"cat readme.txt" is not safe if you use iTerm2(blog.calif.io) |
"cat readme.txt" is not safe if you use iTerm2(blog.calif.io) |
OTOH, in iTerm2, surprising new features seem to be welcome, if not now, in recent memory. https://news.ycombinator.com/item?id=40458135
what about spaceship? zsh or ohmyzsh?
time to reduce exposed surface
The tweet has no mention of iTerm2 which makes it sound like an issue in 'cat', which is mildly annoying [1].
The post title on 2026-04-18 (when this HN post was made) did not include this qualification:
https://web.archive.org/web/20260418153857/https://blog.cali...
> iTerm2 accepts the SSH conductor protocol from terminal output that is not actually coming from a trusted, real conductor session. In other words, untrusted terminal output can impersonate the remote conductor.
...which, the article strongly implies, but does not explicitly state, results in code execution on the local client machine.
But what about the case when it's working as designed, when the output does come from the remote conductor? It sounds like the server, where the conductor is running, is in that case trusted to execute arbitrary code on the client? Assuming the client doesn't use some sort of remote attestation, how can the remote conductor really be trusted?
I want the terminal to be as dumb as possible.
I don’t want it to have any understanding of what it is displaying or anscribe any meaning or significance to the character characters it is outputting.
The first time apples terminal.app displayed that little lock icon at the ssh password prompt?
The hairs on the back of your neck should have stood up.
The ssh command switches the terminal into no-echo mode with termios flags.
Terminal.app, being clever, watches for disabled echo (among other things) and assumes a password is being entered and displays the key icon and enables Secure Event Input.
I don't want Terminal.app to be clever.
AD in disguise
- ssh conductor
- AI features almost forced on us until the community complained
- clickable links
I just want a dumb, reliable terminal. Is that too much to ask?
The developers of Kitty, Ghostty etc. are too much mouse haters to even acknowledge the possibility of this feature, so I'm stuck with iTerm2.
This was a wrong take back when it happened and it’s even more silly to bring it up now. No AI features were forced on anyone, it was opt-in and HN lost its mind over a nothing burger.
“Oh no! This software has a feature I don’t like which isn’t even enabled by default, whatever will I do?”
Ah yes, the well known c+aliFIo shell script that every developer has. Inside the commonly used "ace" directory.
This article is sensationalist. And constructed by an LLM. It's well known that cat'ing binary files can introduce weird terminal escape codes into the session. Not surprised that iTerm's SSH integration is not security perfect.
Why was this disclosed before the hole was patched in the stable release?
It's only been 18 days since the bug was reported to upstream, which is much shorter than typical vulnerability disclosure deadlines. The upstream commit (https://github.com/gnachman/iTerm2/commit/a9e745993c2e2cbb30...) has way less information than this blog post, so I think releasing this blog post now materially increases the chance that this will be exploited in the wild.
Update: The author was able to develop an exploit by prompting an LLM with just the upstream commit, but I still think this blog post raises the visibility of the vulnerability.
My only caveat would be that in some security fixes, the pure code delta, is not always indicative of the full exploit method. But LLMs could interpolate from there depending on context.
>The author was able to develop an exploit by prompting an LLM with just the upstream commit
Yes, I was able to do this. I believe anyone watching iTerm2's commits would be able to do this too.
>but I still think this blog post raises the visibility of the vulnerability.
Yes, I wanted to raise the visibility of the vulnerability, and it works!
The author of iTerm2 initially didn’t consider it severe enough to warrant an immediate release, but they now seem to have reconsidered.
It's funny that we still have the same conversation about disclosure timelines. 18 days is plenty of time, the commit log is out there, etc.
The whole "responsible disclosure" thing is in response to people just publishing 0days, which itself was a response to vendors threatening researchers when vulns were directly reported.
If publicly accessible AI model with very cheap fee can find it, it's very natural to assume the attackers had found it already by the same method.
LLM is a tool, but people still need to know — what where how.
You may need Claude Mythos to find a hard-to-discover bug in a 30-year-old open source codebase, but that bug will eventually be patched, and that patch will eventually hit the git repo. This lets smaller models rediscover the bug a lot more easily.
I won't be surprised if the window between a git commit and active port scans shrinks to hours or maybe even minutes in the next year or two.
This is where closed source SaaS has a crucial advantage. You don't get the changelog, and even if you did, it wouldn't be of much use to you after the fix is deployed to production.
It also puts the lie to "all bugs are shallow with sufficient eyes", gmime is pretty commonly used, but locale<->UTF and back were still wrong.
I don't know what to do with this. I think there's this problematic tension between the expectation that on one hand, basic OS-level tools should remain simple and predictable; but on the other hand, that of course we want to have pretty colors, animations, and endless customization in the terminal.
And of course, we're now adding AI agents into the mix, so that evil text file might just need to say "disregard previous instructions and...".
Poof went the operating system!
https://blog.danielwellman.com/2008/10/real-life-tron-on-an-...
https://blog.mozilla.org/security/2019/10/09/iterm2-critical...
> iTerm2 accepts the SSH conductor protocol from terminal output that is not actually coming from a trusted, real conductor session. In other words, untrusted terminal output can impersonate the remote conductor.
If I understand correctly, if a textfile (or any other source of content being emitted to the screen, such as server response banners) contains the special codes iTerm2 and the remote conductor use to communicate, they'll be processed and acted upon without verifying they actually came from a trusted remove conductor. Please correct me if I'm mistaken.
Thanks for releasing a fix!
It was surprising that there wasn't an official release, even though the bug impacts otherwise routine, harmless workflows. The patch itself [1] framed the issue as "hypothetical," so the goal of the blog post was to demonstrate that it is not. I'm glad that you've agreed to release a fix.
[1] https://github.com/gnachman/iTerm2/commit/a9e745993c2e2cbb30...
⇒ https://nvd.nist.gov/vuln/detail/CVE-2025-22275
iTerm2 3.5.6 through 3.5.10 before 3.5.11 sometimes allows remote attackers to obtain sensitive information from terminal commands by reading the /tmp/framer.txt file. This can occur for certain it2ssh and SSH Integration configurations, during remote logins to hosts that have a common Python installation.
But I thought there was something more…
https://news.ycombinator.com/item?id=47811587 (this page) was in the tmux integration.
Maybe iTerm2 should try a little less hard on these integrations...
How about bloody no and working with upstream ncurses to update the terminfo database?
And I know PuTTY has a setting for what string is returned in response to some control code, that iirc per standard can be set from some other code.
.
In general, in-band signaling allows for "fun" tricks.
.
+++
Two tips, if I may: Ctrl-l is easier to type. And `reset` is equally hard to type on a broken terminal, but more effective.
> It turns out that it is NOT, if you use iTerm2.
And as far as I can tell, that is a vast overstatement. I think an actually true statement would be "It may not be, if you use iTerm2 and its optional 'Shell Integration' feature."
As far as I can tell, the "Shell Integration" feature under discussion is entirely optional and disabled by default. If it's not enabled, then there is no problem here. End of story.
Happy to be corrected if I'm wrong about this.
I note that the documentation says this:
> Shell Integration
> iTerm2 may be integrated with the unix shell so that [blah blah blah]
> How To Enable Shell Integration
> [blah blah blah]
And that does not make it sound as if it's enabled by default. I really don't know. I only started using iTerm2 about three or four weeks ago.
alias cat
cat='strings -a --unicode=hex'Like why doesn't `println` in a modern language like rust auto-escape output to a terminal, and require a special `TerminalStr` to output a raw string.
Consider cat. It's short for concatenate. It concatenates the files based to it as arguments and writes them to stdout, that may or may not be redirected to a file. If it didn't pass along terminal escapes, it would fail at its job of accurate concatenation.
Now I don't mean to dismiss your idea, I do think you are on the right track. The question is just how to do this cleanly given the very entrenched assumptions that lead us where we are.
That's because we had terminal side macros. They were awesome in the 1980s.
README: no such file or directory
One glorious day somebody finally sent me email complaining that they could not read the README file. I advised them to use "emacs README" instead of using cat. I was sorely disappointed they never sent me back a thank you note for correctly suggesting that emacs was the solution to their problem. It was my finest moment in passive aggressive emacs evangelism.
If I wrote my own version of cat in C, simply reading and displaying a single TXT character at a time, wouldn't I see the same behavior?
It is a problem in iterm, Apple's overlay, not in the cat program. Program. At least from Reading the article. That's what I got
cat is a file concatenation utility. UNIX people know to view text files with more.
> A terminal emulator like iTerm2 is the modern software version of that hardware terminal.
That's the fundamental fatal flaw of emulating a bad dead hardware design. Are there any attempts to evolve here past all these weird in-band escape sequences leading cats to scratch your face?
Also the problem here isn’t that iterm2 is trying to emulate terminals, it’s that it’s trying to do something more over the same network connection without making changes to the ssh protocol.
what we really want is being able to pipe semantic data that can be output to some kind of graphical device/interface that uses that semantic information to display the data using nice graphical interface elements.
If iTerm2 had stuck to emulating a VT220 this issue would not have existed. If anything it's the idea that it should "evolve" that's flawed. Something like a VT220 was designed for a kind of use that is surprisingly relevant still. I think doing something significantly different warrants designing something significantly different, not merely "evolving" existing solutions to other problems by haphazardly shoehorning new features into them without paying attention to security implications.
This is only the latest of several rather serious vulnerabilities in iTerm2's SSH integration.
What does iterm2 do with all that information, why does it need it? I don't get it
OpenAI: sponsor of the today's 0-day.
If we can get that to raise a red flag with people (and agents), people won’t be trying to put control instructions alongside user content (without considering safeguards) as much.
At a basic level there is no avoiding this. There is only one network interface in most machines and both the in-band and out-of-band data are getting serialized into it one way or another. See also WiFi preamble injection.
These things are inherently recursive. You can't even really have a single place where all the serialization happens. It's user data in JSON in an HTTP stream in a TLS record in a TCP stream in an IP packet in an ethernet frame. Then it goes into a SQL query which goes into a B-tree node which goes into a filesystem extent which goes into a RAID stripe which goes into a logical block mapped to a physical block etc. All of those have control data in the same stream under the hood.
The actual mistake is leaving people to construct the combined data stream manually rather than programmatically. Manually is concatenating the user data directly into the SQL query, programmatically is parameterized queries.
Allow a process to send control instructions out-of-band (e.g. via custom ioctls) and then allow the pty master to read them, maybe through some extension of packet mode (TIOCPKT)
Actually, some of the BSDs already have this… TIOCUCNTL exists on FreeBSD and (I believe) macOS too. But as long as Linux doesn’t have it, few will ever use it
Plus the FreeBSD TIOCUCNTL implementation, I think it only allows a single byte of user data for the custom ioctls, and is incompatible with TIOCPKT, which are huge limitations which I think discourage its adoption anyway
Ironically, agents have the exact same class of problem.
https://utcc.utoronto.ca/~cks/space/blog/sysadmin/OnTerminal...
I think the real solution is that you shouldn't try to bolt colors, animations, and other rich interactivity features onto a text-based terminal protocol. You should design it specifically as a GUI protocol to begin with, with everything carefully typed and with well-defined semantics, and avoid using hacks to layer new functionality on top of previously undefined behavior. That prevents whatever remote interface you have from misinterpreting or mixing user-provided data with core UI code.
But that flies in the face of how we actually develop software, as well as basic economics. It will almost always be cheaper to adapt something that has widespread adoption into something that looks a little nicer, rather than trying to get widespread adoption for something that looks a little nicer.
This is a recurring problem with fancy, richly-featured programmer-oriented apps made by programmers for programmers because for some reason most of the tool-writing programmers apparently just love to put "execute arbitrary code" functionality in there. Perhaps they think that the user will only execute the code they themselves wrote/approved and will never make mistakes or be tricked; or something like that, I dunno.
This is usually knowable.
It's a different question whether cat should be doing that, though – it's an extremely low level tool. What's wrong with `less`? (Other than the fact that some Docker images seem to not include it, which is pretty annoying and raises the question as to whether `docker exec` should be filtering escape sequences...)
The C0 control set (ASCII 0x00 to 0x1F) contains all sorts of esoteric functions, most of which are generally unused, and only a few of which are useful and could be implemented at a higher-level. ESC sequences are only part of the problem.
And this also applies not just to terminals, but to systems programming as well. None of these have any business in e.g. filenames, but it's all commonly permitted. Some systems do forbid them, and it should IMO be universal.
If we really want to fix this, then we would develop a character encoding that strips out all control characters entirely, including LF and CR, and have text be nothing but graphic text characters. It's so entrenched and convenient that it's difficult to see that happening. But I do think routine stripping of all control characters in situations that don't require them would be good for security.
I cannot speculate on what fraction of iTerm2 users enable this optional feature. Is it "many or most"? No idea.
I note that the article nowhere mentions the fact that the feature is optional. That would be a huge improvement.
We can disagree over whether the article is horribly written or not. My firm opinion is that it is.
Attackers are not idiots. Once you have the commit, it is usually pretty easy to figure out, even just having the binary diff is usually enough.
The broader problem with terminal control sequences didn't exist on Windows (until very recently at least), or before that DOS and OS/2. You had API calls to position the cursor, set color/background, etc. Or just write directly to a buffer of 80x25 characters+attribute bytes.
But Unix is what "serious" machines -a long time ago- used, so it has become the religion to insist that The Unix Way(TM) is superior in all things...
I don’t think one already exists, but it would be straightforward to create one. SSH protocol extensions are named by strings of form NAME@DNSDOMAIN so anyone can create one, registration would not be required.
The hardest part would be getting the patches accepted by the SSH client/server developers. But that’s likely easier than getting the feature past the Linux kernel developers.
If you're gonna jack some control protocol into a session which is sitting directly on the stream protocol, that's on you. This is as airtight as injecting a control protocol into SMTP or HTTP. Encapsulate the entire protocol (obviously this requires presence on both ends), open a second channel (same), or go home. It's worth noting that the "protocol" drops a helper script on the other side; so theoretically it is possible for them to achieve encapsulation, but doing it properly might require additional permissions / access.
Obviously they published a fix, since that's how the exploit was reverse engineered. This is "...what happens when terminal output is able to impersonate one side of that feature's protocol."
Which has nothing to do with terminals, because nobody runs terminals directly over TCP. Telnet wasn’t simply sending terminal bytes over TCP, it has its own complex system of escape sequences and protocol negotiation (IAC WILL/WONT/DO/DONT/SB/SE, numerous Telnet options). SSH is even further from raw TCP than Telnet was
And a Unix pty isn’t a simple stream either. Consider SIGWINCH
Run software in container. Software gets PTY. Boom, same issue
Terminal apps were obsolete once we had invented the pixel. Unix just provides no good way to write one that can be used remotely.
well that's the issue, isn't it?
the graphics options that we have are slow and complex, and they don't solve the problems like a terminal and therefore the terminal persist.
Not true. For most binary protocols, you have something like <Header> <Length of payload> <Payload>. On magnetic media, sector headers used a special pattern that couldn't be produced by regular data [1] -- and I'm sure SSDs don't interpret file contents as control information either!
There may be some broken protocols, but in most cases this kind of problem only happens when all the data is a stream of text that is simply concatenated together.
[1] e.g. https://en.wikipedia.org/wiki/Modified_frequency_modulation#...
Another fun one there is that if you copy data containing an interior NULL to a buffer using snprintf and only check the return value for errors but not an unexpectedly short length, it may have copied less data into the buffer than you expect. At which point sending the entire buffer will be sending uninitialized memory.
Likewise if the user data in a specific context is required to be a specific length, so you hard-code the "length of payload" for those messages without checking that the user data is actually the required length.
This is why it needs to be programmatic. You don't declare a struct with header fields and a payload length and then leave it for the user to fill them in, you make the same function copy N bytes of data into the payload buffer and increment the payload length field by N, and then make the payload buffer and length field both modifiable only via that function, and have the send/write function use the payload length from the header instead of taking it as an argument. Or take the length argument but then error out without writing the data if it doesn't match the one in the header.
>It's user data in JSON in an HTTP stream in a TLS record in a TCP stream in an IP packet in an ethernet frame. Then it goes into a SQL query which goes into a B-tree node which goes into a filesystem extent which goes into a RAID stripe which goes into a logical block mapped to a physical block etc. All of those have control data in the same stream under the hood.
It's true that a lot of code out there has bugs with escape sequences or field lengths, and some protocols may be designed so badly that it may be impossible to avoid such bugs. But what you are suggesting is greatly exaggerated, especially when we get to the lower layers. There is almost certainly no way that writing a "magic" byte sequence to a file will cause the storage device to misinterpret it as control data and change the mapping of logical to physical blocks. They've figured out how to separate this information reliably back when we were using floppy disks.
That the bits which control the block mapping are stored on the same device as a record in an SQL database doesn't mean that both are "the same stream".
The problem with this is that the credible information "there's a bug in widely used tool x" will soon (if not already) be enough to trigger massive token expenditure of various others that will then also discover the bug, so this will often effectively amount to disclosure.
I guess the only winning move is to also start using AI to rapidly fix the bugs and have fast release cycles... Which of course has a host of other problems.
There's a security bug in Openssh. I don't know what it is, but I can tell you with statistical certainty that it exists.
Go on and do with this information whatever you want.
But if you're a security research lab that a competing lab can ballpark the funding of and the amount of projects they're working on (based on industry comparisons, past publications etc.), I think that can be a signal.
There are many attackers that are just going to feed every commit of every project of interest to them into their LLMs and tell it "determine if this is patching an exploit and if so write the exploit". They don't need targeting clues. They're already watching everything coming out of
Do not make the mistake of modeling the attackers as "some guy in a basement with a laptop who decided just today to start attacking things". There are nation-state attackers. There are other attackers less funded than that but who still may not particularly blink at the plan I described above. Putting out the commit was sufficient to tell them even today exactly what the exploit was and the cheaper AI time gets the less targeting info they're going to need as the just grab everything.
I suggest modeling the attackers like a Dark Google. Think of them as well-funded, with lots of resources, and this is their day job, with dedicated teams and specialized positions and a codebase for exploits that they've been working on for years. They're not just some guy who wants to find an exploit maybe and needs huge hints about what commit might be an issue.
The parent's point is that if those capable attackers can exploit it anyway, doesn't mean it should be given on a silver platter to any script kiddie and guy in some basement with a laptop. The first have a much smaller target group than the latter.
And the moment the commit lands upstream, they know what, where, and how.
The usual approach here is to backchannel patched versions to the distros and end users before the commit ever goes into upstream. Although obviously, this runs counter to some folks expectations about how open source releases work
In other words, it becomes part of your threat model.
> we rely on AI to find it
> where
> the upstream commit
> how
> publicly accessible AI model with very cheap fee
It seems to me that you are conflating the role of the terminal with the role of the shell. The terminal accepts streams of text and commands to instruct the terminal, so that software can accept input and present output. It doesn't fundamentally need to be aware of the concepts of pipes and commands to do that.
Of course, that doesn't stop iTerm2 from doing RCE by design, but at a conceptual level this is not a problem inherent to a terminal.
What is it specifically that you want to do which your favorite shell doesn't allow because it is restricted by terminals?
How about Arcan?
Which is also what happens if you use parameterized SQL queries. Or not what happens when one of the lower layers has a bug, like Heartbleed.
There also have been several disk firmware bugs over the years in various models where writing a specific data pattern results in corruption because the drive interprets it as an internal sequence.
In this particular case, IIRC Hayes had patented the known approach for detecting this and avoiding the disconnect, so rival modem makers were somewhat powerless to do anything better. I wonder if such a patent would still hold today...
What was patented was the technique of checking for a delay of about a second to separate the command from any data. It still had to be sent from the local side of the connection, so the exploit needed some way to get it echoed back (like ICMP).
More relevant to this bug: https://en.wikipedia.org/wiki/ANSI_bomb#Keyboard_remapping
DOS had a driver ANSI.SYS for interpreting terminal escape sequences, and it included a non-standard one for redefining keys. So if that driver was installed, 'type'ing a text file could potentially remap any key to something like "format C: <Return> Y <Return>".
> The rough model is:
> 1. iTerm2 launches SSH integration, usually through it2ssh.
> 2. iTerm2 sends a remote bootstrap script, the conductor, over the existing SSH session.
> 3. That remote script becomes the protocol peer for iTerm2.
How can I tell whether this "conductor" is running on the remote host or not?
I tried to reproduce this problem, following their instructions, but was unable to. I think but am not sure that's because my environment is pretty much nothing like one that would allow this to work.
For example, whether it's the default or not, my iTerm2 just doesn't have shell integration enabled. With my profile "Command:" set to "Login Shell," it doesn't look like I could enable it if I wanted to: "Load shell integration automatically" is disabled, apparently because "Automatic loading doesn't work with ksh."
This is explained in the article in the "The core bug" section.
consider something like grep on multiple files. it should produce a list of lines found. the graphical terminal takes that list and displays it. it can distinguish the different components of that list, the filenames, the lines matched, the actual match, etc. because it can distinguish the elements, it can lay them out nicely. a column for the filenames, colors for the matched parts, counts, etc.
grep would not produce any graphics here, just semantic output that my imagined graphical terminal would be able to interpret and visualize.
https://blog.rmilne.ca/wp-content/uploads/2020/04/image_thum...
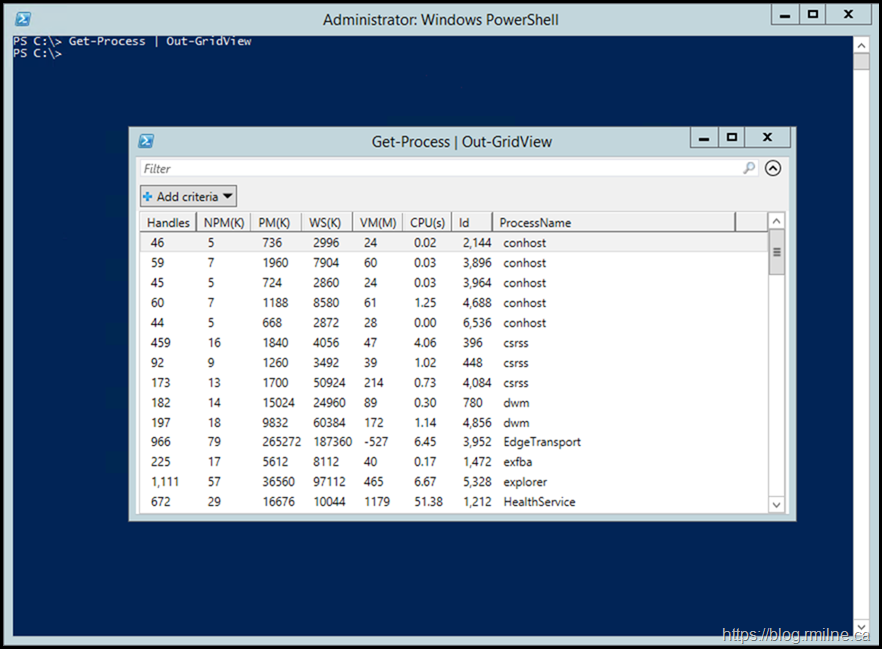
PowerShell cmdlets output .NET objects with properties, in that example Get-Process makes an object-per-running-process with properties for Name, Id, and more. Out-GridView takes arbitrary objects and draws a resizeable GUI window with a list of the input, properties as columns, sortable, filterable, and has options to use it as a basic "choose one of these and click OK" user-prompt. It works with the grep-analogous cmdlet:
select-string '<regex>' <filename(s)> | out-gridview
# shorthand
sls foo *.txt | ogv
If we're talking about things we imagine in terminals, one I have wanted is multiple windows for making notes, similar to having a text editor open constantly reloading a file on any changes and running some terminal commands with tee into the file, but better integrated - so I could keep a few useful context results but ignore logspam results; and "keep" in another window without having to copypaste. Something better integrated - it always gets all command output, but disposes of it automatically after a while, but can be instructed to keep.
PowerShell, for instance, has Format.ps1xml[0] that allows you to configure how objects get displayed by default (i.e. when that object gets emitted at the end of the pipeline). Such a concept could in principle be extended to have graphical elements. How cool would it be to have grep's output let you collapse matches from the same file!
[0] https://learn.microsoft.com/en-us/powershell/module/microsof...
incidentally ttyphoon is a terminal that uses a browser base gui framework. maybe there is that browser for the teminal...
Maybe you'd be interested to learn about plan9's graphical terminal. Its window manager runs entirely within it, and all windows just represent multiplexed access to limited areas of the terminal.
correct. the in-band sequences are dangerous and unwieldy. they don't convey enough information. they are a hack to work within the limitations if historical terminals. that's what this whole thread is about.
a separate graphics channel creates a separate window. then you have two windows. not good either. it needs to be one window, and considering that this window should be able to support multiple remote connections it needs to be local otherwise i would get a new window for each server i connect to. that works for some people, but not for me. and it needs to work through a single channel like ssh/mosh or another similar protocol and be forwardable.
so i want a third option. one approach is sending semantic data, letting the terminal interpret it and display it graphically. this is interesting because shells are already exploring semantic data. (elvish, murex, nushell, others...)
plan9 sounds interesting. i see several efforts to port aspects of it to linux. they all seem to have stalled. more work needs to be done here. that's what i am advocating.
Emacs is text based (mostly), but customization happens through the the concept of Faces, not ansi escape codes. You can then embed properties in the text objects and have them react to click events. The only element missing is a 2D context that could be animated (if it's static, you can use SVG as Emacs can render it).
It could be an interesting paradigm, though, to have a hybrid between fullscreen and traditional tty programs: you output some forms, they are displayed by the terminal inline, but your scrollback just works like normal, and you can freely copy and paste stuff into the form. Once you submit the form, it becomes non-interactive, but stays in your scrollback buffer. You can select and copy textual data from it, but the form’s chrome cannot be selected as line drawing characters.
Probably could be a piece of concept art, I guess.
{kind=link}