Unit is a general purpose visual programming system(unit.software) |
Unit is a general purpose visual programming system(unit.software) |
Beyond some specific use cases, they don't seem to scale cognitively. The tangle of connections is a problem. The previous HN link from @andsoltis has a better critique than me.
Don't get me wrong. Besides being experientially cynical about these things, I'm also firmly in the camp of "one more UI breakthrough, bro and we might crack it!"
This one has some deep design that definitely attempts to extend the state of the art but still struggles with that aforementioned problem.
TBH though, the coolest feature is that widget that focuses on what you are doing. There is something there with it, I'm just not sure what the "there" or "it" is, but I do know I like it.
I'd love it if someone found a solution to that, but it feels like an intractable problem beyond some specific use cases as you say.
I really hope I'm wrong.
Support for embedding such things in another language (Like we do with SQL and regular expressions) would be important, too.
That might be a place to start. Can we replace regular expressions with a visual language? What would it take to have “railroad diagrams” widely available in at least one programming language and many editors?
I grant that this makes the project significantly larger if you're going to remove that constraint.
Advantages are:
- discoverability --- it seems pretty easy to arrange all elements in a hierarchy and make them accessible via clicking/revealing
- no syntax errors --- if things fit together/connect, then it should be a syntactically valid program
The problem is, it relies on a couple of concepts we don't seem to have a good solution for:
- What does an algorithm look like?
- How to deal with an algorithm which is larger than the current screen/window size? (it's all-too easy to have the same sort of problem of a not-wrapped program with lines longer than the current window size and more lines than will fit in a window, and there doesn't seem to be a 2D graphical equivalent of turning on word-wrapping)
- If programs are broken down into discrete modules, then connected together, one is back to the wall-of-text description which presumably one was trying to escape from, just wrapped up in boxes and connectors
Two pages with cautionary images are:
https://blueprintsfromhell.tumblr.com/
and
https://scriptsofanotherdimension.tumblr.com/
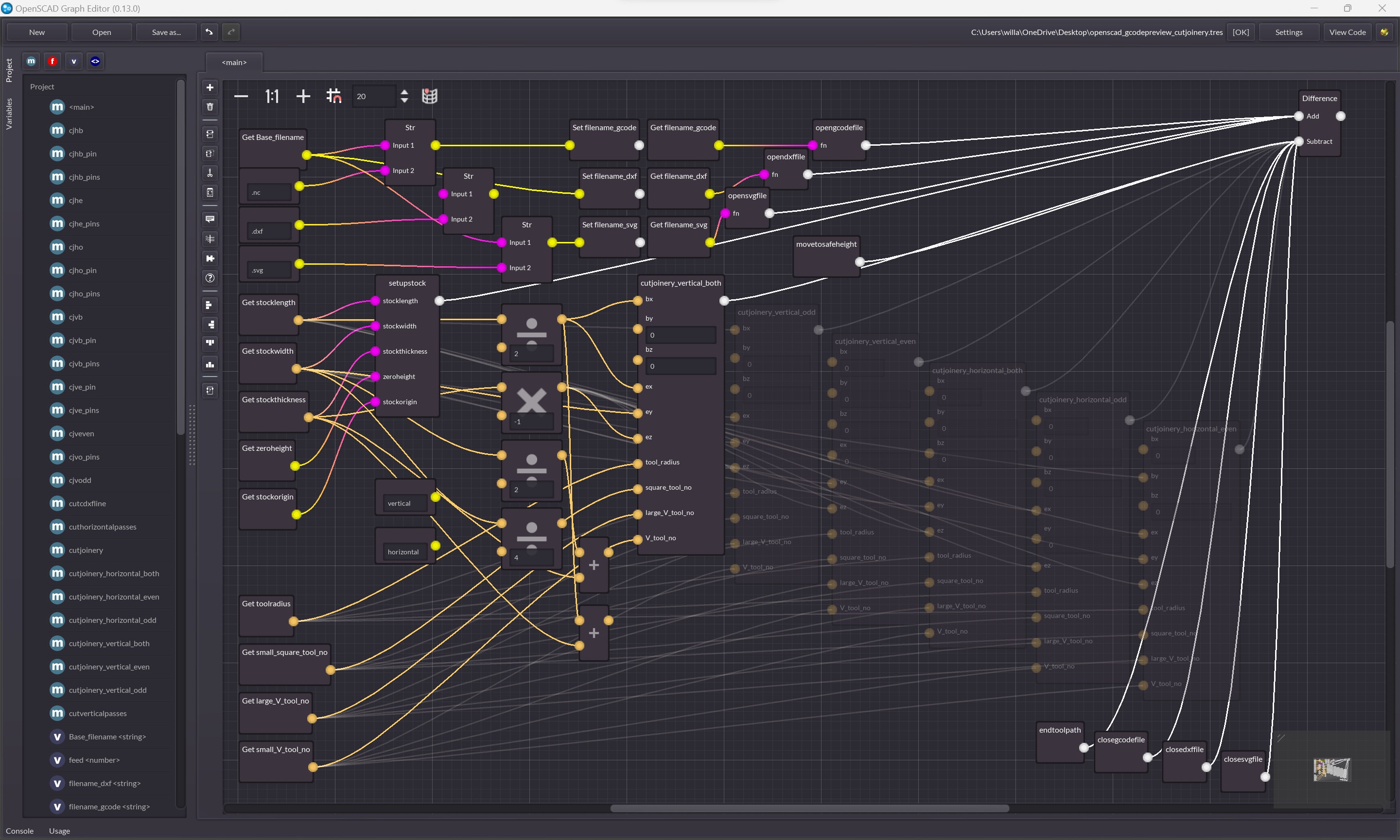
I've been trying to use OpenSCAD Graph Editor: https://github.com/derkork/openscad-graph-editor in my own work:
https://github.com/WillAdams/gcodepreview
and the screen grab from there sums up the difficulties pretty well:
https://raw.githubusercontent.com/WillAdams/gcodepreview/mai...
Even in text, you don't try and look at everything at once, zooming out for a "structure overview" seems useful, but that is not what is happening here, its just imperative code being shoehorned into a DAG and left wherever a user left it instead of organizing itself, which is the whole benefit to graphical programming.
This demo of "unit" at least seems to organize nodes and views of nodes better.
for consideration, one need not change the encoding medium to achieve this: JetBrains MPS <https://www.jetbrains.com/mps/#:~:text=Why%20MPS> (Apache 2 licensed: https://github.com/JetBrains/MPS ) is like a middle ground between "flashing cursor in a textarea" and "drag-and-drop programming" and they alleged to have written their bugtracker (YouTrack) using MPS but they have since removed the citation in the footer so I don't know if it was true or is true
I can sling text with my eyes closed, and have managed the ergonomics of typing well enough that it hasn't injured me in almost 50 years.
On the other hand for applications where dataflow was a good paradigm for the problem being solved, I appreciated its benefits.
This just isn't true. I've actually built things in visual languages. It just requires the same organization as text-based languages. One could write an entire text-based program in a single file in a single function, which would be a similar mess. In fact, the benefit or feature of visual languages is that they showcase poor code more readily than text-based code.
Tons of things like this were built in Smalltalk. (Including a UI->Domain model connection layer in the IBM VisualAge Smalltalk IDE.) They all had scaling problems, especially, "they don't seem to scale cognitively."
It's not as if the problem doesn't exist in most codebases. It's more that the problem is invisible without such tools. Tools making the tangle visible make themselves seem unusable.
The fundamental problem, is that we don't have ways of introspecting these horrendous relationship graphs for specific contexts. If IDEs and other programming tools generally could create custom browsers/IDE windows for things based in queries like:
"All of the methods that contain references to ClassA.Member1 and ClassB.Member2 which also call function Y."
...where this query can be modified or further specified at runtime. Then there could be specific built in queries that cover everything touched by canned refactorings. Then these further could be intersected or unioned.
EDIT: Forgot to complete my thought. If the graphical diagram could show contextually relevant slices of the system, it would greatly cut down the confusing web aspect of the diagrams.
Anyway, I used Unit as an excuse to play with OBS and stream a bit... if you'd like to see a video of how I figured out some bits about how it worked since I couldn't find anything close to a tutorial I have a video on YouTube:
Related: A personal history of visual programming environments (Dec 2022); 27 comments https://news.ycombinator.com/item?id=34094223
This readme gives a much better idea of how it works: https://github.com/samuelmtimbo/unit/blob/main/src/docs/star...
Example: https://github.com/leofds/iot-ladder-editor Fiddle: https://www.plcfiddle.com/
Real world: Siemens SIMATIC for S7 PLCs (this lets you interchange between an Assembly-like language and the visual Ladder logic): https://cache.industry.siemens.com/dl/files/395/18654395/att...
https://x.com/io_sammt/status/1792251421154316516?t=Glk0hVvo...
Also it was clearly a solution in search of a problem. I was a believer in the idea that graph databases would enable a new paradigm of application development in the way that relational databases did, and wanted to try to pioneer something. That was (so I thought) what college dropouts like myself in my early 20s needed to do to get ahead in tech, as I was only a mere data analyst at the time, with no connections to the tech industry, scraping by while living inside a garage.
It was a good exercise though and it somehow out of sheer luck caught the attention of Manning Publications as it likely came up in the search results for OrientDB. My project page included a sort of roadmap to integrate with OrientDB.
They signed me on as a co-author of the book OrientDB in Action as the other author(s) IIRC weren’t native English speakers and they needed one. The book was never released but a different author released a similar book without publisher backing which was good enough for OrientDB.
If a publisher ever approaches you to help write a book, no matter how ridiculous of a candidate you think you are, your initial response should always be yes. You don’t have any obligation to actually finish a book unless it’s in the contract. You won’t make a dime but you’ll get world-class training on writing technical documentation. They only required that I complete a draft of one chapter within a shorter timespan for the first phase.
https://code.google.com/archive/p/nuzzgraph/wikis
https://code.google.com/archive/p/nuzzgraph/wikis/NuzzGraphB...
I've probably mentioned this a few times on here, but Prograph was a GREAT example of a visual language, that solved a LOT of issues (spaghetti code) etc. It's worth a look if you're interested in visual programming
* object oriented * scrunching of code - tha could be turned into functions (local-to-opers) * you could edit code and values whilst it was running * FAST!
Here's an ole video of some server software I made, that at the end shows me rustily doing some Prographing.
https://youtu.be/MtECJw59elc?si=svRbd5_IA4cAFhVa&t=1429
p.s A free version of Prograph (Marten) used to exist, but when the genius creator died, the project, sort of lost its way too.
> Added `If`
Uh, that's a pretty weird thing to add in a second release
Box and noodles can be more descriptive and interactive for some parts of a system but probably not for all parts of a system. Configurations for parts of applications can be better in a GUI than a yaml file. Embedding one language like SQL in another could have an integrated GUI subeditor complete with language server.
1) So a user creates a couple of nodes in a graph: a button, his specific hardware, a text node saying he wants to calcuate clicks per day.
2) This graph is then used to find published graphs by people who have used these nodes in a completed/deployed instance.
3) The user can easily browse and pick an exact complete graph to deploy himself. (layers here such as preventing private wifi passwords from getting to the published graphs)
4) If the graph is complete in terms of pointing to his exact hardware, exact code chunks as nodes, exact sdk versions then it transforms this graph into typical source code, and can be compiled and deployed, and after confirming it works, then shared again to the public graph collection to let others know it works.
5) if the graph isn't complete, you might have to write some code chunk nodes, connect things properly, or else use AI (har har) or even mark nodes as "todo: can someone please implement this code, or pledges/bounties for someone to help implement"
6) People need to be able to jump into any level they are comfortable with, the code, the graph shape, the public list of TODOs. Then there is translation/generation into the other levels. This makes a tool for higher level collaboration, that should be able to converge on finishing off desired solutions.
The whole point being a new level of abstraction that makes code reuse possible if someone has implemented the same thing in the past already. (but even if it was on different hardware/sdk there should be reusable stateless functional-style code that can be stitched together a bit easier)
I really want to love it, please give me a strong reason.
One of the really nice things in Literate Programming
http://literateprogramming.com/
is that one gets a nicely typeset PDF which has a hyperlinked ToC which does serve as a "structure overview": https://github.com/WillAdams/gcodepreview/blob/main/gcodepre...
I agree, some facility for automatic re-organization and adjusting what is shown/readable in terms of hierarchy based on how much or little of the program is being shown would help a lot.
I have used LabVIEW, among other visual languages, and built systems with 1,000+ VIs, which are the fundamental building blocks of code organization, and hundreds of classes. LabVIEW has VIs, clusters, classes, libraries, and projects, all of which are useful and required for a well-managed, decoupled code system.
With good software principles, there's nothing that says you can't organize and scale visual code well.
I one time interviewed at a place that had swore off LabVIEW and were moving to Python. The reasons of switching from LabVIEW were the same tired reasons of organizational issues. When I asked to see their Python code, they showed me a single Python file over 10,000 lines long, and there were function signatures that were over 20 lines long. That was just the function signatures. This example, along with many more, and my experience in both visual languages and text-based languages make me very skeptical about claims about not being able to organize and scale code in visual languages.
We see the tangle representing a complex system and say the tangle is ugly. We hide the tangle in text and names and say it is better. There is something odd there.
That the tangle is perceived to be uglier than the word.... is it that our brains deal better with a sliding window of symbols rather than gazing upon the sprawled true tentacled glory of some large algorithmic expression?
The promise of VP is that the program is the architecture is the monitoring tools.
Should we learn to love the sprawl?
So, I'm making two parallel attempts at this again. One more serious ( https://youtu.be/sqvHjXfbI8o?si=-PDXQes5i4JglBQj&t=411 ) and one as a game/exploration.
The first will be for tiny machine-generated programs linked together, which will be for a research project. The second is for an abstract physics game which will be for learning, fun, and hopefully some tiny profit on Steam. (Will appear here https://store.steampowered.com/search/?publisher=My64K when playable)
In, both I am adding severe constraints to the VP design but the game one will be the most interesting. I'm looking to add a kind of cellular automata mediated physics that also provides gradual automated optimization. Think programming in Minecraft with Redstone but with multiple dimensions and a regular polygon substrate. The key ideas I am exploring in both are:
1) Can we design a substrate that enforces some order that solves the tangle problem?
2) Within a substrate, can an algorithm be "crystalized" or "folded" into something recognisable by its shape?
I am starting next week. I have six months off work. It should be fun.
Consider how hard it is to even get people to use additional symbols, like the APL's do...
Along with markdown, there’s also increasing support for math equations in forums and blogging software.
Math symbols are a better example, but also extremely well established, and it's still taken a very long time to get widespread support, and it's still far from universal.
But note that non-ASCII symbols etc. was an example of the difficulty of even getting support for something "that simple". Now try to take the step up to e.g a node-based editor.
Open up the source code for this web page: is it compact and readable? The answer seems to be that HTML is "good enough" in that regard, and I suspect CSTML will be the same especially as more developer tooling for it becomes available.
To take your example, pretty much anything longer than [1, true, "3"] is a non-starter if someone is pasting it into Slack, or sending an e-mail. The CSTML representation isn't readable to them, and would take additional steps on both sides vs. just writing the source representation. I'm not going to tell people how to do something by writing it into some other tool and pasting some large blob into Slack or my e-mail client and expect the recipient to reverse the process.
That is the problem space. How you represent that as an AST isn't the problem - that's easy. How you represent it in a way that everyone can read and write and that "passes seamlessly" via existing tools is the problem.
(I must also admit that I think the choice of serialization format for CSTML is utterly baffling and feels like it adds a lot of NIH)
In practice every attempt I've looked at either become hard to communicate about the code in, or the visual aspect tends to end up just becoming a secondary visualisation of code that you still treat as textual first.
In the latter case, turning it into a better UI is an unsolved problem, because round tripping reliably between something readable as text and a meaningful visual representation is really hard.
As I said, I hope someone solves this, but most attempts aren't even pushing the boundaries into uncharted territory - a lot of attempts have been made over the years.
https://youtu.be/70PH5cQQEdQ?si=y4YmhnimzferVpCD
Since you develop inside vr you can also talk about and show the code in the same vr environment.
It's probably at this level we need to rethink stuff to make visual programming practical.
This also makes it easier to verify that you have all the same capabilities in both representations, as the ways of manipulating the AST are enumerable.
I built a language and UI around that way back, and many others have. I ditched mine because there were way too many unsolved problems I felt made it useless.
The problem is that if your primary means of working with the code is visual, the textual representation of your code then tends to be foreign to you when you're trying to use it to communicate aspects of the code, and when you constrain yourself to something that can be represented in a readable manner in a textual form, it turns out to be really hard to get to a point where the visual form is easier to work with.
E.g. something as basic as how you comment code in ways that roundtrips nicely is an unsolved problem.
If I have code represented as a graph, I'd be inclined to want to label relationships and dataflows that would be hard to place textually in a way that is meaningful in a textual version and that would roundtrip back to labels in the right place in the visual version.
I've not seen any attempts at visual code that gets even that right.
I've not managed to get it right myself either. If you force users to use an editor built into this tool, and edit a textual representation where some information is hidden, you can do better, but then if people e.g. copy a textual representation of the code into another application and back in, you end up with a mess.
Again, I want to be proven wrong about this. Badly. I love the idea. I've just seen enough failed attempts (and made enough failed attempts) to be disillusioned about it.
Try copy and pasting some HTML-formatted text from this page into your paste buffer.
I assure you that what goes into the buffer is HTML. You can verify this because if you paste the text into an HTML-embedding WYSIWYG editor (such as an HTML email composer) the formatting will be preserved. But if you paste the content of the same HTML buffer into VSCode, notice that you don't get the raw HTML but rather the textual content that was embedded in that HTML.
Now try doing the same with CSTML, in applications that so support HTML.
Now consider how little that markup contributed to the semantics of the text here - most of it can be stripped and the text retains it's meaning.
Then consider how long it took for HTML to percolate through these applications despite HTML - unlike CSTML- having universal utility.
And here's the thing: As someone with a history of writing compilers, parsers, language tools over 30+ years, CSTML is too verbose for me to want to use even for tooling. It's way too low level even as an internal representation for tooling.
It also still doesn't help: You still will need a compact textual representation anyway so people can represent it in contexts where the tooling doesn't exist, or can't exist, such as paper and handwriting, and speech.
All I can do is encourage you to try. If you succeed, great, and if not you will understand the difficulties involved.
I've tried the custom syntax representation (though I used XML which saved me from writing a custom parser) - it turned out to just be an obnoxious detour. I tried syntax aimed at removing ambiguity in round-trips, and it sort of worked but got too verbose. I tried a purely visual approach, and hence why I'm so insistent you need to be able to roundtrip to text. I spent years trying things and looking at others attempts.
I'd love to be wrong, but I very much don't expect any big breakthroughs in this area in decades - the attempts I keep seeing keep repeating all the same mistakes with few signs of lessons learned.
You could for example explain every node verbally and visually to an AI bot that can then explain it to the next person, or selectively retrieve parts of your explanations on demand. (OK, I realize that sounds unnecessary complex.)
E.g this is a real line of code:
link = wf["links"].find{ _1["rel"] == "self" && _1["type"] == "application/activity+json" }
Once you've solved Slack - maybe with a plugin -, you need to solve all our e-mail clients, and you need to solve Google Docs and Word for when we write documentation, and a multitude of other tools.
You might be able to get part of the way there with a browser plugin, but you'll still have a wide variety of other tools and platforms to cover.
I think you're right that the end game of any successful attempt at standardization is integration with all those tools like Outlook, Slack, Discord, Signal, Word, Docs, Notion... The list goes on and on. It's strange how the presence or absence of political momentum behind a standard could change that from being "basically impossible" to "basically inevitable"
Commenting needs to be solved at the language level, and there are many languages that have solved this exact problem. Python, newLISP, and Smalltalk IIRC all have methods for docstring commenting APIs such that the docstring is available as text to the running program / REPL. Use similar syntax to allow any statement to have comments attached, and use this instead of free-form /* */ comments.
How would I communicate about the project to others in e-mails, instant messenger, face to face, in blog posts, in articles, in books?
How would I review diffs of code changes effectively?
That is why.
Find me a representation I can talk about and write about efficiently without screenshots or videos or requiring special software of every recipient on every platform, and you'll have advanced the state of the art in this field immensely.
> that have solved this exact problem
None of the ones you described have solved the problem of mapping between a visual and textual representation of the program seamlessly. Just attaching the comments from a textual version to an AST of the textual version is trivial. That's not the challenge.
> Use similar syntax to allow any statement to have comments attached, and use this instead of free-form /* / comments.
That doesn't get close to solving the issue. When I have a diagram showing the data flow of a piece of code, and I attach a comment to the edge* between the two nodes, in the textual representation where does that comment go? Does it go in the text version of the source node? In the destination node? What if I write a comment in the textual version right before a method call, and then switch to the visual version, does that stay in the source node? Does it become a label of the edge representing the method call? There are tons of edge cases there.
The problem isn't finding a way to attach the comments in the right place, but finding a way that roundtrips perfectly without adding noise in either representation.
I've not used a visual programming language and unit is (currently) hugged to death. But, my experience with graphviz's dot syntax would suggest putting a comment on the (textual) line that represents the edge itself:
digraph whatever {
running [ shape = "triangle" label = "program running" ]; # comment on the node itself
stopped;
running -> stopped; # comment about the edge
stopped -> running;
}
(Also, I'm disappointed that I need to resist the urge to talk about Bob Nystom's visual pdf diff, because it seems really cool but is not as credible as the edge directive above. https://journal.stuffwithstuff.com/2021/07/29/640-pages-in-1... , scroll to 3/4 where it says "Here is what all of the proofreading changes look like:")
On the contrary you will find that throughout this thread my biggest issue with visual programming is the reverse:
That a textual syntax that maps cleanly to the visual representation is an absolute necessity.
The problem is no visual programming system has included such a system. They've either been only visual, or they've been visual representations of programs written in classical programming languages.
Nobody has come up with, e.g. a language designed specifically to facilitate new visual programming capabilities without losing the ability to cleanly roundtrip to text.
I tried and gave up. Maybe I'll revisit it again in retirement, but I really hope someone beats me to it and finds something that works.
I think that might well be one of those restricted situations where visual programming often works well enough that it seems some use. I'm absolutely not saying it can't ever work.
My problem with it is more when you try to do more general-purpose things with it, and you e.g. either end up with a node per method/function call (and maybe then even nodes for argument expressions) or large, complex nodes with internal logic.
I love dot for graphs, but the challenge to me with that approach is that I've not seen a convincing example where you'd then not end up with a mountain of text for even very simple things (and I've sinned badly there myself - one of my own early attempts serialised to XML...) when you decompose the text enough that you can augment it reliably.
E.g. consider a complex expression where that edge is not just a simple state transition, but a method call with arguments, where each argument itself might be a complex expression...
Every attempt I made myself ended up with a textual version that was too verbose to feel viable for communication about the code unless I stripped out so much that the visual tooling effectively became a tool to analyse the textual version, rather than allowing editing on equal footing.
It's possible for a visual programming system to work without it, but it will need to be accordingly a far bigger step up.
Consider searchability on e.g. Stack overflow for example. If people don't have a consistent, shared vocabulary, just lack of searchable exposure is likely to forever condemning it to a niche.
>likely to forever condemning it to a niche.
The context within which we build visual programming languages needs to change in order for it to stop being a niche. As you point out, the alternative is [much] harder [today]. But I think that VR, as an example, will be forced to solve a lot of difficult UX problems if VR is to progress beyond a niche. And once those problems have found satisfying solutions the context for building nice visual programming languages will likely also have improved significantly.
(EDIT: And specifically to the sentence you cut that out from: For it to appear in search results, and so be discoverable* it still needs to be in a form that search engines know how to index)
There's nothing technically preventing us from having all our software allowing the embedding of visual code elements that can be manipulated via components - the technology to do that is decades old.
The problem is a combination of social, inertia, and the chicken and egg problem of there not being any sufficiently compelling visual programming system creating a significant reason to push for this.
I don't want to discourage people from trying. By all means, try - I'd love to be proven wrong, and I think you might very well discover something useful or learn worthwhile lessons from trying to push the limits of this. There are just lots of pitfalls to address.
{kind=link}