Apparently Google hates us now(twitter.com) |
Apparently Google hates us now(twitter.com) |
Here is a part of the Gemini result I got which was directly above the regular result link.
"Pokémon Central is a major community network and independent Italian encyclopedia for everything Pokémon-related"
Honestly, the title is super clickbait and it doesn't even reflect reality. Its so easy picking some giant entity far away and create some drama about it. Dont get me wrong, I am not a google fan, but I also dislike clickbaits and whiney dramatic claims, moreover if unverified.
Google is likely their biggest inbound source of traffic, so they're probably experiencing a marked revenue drop as well.
It's unfortunate that so many livelihoods are subject to the capricious whims of a single company. A company that is increasingly seeking to keep users on their engine without sending eyeballs or revenue to any third parties at all.
We're watching Google's "embrace-extend-extinguish" arc for the web. It's not over by a long shot, but they absolutely intend to finish the job.
(to be clearer what the source of the post is)
All we can hope for is that people will stop using search (after eventually having enough of the AI wave) for these sort of niche sites and will bookmark and access them directly in future. I don't have much hope.
I think this is because
(A) bookmarks lists are inconvenient - scrolling to find a bookmark is slower than typing "youtube" or (cringe) "bank of america" in the URL bar
(B) typing URLs directly requires precision of memory with TLDs being numerous and even things that were once predictable are now mere suggestions (e.g. is your city or town at cityofwhatever.com? city.org? city.gov? Could be anything!)
(C) related to (B) if you screw up a full URL you may well end up at a phishing site that looks like the site you wanted.
I really believe that 90% of Google and Bing searches today are probably for the names (or misspelled or partial names) of the top 100 websites.
If the dominant browsers weren't Google Chrome and Mobile Safari (who gets paid by Google for every search) browsers would build bookmarks for you of your frequently-used sites, and ordered by frequency of visits, present those for direct navigation when you type a word in the search bar, and not send any query to a search engine if you chose one of those. But all incentives point very strongly against doing that and toward sending you to a SERP with 13 ads and an "AI Overview" above the organic results.
We should've gotten out of US dependence decades ago.
i like to mail a fiver or two to a P.O.B.
As a search engine, it does not work for me. I see promoted links above the thing I actually search for. Moved to Kagi and didn't look back.
As an AI it does not work for me. I am seeing an arbitrary usage limit, refreshing in 5 hours and a weekly quota given in a percentage. That is as opaque as it gets. Again, to give Kagi as an example I look at my usage details and I see how much is remaining in a clear way. Not working for Kagi by the way, I am just a happy customer.
As a cloud storage, it does not work for me. Probably some shared folder I am working with others has a spam user and/or a hacked account and they periodically spam x-rated notifications. And that's not only me (https://www.reddit.com/r/techsupport/comments/1azf25v/myster...). Moved to apple iCloud and done with it.
Mail is fine. After 22 years of usage, I kind of delegated it to a non-important stage in my life. The important bits have relocated to European providers anyway.
DDG doesn’t click for me sadly, and I cannot point my finger to where or why
Apple Maps never does that. Still, I usually use Google as I want an accurate idea of whether a business is actually open and what its hours are.
Also, Apple is gearing up to stuff ads (cough "sponsored results" cough) into Maps, at which point it will probably start suffering the same problem..
That being said a giant corporation like Google releasing free but amazing research like AlphaFold or (less so) something like Gemma is still cool. They're the ATT PAC Bell or IBM of our age it seems
Edit: come to think of it, I don't know why I still use Google. I don't care if they track me. But when they have been actively try to prevent me from finding the information I'm looking for, and instead try to scam me?
I can relate. Just today I was working on my car and I asked Gemini how to remove the Steering ball joint. It all started well, wrote a lengthy answer and then suddenly wiped it all and instead wrote 'i can't answer that, try to ask about another subject'.
For the love of God, talking about cars are now also being forbidden by Google.
And it's not a one off, I asked multiple questions about other parts because I had a lot of issue and it was the first time removing the Gimbals and replacing the Gimbal head on that car.
Google is beyond infuriating, they are a tech company and behave like some old fashioned administration lady. Completely out of touch with real life.
On this last part, I'm convinced that it's because Google management must be completely out of touch with real life. Tech world is special, add millions on top of that..
The best that could happen to this company is to break it's monopoly so that they are forced to get rid of these lunatics.
It took me about a year of updates but now I rarely get anything to a @gmail
Source: a small wiki I help manage, for an obscure game with <10k players, recently had to disable new signups, because the spam was so bad (and it was stuck on an old version of MediaWiki, which didn't have CAPTCHA-support).
On a popular wiki, and it sounds like this one was fairly popular, I imagine even CAPTCHA's won't be enough to stop wiki spammers. If those spammers were posting more than just "buy my penis pill" garbage (e.g. they were putting links to malware sites), Google probably, and somewhat legitimately, saw them as a source of such malware.
I imagine the fix for the OP is a thorough audit/cleansing of all malicious content on the wiki, followed by some sort of appeal to Google (which will no doubt take months, if they even respond at all, because ... Google).
Really OP's only hope is that the Google team responsible for this has an Italian Pokemon fan; otherwise they are probably screwed.
There's a lot of delayed cause and effect in search, and it's much easier to make a minor mistake that excludes 0.1% of websites from crawling or indexing than it is to detect that it's happened except from affected websites telling you about it.
Like in marginalia I've had a bug that affected websites in the condition that if the root path didn't support HEAD, but did support GET with a `Range` header, and it correctly responded with a HTTP 206, then the website wouldn't be indexed because some code that was testing the root document for issues as an initial probe handled that as an error state. Most websites that support range requests also support HEAD (as this usually means the document isn't generated). Except a handful of Caddy-based configurations, about 0.3% of servers.
EDIT: I don't actually think it is related, but now that I think of it, the timing corresponds with when I started setting up TDMRep to forbid using my content to train LLMs.
Scherzi a parte, spero che possiate recuperare presto…
What used to be easily searchable (e.g. "opencv orb") now brings up pages and pages of spam sites (basically "learn opencv here!" blogspam).
Literally the first result on "docs.opencv.org" is on page 4, and points to version 3.4 (9 years old!).
The page that I want https://docs.opencv.org/4.13.0/dc/dc3/tutorial_py_matcher.ht... is nowhere to be found.
Growing up as a teenager and young adult, I remember fondly browsing Newgrounds and being thankful to those who were paying to keep the servers running; I swore that once I got my footing and had some cash to spare, I'd be paying it forward and have been doing so for almost ten years now (took me longer than expected).
So, what I'm trying to encourage is to normalize THAT (Having X% amount of paying customers that make it possible to keep it free for those who can't pay, or to support growth), because I'm pretty sure dozens of thousands of successful careers in programming and animation were launched — or at least inspired — by wonderful sites like Newgrounds and I think that has been very much a positive net thing for society.
All businesses seek to survive, and will use human goodwill until it is not needed anymore. Everyone who thought that Google was opening up the web out of the generosity of their hearts will be shocked when they "feel" nothing when that is taken, because ultimately a company cannot "feel" anything at all, so the OP headline is a silly proposition.
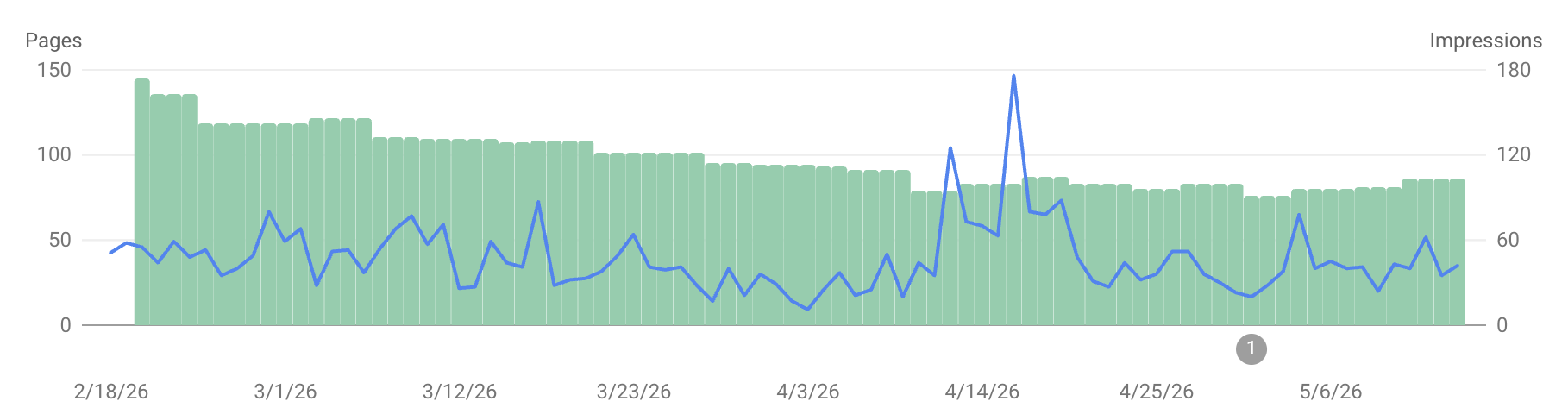
Google is DRASTICALLY reducing the size of their search index. The reasons can be debated but the outcome is clear. A much smaller index of pages they consider to be the primary authority. Anything else they are not interested in and do not need.
Google is really big, though. Really really big. They're so big that not even all the people inside Google are trustworthy to them on a subject like this.
But they don't universally hate wikis and so on. It's just you have to do a lot of work and make sure you don't have spam on your wiki, and then fill in all of the information in your meta tags, and have a sitemap.xml, and all that. Here's my wiki for example: https://wiki.roshangeorge.dev/w/images/8/89/Screenshot_-_Goo...
Perhaps they will investigate why 541,000 pages aren’t being indexed. In my experience, Google provides adequate tools for identifying and resolving indexing issues.
Google won’t serve pages it hasn’t indexed. Seems they left a lot of relevant details out of that tweet.
Edit: and the most likely answer would be that their current robots.txt disallows virtually all indexing. I’m no SEO expert but entries like this seem like footguns:
User-agent: Google-Extended
Disallow: /
We don't get any spam since there's no public signups for editing access.
The Pokemon Industrial Complex has advanced astroturfing especially on YouTube/Twitch, where streamers mention the damn things in any second episode, they "accidentally" meet people going to Pokemon conventions in live streams and so on.
Try to audit the Wiki if anyone abused it.
It does infuriate legitimate users, enables other kind of abuse and scamming (eg immunize yourself against delisting with this one weird trick!', link farming etc), and act as a fig leaf for abusive behavior by platform operators. Effectively, we've allowed large teach companies to act as digital dictatorships with no accountability to their customers. Yes I consider users to be 'customers' even if they're uploading content or doing searches 'for free'. If you're monetizing their activity on your platform, they are your customers whether or not you call them that to avoid legal liability.
Or at least that's what I heard a few years ago when it was politically incorrect people complaining about being banned with no accountability. They're a private company, it's their servers. You may not even be paying anything. So they can do anything they want to you and you have no cause for complaint.
My first thought would be that they accidentally blocked Google's crawler (maybe through some kind of anti-AI setting?) or that Google believes that the site is serving malware or spam. Either scenario can have that kind of effect. I can see that their forum at least appears to have strong Cloudflare anti-bot rules in place, so that might be the case.
They're also using a subdomain for both their wiki and forum, which Google has been observed to punish. They might consider moving each of those to their own separate .com domain.
But aside from that usual stuff, there's one more possible reason that's specific to this site. In November of last year, the Pokemon Company rebranded their "Pokemon Trainer Club" to "Pokemon Trainer Central", which is the first result that comes up when you search for "Pokemon Central".
That change was made a few months before the sudden drop in traffic, but could still be a viable explanation here. Google does routine re-ranking on a daily basis along with occasional major re-ranking, which happens maybe a few times a year, so the delayed hit that they saw could have come from Google finally recognizing that most people who search for "Pokemon Central" are no longer looking for the wiki like was once true in the past.
https://gonintendo.com/contents/54863-pokemon-trainer-club-r...
As for whether it's responsible or not, obviously I don't know. What I do know is that, without all the info, "Google saw malicious content on your wiki" is a far more logical theory than "Google just decided to hate us out of the blue".
If its small enough you can usually avoid all the spam bots by adding any none-standard flow in registration procedure. E.g static picture or audio of something only your audience know with like drop down option to click on picture saying "I'm not a bot". Or add one more email verification for first post or edits. Or make users watch large YouTube video at certain timespamt with correct answer, etc. Anything non-standard works.
Breaks 99.9% of automation and SERP spammers wont bother create unique one for your wiki / forum / etc.
If your site is very popular you're fckd obviously and it's just arm race. This is where you can use Hashcash or something that will burn lots of CPU / GPU / RAM / etc single time so spammers will just blacklist you.
I understand that you were taken aback by spam attacks on the wiki you help manage, but it's not reasonable to generalize from yours to theirs.
>As for whether it's responsible or not, obviously I don't know. What I do know is that, without all the info, "Google saw malicious content on your wiki" is a far more logical theory than "Google just decided to hate us out of the blue".
For small platforms it makes a lot of sense, for larger the potential for abuse is still there in different forms.
- You can't vouch for downstream invites, so the tree aspect isn't useful.
- It's not your fault if someone's account gets taken over by a spammer.
- Just because you vouched for someone once doesn't mean you vouch for them in the future.
- What should the punishment be if you accidentally invite a bad actor?
- Your community has to be large and desirable enough for people to bother. The vast majority of sites will die before anyone cares about jumping through hoops.
Addressing issues like these ends up kinda defeating the ideals of the proposal and regresses it into a mechanic that simply makes it harder to register. Which might be useful wrt anti-spam, but it has its own issues, like people having to constantly grovel for invites, shutting out earnest contributors, etc.
I remember begging my older step brother for an invite since he had the college email to get in
It raises the bar at least somewhat though!
Right, that's why they pushed AMP and upranked AMP pages in their results. That's also why they decided to severely neuter/remove as blocking extensions for Chrome. That's also probably why google search results are getting worse by the month with more and more ads and spam being upranked to the top.
It's because google has a mission of making the web more accessible. Okay bud.
And accessibility was meant for Google so they can collect all the data to make even more profit.
> thousands of people who are all working on different things
those thousands of people aren't making the overall decisions
> with an over-arching mission of making the web MORE accessible
google's mission has for a long time now been to deliver value to its shareholders; making the web more accessible is secondary, nice if aligned with increasing revenue
So same thing ad-block users have been doing for 20 years now?
Edit: You can downvote, but you can't tell me the difference, can you?
Edit 2: Funny how when you call out ad block users for denying creators revenue, they go on about how the internet was fine in '96, how no one should expect anything for putting content online, or how it's their computer so they can chose what loads on it. Where did those arguments go?
Two ways in which issues who have adblock are better than bots.
Users will promote organically, which can win more credence than even a higher listing in SERPs. Depends if your wiki is part of building a community.
Are you denying creators revenue by not reading reading/observing every ad that comes your way and making purchases based on them? Maybe you should read/comment on HN less and focus on consuming more ads instead?
What at an incredibly stupid thing to say.
I expect the difference is that the scrapers are the most likely to regurgitate the content one way or the other.
Advertisers only care about attention, if you don't impose editorial standards they'll contaminate your entire site.
Ad-block users didn't mine Pokémon Central for content, then remove them from search listings. Changing the specific criticism made to the generic "denying creators revenue" is a distortion, because they screwed over all people who wanted visitors, not just the people who wanted visitors to milk them for cash.
If I made a forum about trains because I wanted people to come to the forum to talk about trains, Google milked the forum for all of the accumulated information about trains, then made it impossible to attract new users to talk about trains.
You just have to not use third party integrations that run untrusted code on your visitors computers.
This is not meant to be a defense of Google, which is (like virtually every large corporation) completely sociopathic.
Each cell receives nourishment from the corporation in the form of monetary compensation (and other benefits). Some cells have a more direct role in the "reasoning" process of the organism than others, depending on their logical position within the corporation.
The corporations aren't sentient in the collective, though it can be argued many of their constituent cells are. The corporations are able to influence their environment using individual constituent cells to communicate with similar cells in other organisms.
Ultimately, the corporation itself has the goal of producing value for its owners, since its owners provide the working capital necessary for the corporation to function.
The methods corporations use to achieve their goal of returning value can be opaque to the owners and potentially inscrutable to the individual constituent cells. Their "reasoning" is a manifest property coming from the interaction of the cells with the environment, the cells interacting with each other (both within and outside the corporation), and other organisms.
(There's the neat rub that individual cells can be constituents of multiple organisms simultaneously, too!)
If the owners stop receiving value and withdraw their working capital the corporation becomes unable to nourish its cells and it dies.
Recently these organisms have become biological / technological hybrids, incorporating unconscious computational models in their reasoning process. This change increases the inscrutability and opacity of the reasoning process. It's likely the unconscious computational models will eventually be tasked with communicating with similar models in other organisms, at which point the inscrutability will probably increase by an even greater amount.
It's going to be interesting when the corporations, talking with other corporations, manifestly decide that they don't need human components anymore. All of that can happen without the pesky need for consciousness, too.
You may have a point with the Trainer Central rebranding, but please consider this in the context of Italian language results. It’s not about reaching the home of the wiki (which is pretty much the only page that’s still indexed), it’s all the other search queries (Pokémon names, moves, games, etc - without adding “pokemon central” even) that usually returned our wiki’s dedicated page as first result (or top 5 at least) and now those specific pages are not even indexed anymore.
Any sources for this? AFAIK, Google treats websites on a subdomain as a separate entity.
> Things we believe you shouldn't focus on: As SEO has evolved, so have the ideas and practices (and at times, misconceptions) related to it. What was considered best practice or top priority in the past may no longer be relevant or effective due to the way search engines (and the internet) have developed over time.
> Subdomains versus subdirectories: From a business point of view, do whatever makes sense for your business. For example, it might be easier to manage the site if it's segmented by subdirectories, but other times it might make sense to partition topics into subdomains, depending on your site's topic or industry.
Doesn't quite explicitly say it treats them the same, but it kinda implies it.
“How can I contact your advisor?”
“Their name is <three part unique name>; just search for them and reach out.”
“Great. I found them and their results look impressive. I reached out and hope they get back to me soon.”
Thankfully bsky is not that good, so I don't get hooked by it at all. But i miss it
New User problem has been around for a minute though - wikipedia and stack overflow both faced it, as does every social media platform nowadays.
Reality is, though, new visitors are getting the same blast radius as early adopters got when they started, just that the early adopters now have blast radiuses that are much bigger
We know that people who are on our outer orbits should not be shared with in certain ways.
Our communities are in fact lots of overlapping bubbles, x knows y, and y knows z, but x sees them as a stranger.
The internet changes that dynamic, and we don't yet know how to manage it - we cannot all live in the town square, and we know to be very careful there, pickpockets, thieves, and robbers abound - and we have no idea who is who
Again our historical approach has been places like universities, where we have "trusted" advisors (teachers) who guide us on subjects being discussed openly - but who also ensure that we avoid pitfalls, like heated debates where people abandon logic and instead use rhetoric or violence, and who ensure that commercial interests are managed - that is, some advertisements are allowed, but unauthorised advertising is forbidden
That approach (moderation) has its own set of problems
It’s the best option we have, but it’s no solution to the crapshoot that is email today.
A guess: because you type queries in the URL bar, and they're the default search engine in your web browser?
(I'm convinced that these days, this is 90% of Google's advantage)
Image search is so hyper-optimised for shopping it's useless.
Lobste.rs has an invite based system however.
Because while your argument sounds nice, if you break out the numbers, it becomes largely meaningless. In fact you find that the average internet user, especially in the tech/gaming space, usually contributes nothing, while watching/loading no ads and self congratulates themselves for doing so while encouraging others to do the same.
So thank you, but you are one of about 14 people on the internet who actually use a whitelist.
Ublock origin et al can’t block those so there’s your solution. Don’t lazily monetize your content.
This is a much bigger issue than just podcasts. It's every form of binary encoded data.
I think this analogy is flawed. Corporations cannot exist without laws pertaining to them. They're made up of _laws_. The individual components all have actions dictated to them by these laws.
> If the owners stop receiving value the organism becomes unable to nourish its cells and it dies.
Owners are people. They're vulnerable to sentiment. There's plenty of failing businesses with their doors open for this reason.
You're attempting to rationalize something in biological terms that's somewhat irrational in logical terms.
> You're attempting to rationalize something in biological terms that's somewhat irrational in logical terms.
I'm mainly riffing for fun. I don't have any thesis, beyond just expressing a general unease for how much power corporations have to influence social discourse, laws, and public policy.
I'm using this as an excuse to play w/ the mental picture I've had for decades of corporations as Godzilla-like monsters roaming the social landscape predating, excreting, and generally smashing-up anything that displeases them while individual people look on in horror, mostly powerless.
Now that humans are bolting large computational models onto corporate governance and strategy we're entering an exciting new mecha-Godzilla realm where, likely, individual human accountability to corporate actions will be even less (though it's hard for me to believe that's possible).
re: rationality
Corporations are irrational because all the actors in the corporation, and those outside who are making the rules, are irrational.
Their irrationality, unpredictability, and adaptability to regulation, particularly when they're hulking daikaiju-like monstrosities shambling thru society wantonly smashing their tails into other institutions and social infrastructure (or mating with other entities to create super-monstrosities), is what's troubling to me.
> I think this analogy is flawed. Corporations cannot exist without laws pertaining to them. They're made up of _laws_. The individual components all have actions dictated to them by these laws.
The law is a component of the environment. The law binds the corporation together, but it also constrains and shapes how it can act. I don't see the human legal system, as it relates to corporations, a whole lot differently than the laws of physics controlling the chemistry that make biological cells work.
A big difference, though, is that corporations can allocate resources to get the law changed. They can alter their environment to suit their manifest desires. Many times they simply adapt to the law (changing business processes to achieve legal compliance). Sometimes they just act counter to the law, likely because some individual cells working in a reasoning capacity will have significant individual gain and very little individual risk (Dieselgate, or maybe the subprime crisis of 2008).
I'm particularly troubled by the Citizens United decision, in the US, because it gave corporations themselves the power of speech. I think they'd always been able to alter their environment through influencing their owners and constituent cells, but this ruling gave them very direct ability. To belabor the Godzilla analogy, we used to be able to call upon the government to battle these monsters when their destruction was too severe. Now the monsters have exciting mind-control powers that they can unleash upon the government (by way of spending on political issues).
> Owners are people. They're vulnerable to sentiment.
Some owners are people, and some of those people are vulnerable to sentiment. I don't put too much faith in individual owners to give much of a crap about what their pet corporations are doing (beyond returning value). A very small fraction of people are invested in individual corporations (and those who are invested individually in a significant manner are highly motivated to help their pet corporations adapt to or change the environment to maximize returns).
Individual people are participating in a different kind of inscrutable manifest organism (pension funds, ETFs, etc) and I don't think they think much about their ownership. Those people are, by and large, just looking at returns, if they're even doing that. I'd argue that kind of ownership by-proxy dilutes individual sentimentality to the point of making it very, very ineffectual.
There is a line we cross where the lowest quality, most bottom dollar crap is actually better than it's actively malicious "premium" counterparts.
It's like if a company spent billions of dollars creating the most perfect hammer that also happens to make itself bend to miss nails if you don't use the approved Hammertech GripGlove that plays ads and is slippery.
Or you could use a random rock with a flat side, which is a much better hammer than that in every way. In the exact same fashion, Yandex blows Google out of the water. Not because they have smarter people running it or because the code is more elegant or because they have more money. They just don't have the means or motivation to actively screw with you to the same degree as Google, and that makes it better.
Anyone at this point could make a better search engine than google just by running a basic text search algorithm and not doing anything else, it just so happens that Yandex never bothered to go as far beyond that as the mainstream ones.
Like if a video game is too expensive for your liking, you simply don't buy it. Going and pirating it is not a valid response. You get the game and creator gets nothing. You can just stick to playing honestly free games, there are plenty out there.
This idea that digital data is worthless is stupid child logic born from when kids ruled the internet. Obviously it has value, as evidence by the very top level post I responded to.
(Also, as an aside, it's only heavy ad-block/privacy tool users who get malware and scam ads, because they have no profile and only bottom feeders bid on their views. Regular users get Tide and Chevy ads.)
First of all, I can and will visit any website I want, and I will use an ad blocker while doing so. Second - how do you know what ads and privacy invasion a website might have before you visit it? Makes no sense.
> Like if a video game is too expensive for your liking, you simply don't buy it. Going and pirating it is not a valid response
In either case the creator gets zero $. It could be argued that pirating might actually benefit the creator more - since it would increase overall usage/adoption/prevalence of the product/game. So your argument is kinda backwards.
> This idea that digital data is worthless is stupid child logic born from when kids ruled the internet.
You keep mentioning 'kids' and 'teenagers' across your comments seemingly as a way to imply that you have some kind of greybeard wisdom and special knowledge. You don't and your arguments don't make sense - your own realization of that is probably what triggers you to call everyone who disagrees with your kids and teenagers LMAO.
And for the record - intellectual property is a made up scam, the only purpose of which is to stifle competition.
And so can LLMs, so I don't see why anyone should be upset about "stealing content"
>In either case the creator gets zero $. It could be argued that pirating might actually benefit the creator more - since it would increase overall usage/adoption/prevalence of the product/game. So your argument is kinda backwards.
So how do you decide (I'm asking you), who are the suckers who pay, and who are the ones that get it free? I say child a lot because it's really only kids who cannot see how a system like that plays out.
Just a heads up, with donation systems, typically ~1% of people convert to a donation.
In many cases running something like an online game requires server s/infra , and also requires an active subscription - not something you can generally get around.
Why would they pay for server infra or pay the devs? They should just be free to pay what they want or pay nothing at all. Not sure what the problem is.
People really hate it when you hold up a mirror to illustrate a problem. They tend to reflexively punch the mirror
So they can get content without compensating for it.
I've been on this train since the beginning. I was there when ad-block-plus read the writing on the wall 15 years ago and decided to make a truce with advertisers. It was clearly unsustainable for 50% of web users to be effectively parasites, so maybe we can negotiate on acceptable ad practices. But to the users, a truce with advertisers!?!? Ublock Origin was born days later.
Also - negotiating 'a truce with advertisers'? What does that even mean? Granting the ads industry even more power and control over the internet?
Can you come up with an idea that isn't a dystopian hellhole on its face?
Are you confused or being sarcastic?
I'll admit the system is one step larger than a typical transaction, which could be hard to understand for some, but the views -> ads -> dollars pipeline is the still straightforward to understand. Maybe not. I don't know when things get to complicated here.
Creators don't get compensation when LLMs scrape.
It's totally, and completely, unambiguous. The internet just has collective brain damage from the grassroots morals of it being formed 30 years ago by teenagers. How surprising that a bunch of kids decided that the way to save the internet was to make it better for themselves, and worse for the people who make the internet the thing they love.
Some of us have grown up now, and realize the correct answer to save the internet was to not engage with ad supported content period.
Adblocking is basic security now. I am not compromising on it. I say this as a “content creator”
Content creation comes in many forms. You can also promote things in your copy. People do it all the time. Adblockers aren’t going to somehow remove your words. People disclose their sponsorships at the top/bottom of their written content all the time and frequently use affiliate links.
Like if you are the VP of advertising for Procter & Gamble, and your nephews gmail account gets banned, are these guys treated so specially that they can get a white glove unban just like that? I wouldn't be surprised for Googles golden geese if they can
But on the other hand, I think they might definitely do that kind of thing as more of an old-boys-network type thing.
DDG often has scam sites for example when you search for FMHY, https://fmhy.net comes up on all other search engines, but fmhy [.] click comes up on DDG.
Same with "anna's archive" returning the fake site annas-archive [.]io.
I've been a ddg user full time for 15+ years and I did see it improve quite lot over time. But quality dropped when Yandex was cut off.
Lately, I've noticed YET AGAIN being trapped in a bubble with results being to clever for their own good ... I did leave Google PRECISELY for the bubble effect ...
Not even mentioned the AI shenanigans with ridiculous results at times. DDG is not immune to enshitification. Way too many managers thinks they know better than the user ... they don't.
I know what you mean though, I use it but it’s never quite right. Hard to say exactly why.
I wonder if it's a regional thing.
I use Bing at work for no other reason than sheer laziness, really. You've inspired me to return to DDG.
Keep on keepin on, yegg.
Here is the list of all the official sites for FMHY (https://fmhy.net/other/backups)
I'm sure they would be happy with any combination of these 3.
1. fmhy.net
2. reddit.com/r/freemediaheckyeah
3. github.com/fmhy/FMHY
As for Anna's, it changes often, but it would be good to only allow the ones listed on the Wikipedia for sites that are posing to actually be Anna's Archive, rather than accessory sites like Github, link directories.
https://en.wikipedia.org/wiki/Anna%27s_Archive#:~:text=URL,a...
annas-archive.pk
annas-archive.gd
annas-archive.gl
"scientology speedrun instagram"
Brave returns mostly news articles in the main results and only a specific Instagram reel. Brave has an area for videos which is particularly relevant, but DDG has a carousel thing for news. DDG returns an Instagram and Tiktok area for the topic and an X account. Then Wikipedia and Knowyourmeme.
I would say DDG actually wins here because it is very much more on topic with the social media sites being resulted (X, IG, TikTok), but the results feel less clickable to me because those social media sites are so unfriendly to adblocking, VPN using, not-signed-in users.
"fisa news"
Brave shows a really nice variety of specific news article updates as well as primary sources like a .gov. DDG does similarly, but it's really only news and it is really a smattering of different mainstream news websites. That's fine, but then there's also that carosel which is 100% filled with Yahoo and Foxnews, which I consider both to be low-quality.
Another big problem with DDG in this specific search is there are quite a few simple links to news website's tag on fisa, which isn't helpful to me.
I'm not the happiest about either results, but Brave wins because of the lack of slop from yahoo as well as the primary source results.
who is the highest level scientologist who left
Neither DDG nor Brave returns any immediate actual answers in websites, but by automatically returning the AI summary, I get a satisfying answer from Brave's AI.
"sovereignty"
I was surprised, but DDG totally wins this one. Brave doesn't have that built in dictionary result, DDG does. Brave also has a news carosel which is not relevant. Pretty comparable with the other results, but definitely a win for DDG.
Actually, what's the deal with putting the "search assist" at the bottom. That's pretty weird.
I think a lot of my bias against DDG comes from the UI. Brave seems friendlier, rounder, easier to read.
Hopefully this helps.
On the Assist question, it can appear at the bottom when we think it has a good answer but something else beats it. Curious what was weird about it? Just not expecting another answer?
{kind=link}