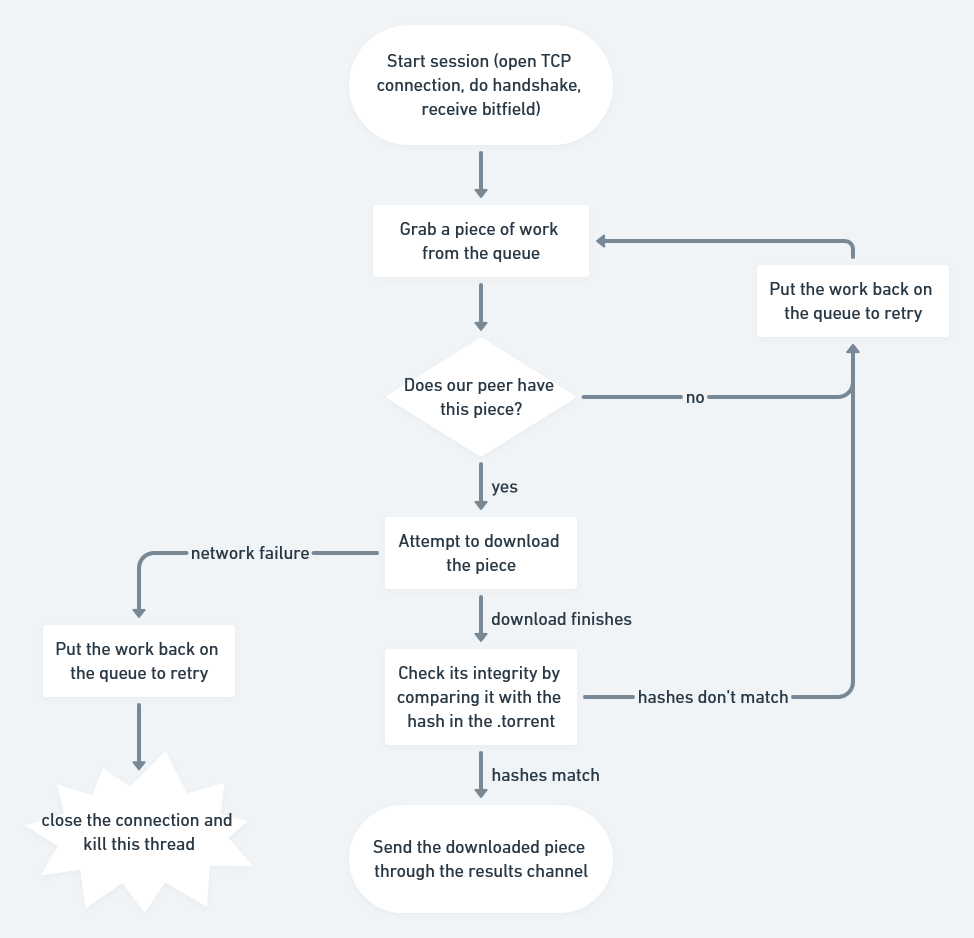
So, building a "perfect" torrent client from the ground up is a daunting task. But the "good" news is that nobody built such a "perfect" client just yet, so if you have some spare months of your time, you can take a shot at it. Or even better yet, open the issue tracker for one of popular clients or libraries, and add one of the missing features from the list above.
- seeding a million active torrents (this is entirely possible and needed but drives a lot of architecture)
- a UI for a million active torrents
- be nice to trackers (keep-alive, batched reports; again, architecture gets tricky, iirc libtorrent can't do that still)
- correct pipelining
- congestion control on uTP
- I/O scheduling/batching
- testing all of the above
It is quite a lot.
I don't do much port forwarding, it's too fiddly. I think I provide upnp out of the box and few other variants that were contributed.
I also have all the DHT extensions, like mutable torrents and get/put etc.
Large torrents do pop up occasionally, but it's been a long time since someone found a performance issue there but it used to happen every few months. Lots of optimisation.
GitHub.com/anacrolix/torrent
NB: especially after https://github.com/Luminarys/synapse died and Transmission "botched" its 4.x rewrite (currently on 3 with some backported patches).
I missed the upnp support, thanks for correcting my beliefs.
Which client with WebUI would you recommend the most? I tried using exatorrent and distribyted, but was running into bugs.
Good multi threading without any global locks is a must or your UI/remote control become unresponsive on big number of active torrents.
Also, it needs daemon mode, which can be compiled & installed without any GUI libs (like QT, GTK, Waynald, libx11, anything like this) and fast responsive remote GUI for all platforms which allows to manage thousands of torrents simultaneously (I'm looking at you, <any-existing-torrent-client>). It could be Web UI, but for now I didn't se usable one. Only thing that semi-works is Transmission + Transmission-Remote-GUI written in Pascal. But it is effectively abadonware and works worse and worse with each Transmission update.
And be scriptable to allow automate change of torrent on tracker, for example (you need to detect it by "Torrent not registered" tracker-specific error answer and re-download torrent building URL from, for example, "comment" field of torrent, again in tracker-specific way).
Which of the qualities you listed are lacking from the currently most popular torrent clients (qBitTorrent, etc..)?
- WebTorrent and WebSocket patch for qBittorrent is ready but not merged (waiting on libtorrent's decision),
- cross-seeding support is poor (a separate "cross-seed" binary can be used to set up hardlinks to fool qBittorrent into cross-seeding, but it cannot detect duplicates on its own)
- when it comes to torrent management, there is no way to group torrents into groups with common settings (important if you use multiple private trackers) - people recommend having multiple installations of qBittorrent side by side
- when it comes to reconfiguring NAT and firewall, qBittorrent supports UPNP IGD protoocl, but I am not sure about NAT-PMP and PCP
- I have never seen qBittorrent connect to a single IPv6 peer - so I don't know if the support is there
- download order - you can choose "download in order" or "download rarest first". I dont think "download in order" downloads footers, so mp4 files won't work (IIRC mp4 store metadata in footer, mkv in header)
These days, I use QB after uTorrent's downfall, but even after all these years, its UX still isn’t quite there.
If this is actually a common use case, I can resurrect it into a usable form for the public if there's interest or funding. https://github.com/anacrolix/torrent
> So, building a "perfect" torrent client from the ground up is a daunting task.
Don’t you think you’re exaggerating a bit? It’s not daunting by any stretch. The feature set you described is fairly straightforward and something even a beginner developer could tackle without too much hassle.
I’m honestly kind of tired of seeing people act like doing anything these days is some impossible feat.
Arvid Norberg is hardly a "beginner developer", yet look how hard it is to make a performant implementation of uTP: https://github.com/arvidn/libtorrent/issues/3542
Try it yourself, from scratch, and see how quickly you will finish something that will rival and surpass, say, qBittorrent.
None of the tasks is breaking new ground or is creatively difficult. But there's a metric ton of those tasks in order to make a truly good torrent client.
But shouldn’t be hard to do with modern facilities (async runtimes, streaming libraries etc.) I don’t enjoy many clients yet I use them.
It’s definitely a good problem with which to test a programming language. Many fail on parsing, or inefficient network interfaces, inefficient file interfaces, sha sum unusable without intrinsics, etc.
That’s quite debatable and my experience is different. There is a whole lot of high level stuff that can be expressed with eg async streams and functional transformation chains in Rust, that Go has no counter offer for. Same for being able to use any future in select/join not just channels. Also I find cleanup / error handling in Rust much cleaner.
And Elixir / Erlang for serious ones.
But, yeah, if I was going to bootstrap a startup at the seed level, Elixir is the best choice for backend. If I'm spending $500K+ a year on infrastructure, I'll be looking at Go and Rust.
laughs in elixir
Now I wonder how clients protect themselves against abusers (i.e.. people who never upload a single bit but only download). I often noticed that when I set the maximum upstream to 0, clients would stop sending me pieces. Do clients share a predefined list of configuration parameters with each other or with the tracker (Max upstream, max downstream, etc.)? Or is it something more sophisticated?
One thing I was thinking though was that the finding of Peers seems to be the bottleneck - that if peer resolution could be almost instantaneous, the BT protocol could be used for so many more use cases.
Does anyone know if this part of the process could ever be improved or does that just come with the territory?
Do you know more such problems?
An FTP client and server.
An IRC client for the older protocol version.
A gemtext parser and gemini client.
A redis clone supporting only the simplest operations.
A brainfuck interpreter.
Twitter.
A todo list program (maybe a little too hard for this list)
This is possible with port forwarding. But that's a niche set of peers, who have the power to configure port forwarding on a NAT proxy.
- If you're nice with me I'll be nice with you
- If you're mean with me I'll be mean with you
This is the best answer for the Prisoner's dilemma (https://en.wikipedia.org/wiki/Prisoner's_dilemma) on the long run, ie a situation where peers don't trust each other but will both gain if both cooperate.
In bittorrent it's typically implemented as follows: peers start by sending a very minimal content, and see what the other replies. If they reply with low enough latency then slowly increase the amount of content that is sent and see if they reply with the same increased amount of content; if they do, continue up to the max of what the network link allows (in combination with other peers of course). If at some point the other peer doesn't send something equivalent (even though we know they have it and we asked for it) then that peer can be cut off for not being cooperative.
Situation is different for seeds of course, because they have everything and want nothing, but they can have a similar behaviour -- start sending a little, increase slowly over time
This is fascinating. Have there been any simulations about this? I'm sure they've looked into this in game theory, but I'm wondering if you have a big swarm of torrent clients, does the scale of the population change the outcome, or is it the same?
(It seems like it would be wise when designing the torrent clients to run such simulations, so I'm thinking this probably has been done at some point.)
In an ideal world the network would prioritize to upload to high speed like webseeds, so the webseeds can distribute even faster for everyone else.
Or do I make a mistake in my mind and the network already distributes efficiently and it is not needed.
It's called leeching, and it depends. It's typically considered good etiquette to upload as much as you download and that's usually enough, but it can be enforced
In practice, BitTorrent really needs seeders who have downloaded the entirety of the file to be fast for everything except really popular downloads, Seeders don’t really check for fairness and will typically upload to whoever they can the fastest (with a limit on number of peers).
There’s an even more adversarial case because the unit of validation (a piece with a fixed hash from the spec) might be bigger than the chunks that are being shared individually. So it’s possible for a peer to fake having pieces and upload garbage data instead, and they wouldn’t be caught since different chunks came from different peers.
My algorithm did favour the best peers (both upload and download) but a few years ago switched to a "seeded" ordering to prevent bad behaviour clients dumping or starving new peers.
The garbage uploaders are not an issue. You can isolate peers to pieces and remove them with certainty, or use a technique called smartban which uncovers bad peers very quickly.
I run a BitTorrent service for an academic institution, to disseminate research data. We have a regular routable IP address, but still need to navigate the institutional firewall.
1. Manual port forwarding, it's likely that there are at least a few power users who already have the torrent and are seeding who have this set up. Seedboxes are a notable example, they're often simple servers that actually have a public IP.
2. UPNP, a protocol that lets you ask your router to set up a temporary port forward for you. Again, not all peers support this, but some do, and you can just connect to those.
3. Hole Punching. Imagine Alice is sending data to Bob, and her router ends up sending it from port 1234. Her router needs to send the packets it receives on port 1234 back to Alice's computer, to allow her to receive Bob's responses. Some routers will do this no matter which IP the packets are coming from. If Bob tells alice her router is sending from port 1234, she can spread that fact to others and let them contact her that way.
I don't know if BitTorrent clients take advantage of this specifically, but it's a very common way of doing NAT traversal in general.
NATs is why private trackers have the concept of "connectability", if you're "connectable", it means you can accept connections from other clients. Crucially, if just one of the peers is connectable, they can both communicate, so connectability is heavily encouraged but not required.
If you enable WebTorrent as a transport protocol (enabled in gotorrent, disabled by default in libtorrent), it should be possible to use existing public STUN/TURN infrastructure, but I don't know if any client does it yet.
In practice, you just have to accept that many connections will simply fail, and make your client move on to try a different peer.
However there is a built-in hole punching mechanism in BitTorrent where peers ask for a third peer to assist in hole punching.
It's implemented in my client. It was very painful to implement. I think someone privately funded the feature which was very nice.
> This is possible with port forwarding. But that's a niche set of peers, who have the power to configure port forwarding on a NAT proxy.
yes it's niche but I guess this means BitTorrent isn't as P2P in practice as one wants it to be, but held up by seedboxes.
The datahoarders run multiple clients. It's a workable solution but far from ideal.
Check out this very nice link from a sibling comment: https://ncase.me/trust/. You'll see that an adversarial node either is too adversarial and will be cut off, or still gives just enough to not be cut off but if there are other, more cooperative nodes, they will be favored. Being adversarial doesn't work in the long run.
Unlike predicting the stock market, competition wouldn't be very fierce, and I think the tracker API would give you most of what you need.
It's in the long list of things I'll do if I ever find a big pile of time.
Try downloading any well distributed torrent and you'll see your bandwidth capacity automatically maxxed out. The gradual decision with an emerging selection of better sources always leads to that. Bittorrent doesn't really have an efficiency problem
However, these pieces can themselves be large, so it is often recommended to split them into smaller chunks that are sent one at a time. You cannot validate a chunk independently, and if you assemble a piece from chunks from multiple origins, you can’t immediately tell which origin is bad.
You need to explicitly handle this case, like the sibling comment mentioned by isolating peers who may have sent bad data and forcing validation.
Probably easiest to do this via docker-qbittorrent-nox.
> - I have never seen qBittorrent connect to a single IPv6 peer - so I don't know if the support is there
The Linux ISOs (not a euphemism) I'm seeding probably get about a third of their peer connections via IPv6.
Not much support for port forwarding.
IPv6 definitely works.
Download order is handled by providing readers directly into torrent data and using that for prioritization. So basically request what you need when you need it. No arbitrary list of algorithms.
qBittorrent (via libtorrent) supports NAT-PMP and PCP
> IPv6
qBittorrent supports IPv6
for cpu bound tasks? sure. but we are talking in the context of networking. elixir is going to absolutely smoke go for applications requiring a lot of simultaneous connections. We can already see it in actionable vs phoenix channels. channels supports a magnitude order more simultaneous websocket connections per machine.
ps: libraries like rustler exist. you can take the cpu intensive stuff and offload it to a module written in rust when you really need to squeeze some perf out.
Rather then tell me, you are going to have to build a bit torrent client in Elixir and show me. Otherwise, after my years experience working with an Elixir team, I don't believe you.
https://stackoverflow.com/questions/42035912/running-c-code-...
{kind=link}