max out the RAM on my machine-- 32MB! And once I did that everything flew.
Rather than attempting to solve the problem by making emacs (eight megs and constantly swapping) use less RAM, or find a way to hack without X, I deployed money to max out my machine (which was practical, but not realistically available to me unless I gave up other things in life for the short term). Not only was I more productive, I used that time to work on other engineering problems which helped build my career, while also learning an important lesson about swapping/paging.
People demand RAM and what was not practically available is often available 2 years later as standard. Seems like a great approach to me, especially if you don't have enough smart engineers to work around problems like that (see "How would you sort 4M integers in 2M of RAM?")
Thank you. Now I feel a log better for dropping $700 on the 32MB of RAM when I built my first rig.
It is possible that compressing and using all of human knowledge takes a lot of memory and in some cases the accuracy is more important than reducing memory usage.
For example [1] shows how Gemma 2B using AVX512 instructions could solve problems it couldn't solve using AVX2 because of rounding issues with the lower-memory instructions. It's likely that most quantization (and other memory reduction schemes) have similar problems.
As we develop more multi-modal models that can do things like understand 3D video in better than real time it's likely memory requirements will increase, not decrease.
It is just that there's a limit to how much you can compress the models.
The people training 70B parameter models from scratch need ~600GB of VRAM to do it!
There are millions (billions?) of dollars at stake here, and obviously the best minds are already tackling the problem. Only plebs like us who don't have the skills to do so bicker on an internet forum... It's not like we could realistically spend the time inventing ways to run inference with fewer resources and make significant headway.
{kind=link}
{kind=link}